【51CTO.com快译】所谓分布式系统,指的是一组通过发送消息实现协作、从而共同达成同一目标的资源集合。正如知名计算机科学家Leslie Lamport所指出之定义:“所谓分布式系统,其中任意一台计算设备——即使使用者并未直接使用甚至对其存在毫不知情——出现故障,亦会影响到其它设备的正常运作。”
而这条定义也恰恰概括了我们在分布式系统当中经常遇到的一类问题。事实上,在云计算时代之下,资源的汇聚已经成为满足负载对于计算及存储实际需求的一种必然手段。这类系统的特点在于包含大量需要管理的资源,而其中故障的出现频率与整体规模则成正比关系。
在分布式系统当中,故障属于一类常规事态,而非意外状况——这意味着我们必须时刻做好心理准备。有鉴于此,相关社区专门创建出专门的工具,旨在帮助开发人员应对这方面问题,而Apache ZooKeeper正是其中之一。
ZooKeeper是一款极具实用性、现场测试能力并拥有广泛用户群体的中间件,专门用于构建分布式应用程序。在OpenStack当中,ZooKeeper也成为Nova ServiceGroup API后端中的组成部分。最近,ZooKeeper还与Ceilometer相集成,从而为Central Agent带来更为理想的高可用性水平——当然,这方面话题我们以后将另行讨论。
我们为什么需要ZooKeeper?
一般来讲,当大家设计一款分布式应用程序时,常常会发现需要将各类流程加以协同才能执行预期任务。在大多数情况下,这种协作关系依赖于最基本的分布式协作机制。
Heat是一款OpenStack编排程序。大家可以利用它创建出一系列云资源,而这类资源会由一个模板文件负责指定,这就是堆栈的概念。Heat允许用户对堆栈进行更新,但更新过程必须以原子方式进行,否则可能会导致资源复制或者相关性破坏等冲突。这类问题在并发更新场景下非常常见,而为了解决此类问题,Heat会在对堆栈进行更新之前首先设置一套所谓分布式互斥锁。
在这类原型基础之上进行开发是项极为困难的工作,而且经常带来令人头痛的麻烦。事实上,在分布式系统当中反复出现的这些问题早已成为技术圈中的共识。为了简化开发人员的日常工作,雅虎实验室创造出了Apache ZooKeeper项目,旨在为这些协作因素提供一套集中式API。归功于ZooKeeper的帮助,现在我们已经能够轻松实现多种不同协议,包括分布式锁、屏障以及队列等等。
ZooKeeper应用程序的架构与优势
一款ZooKeeper应用程序由一台或者多台ZK服务器支撑而成,我们可以将其称为一个“集合”,在应用程序端则为一组ZK客户端。
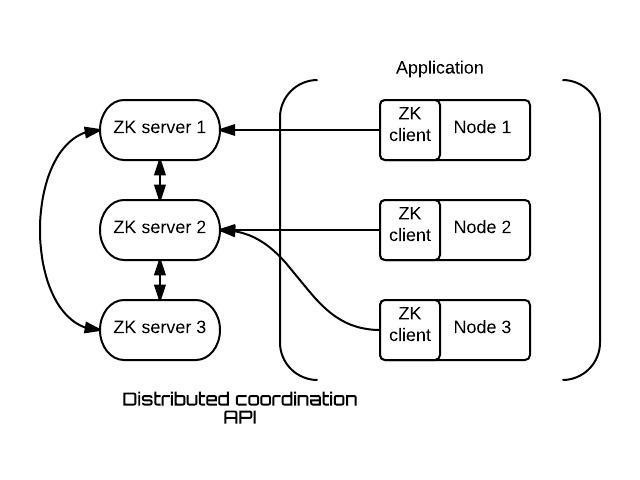
其设计思路在于,该分布式应用程序的每一个节点都通过使用一个ZK客户端在应用层级使用相关API,这意味着应用的运行将依赖于ZooKeeper服务器实现。
这种架构方案拥有以下几项突出优势:
- 我们可以立足于应用层提取大部分分布式同步负载,从而实现一套所谓KISS(即Keep It Simple, Stupid,保持一切简单且具傻瓜式特性)架构。
- 常见的各类分布式协作元能够实现开箱即用,因此开发人员无需再自行对其加以处理。
- 开发人员不需要处理服务故障等状况,因为整套体系拥有出色的弹性。ZooKeeper以应用程序神经中心的姿态存在,因为它负责控制整个协作机制,因此众多组件都需要依附于它以实现作用。出于这些理由,ZooKeeper在设计中引入了出色的分布式算法,从而提供开发人员所需要的高可靠性与可用性保障。一个ZooKeeper集合基于群体形式存在,且通常由三到五台服务器构成。
ZooKeeper集合能够在多种场景之下发挥作用,下面让我们从实践角度出发一同来了解。
实践场景中的ZooKeeper
ZooKeeper的API非常简单而且直观,其数据模型基于以内存树形式存储的分层命名空间。该树中的各项元素被称为znode,以文件形式容纳数据并能够如目录一般拥有子znode。
首先,大家需要确保自己的运行环境满足系统配置要求,接下来我们就要着手部署一台ZK服务器了:
- $ wget http://apache.crihan.fr/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
- $ tar xzf zookeeper-3.4.6.tar.gz
- $ cd zookeeper-3.4.6
- $ cp conf/zoo_sample.cfg conf/zoo.cfg
- $ ./bin/zkServer.sh start
现在ZooKeeper服务器已经能够以独立模式运行了,且会在默认情况下监听127.0.0.1:2181。如果大家需要部署一整套服务器集合,则可以点击此处阅读其相关管理指南。
ZooKeeper命令行界面
我们可以利用ZooKeeper命令行界面(./bin/zkCli.sh)完成一些基础性操作。其使用方式与shell控制台非常相似,操作感受也与文件系统相当接近。
下面列出root znode“/”中的全部子znode:
- [zk: localhost:2181(CONNECTED) 0] ls /
- [zookeeper]
创建一个路径为“/myZnode”的znode,其相关数据则为“myData”:
- [zk: localhost:2181(CONNECTED) 1] create /myZnode myData
- Created /myZnode
- [zk: localhost:2181(CONNECTED) 2] ls /
- [myZnode, zookeeper]
删除一个znode:
- [zk: localhost:2181(CONNECTED) 3] delete /myZnode
大家可以输入“help”命令来查看更多操作命令。在本次示例当中,我们将使用应用程序编程接口(简称API)来编写一款分布式应用程序。
Python ZooKeeper API
我们的这套ZooKeeper服务器是由Java编程语言构建而成,且绑定了多种由不同语言编写而成的客户端集合。在今天的文章中,我们将通过Kazzo这一Python捆绑客户端来了解该API。
我们可以在虚拟环境下轻松完成Kazoo的安装工作:
- $ pip install kazoo
首先,我们需要接入一个ZooKeeper集合:
- from kazoo import client as kz_client
- my_client = kz_client.KazooClient(hosts='127.0.0.1:2181')
- def my_listener(state):
- if state == kz_client.KazooState.CONNECTED:
- print("Client connected !")
- my_client.add_listener(my_listener)
- my_client.start(timeout=5)
在以上代码当中,我们利用KazooClient类创建了一个ZK客户端。其中的“hosts”参数负责定义该ZK服务器地址,并以逗号加以分隔,因此如果某台服务器出现故障,那么该客户端将自动尝试接入其它服务器。
Kazoo能够在连接状态出现变化时向我们发出通知,根据当前具体状况,这项功能可以非常实用地触发我们预设的各类操作。举例来说,当连接无法顺利建立时,该客户端应当停止发送命令,而这正是add_listener()方法的作用所在。
而start()方法则能够在确认会话创建完毕之后,在客户端与一台ZK服务器之间建立起连接。每台服务器都会追踪每个客户端中的一项会话,这种特性在实际分布式协作元方面起到非常重要的基础性作用。
#p#
对znode进行增删改查
与znode进行交互同样非常简单:
- # create a znode with data
- my_client.create(“/my_parent_znode”)
- my_client.create(“/my_parent_znode/child_1”, “child_data_1”)
- my_client.create(“/my_parent_znode/child_2”, “child_data_2”)
- # get the children of a znode
- my_client.get_children(“/my_parent_znode”)
- # get the data of a znode
- my_client.get(“/my_parent_znode/child_1”)
- # update a znode
- my_client.set(“/my_parent_znode/child_1”, b"child_new_data_1")
- # delete a znode
- my_client.delete(“/my_parent_znode/child_1”)
其中set()方法会接受一条version参数,而后者则允许我们执行类似于CAS的操作,如此一来即保证了任何使用者都无法在不读取最新版本的前提下进行数据更新。
有时候,大家可能希望确保某个znode名称独一无二。我们可以通过使用连续znode(即sequential znode)的方式实现这项目标,相当于告知服务器在每段路径的结尾添加一个单递增计数器。
在这一点上,ZooKeeper的运作方式类似于一套普通的数据库,不过更有趣的特性还在后面。
观察者
观察者机制可以算是ZooKeeper的核心功能之一,我们可以利用它对znode事件进行通知。换句话来说,每个客户端都能够订阅某个指定znode的事件,并在其状态发生变化时得到通知。要获取这类通知,该客户端必须注册一项回调方法——该方法在特定事件发生时即被调用(通过后台线程)。感兴趣的朋友可以点击此处查看ZooKeeper所支持的各不同事件类型(英文原文)。
下面来看一段示例代码,我们可以在某znode的子集发生变更时触发通知机制:
- def my_func(event):
- # check to see what the children are now
- # Set a watcher on "/my_parent_znode", call my_func() when its children change
- children = zk.get_children("/my_parent_znode", watch=my_func)
值得指出的是,一旦执行了回调,客户端就必须对其进行重置以保证下次事件发生时能够再次正常获取通知。
临时性znode
正如之前所提到,当客户端与服务器相对接时,会建立一个会话。该会话会始终保持开启,负责向服务器发送心跳消息。而在经过一段时间的闲置之后,如果服务器端没有监听到来自客户端的更多活动,则该会话即被关闭。由于该会话的存在,服务器才能够判断目标客户端是否仍处于活动状态。
临时性znode与正常znode没有什么本质区别,最大的不同在于前者会在该会话过期时被服务器所自动释放。
如果将观察者与临时性znode相结合,我们就能够实现ZooKeeper的一项杀手级特性。事实上,这类特性可以说为我们的分布式协作元实现工作带来了数量庞大的可能性。下面我们就一起来看看分布锁机制。
分布锁
分布锁应该算是分布式应用程序当中出镜频率最高的机制了,这是因为我们会经常需要以互斥的方式访问某些资源。
在ZooKeeper当中,这项任务可以说非常轻松:
- my_lock = my_client.Lock("/lockpath", "my-identifier")
- with lock: # blocks waiting for lock acquisition
- # do something with the lock
其涉及的API与本地锁完全一样,但引擎之下到底发生了什么?要找到问题的答案,我们首先来聊聊分布式算法的设计方式。
任何一种分布式算法都必须满足两项特性:安全性与活性。
其中安全性确保了该算法绝对不会偏离自己的目标,而对于分布乐来说,这意味着只有一个节点能够获得该锁。从直观角度讲,同一时段内不可能有两个节点同时拥有分布锁。
而活性则确保了该算法的持续递进,在分布锁这一场景当中,这意味着如果某个节点尝试获取该锁、那么最终一定能够获取到。
以本地方式实现锁机制属于众所周知的难题,而且有大量专门作为解决方案的算法出现——例如Dekker算法,而且每一种现代编程语言都会将其囊括在标准库当中。不过需要强调的是,在分布式环境下这个问题会变得更加复杂。这两大特性之所以难于实现,是因为各个节点随时可能出现故障,而这势必造成大量可能出现的故障场景。
ZooKeeper ensures these properties for us:则能够帮助我们确保这两大特性:
- 活性的保障:将多个临时性znode加以结合以检测故障节点,而观察者机制则负责向其它节点发出通知。因此,如果某个节点获得了分布锁并出现故障,那么其它节点将立即识别到这一状况。
- 安全性的保障:利用连续znode以确保各节点皆拥有彼此独立的命名,这样只有一个节点会获得分布锁。
我强烈建议大家点击此处查看分布锁说明文档,其中提到了Kazoo的多种实现方式。
总结陈词
构建一款分布式应用程序往往会成为一场令人头痛的噩梦,因为我们必须要预料到一切随时可能出现的异常状况(即随机出现的故障),同时处理多种元素彼此组合产生的指数级状况增长(系统规模越大,状况的具体数量也就越多)。ZooKeeper是一款非常便捷的工具,而且适合大家用于打理自己的基础设施堆栈。有了它的帮助,我们可以将更多精力集中在应用程序逻辑身上。
在OpenStack当中,我们希望能够充分发挥ZooKeeper的设计目标,即利用单独一款通用型工具解决所有分布式系统带来的复杂难题。因此,我们创建了一套名为Tooz的库,用于实现一部分常见的分布式协作元。Tooz的正常运行依赖于多种不同后端驱动要素——ZooKeeper当然也是其中之一——而且能够作用于所有OpenStack项目当中。
在下一篇文章中,我们将了解如何利用OpenStack Ceilometer让Central Agent拥有出色的高可用性——其中涉及另一种重要的分布式元,即组成员(group membership)。届时我们也将开发出自己第一款基于ZooKeeper的真正应用程序,咱们到时候见!
原文标题:ZooKeeper Part 1: the Swiss army knife of the distributed system engineer
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】