每天,我都需要储存大量的数据,而我可以使用很多工具,比如 PostgreSQL,MySQL,SQLite,Redis 和 MongoDB,当我积累了丰富的经验,并且熟练掌握这些工具的时候,我就不认为他们还有什么乐趣了。我从心里热爱 Ruby,是因为它很有趣并且能让我能用自己的方式做一些很厉害的事情。但是我并没有意识到这样的数据处理工具将会影响我很久,尽管它令我找到了新的乐 趣,所以请让我向你介绍 Neo4j 吧。
什么是 Neo4j?
Neo4j 是图形化的数据库!这意味着它被优化用于管理和查询实体(节点)之间的关系(节点),而不是像一个使用表的关系数据库那样的东西。
为什么这很棒?想象一个没有国外钥匙的世界。数据库中的每个实体的关系之间都十分密切,以至于可以直接引用其他实体。如果你想要引用的关系没有关系 表或者搜索扫面,就只需要几个链接就行了。这***的展现了典型的对象模型。这非常令人兴奋,因为 Neo4j 可以提供很多我们所期待的数据库应该具有的功能,并且为我们提供了工具来查询复杂数据图形。
介绍 ActiceNote
为了链接 Neo4j,我们将使用 neo4j gem。连接到你在 Rails 应用程序中的 Neo4j 的方法,可以在 gem 文档中找到。同时此显示代码的应用程序也可在 GitHub 库中运行 Rails 应用程序(使用 sitepoint 的分支)你可以在你的数据库中运行使用前 rake load_sample_data 命令来填充数据库。
下面是一个关于资产模型的基本案例来源于资产管理的Rails APP
- class Asset
- include Neo4j::ActiveNode
- property :title
- has_many :out, :categories, type: :HAS_CATEGORY
- end
简单解释一下:
1.Neo4j的GEM给我们的Neo4j:: ActiveNode模块,其中包括我们所做的这个模型
2.此资产意味着这种模式将负责所有在Neo4j标记资产的节点(除标签一个节点可以有很多的标签发挥类似的作用)
3.我们有一个title属性来描述各个节点
4.我们有传出has_many的分类关联。这种关联帮助我们通过下面的数据库HAS_CATEGORY关系找到分类的对象。
有了这个模型,我们可以进行基本的查询来找到一个资产,并得到它的分类
- 2.2.0 :001 > asset = Asset.first
- => #<Asset uuid: "0098d2b7-a577-407a-a9f2-7ec4153cfa60", title: "ICC World Cup 2015 ">
- 2.2.0 :002 > asset.categories.to_a
- => [#<Category uuid: "91cd5369-605c-4aff-aad1-b51d8aa9b5f3", name: "Classification">]
熟悉 ActiveRecord 或者 Mongoid 的任何人会看到找个上百次。为了让它变得更有趣,让我们来定义一个 Category 模型:
- class Category
- include Neo4j::ActiveNode
- property :name
- has_many :in, :assets, origin: :categories
- end
在这里,我们的关联有一个 origin 的选项引用了 资产(asset)模型的 categories 关联。如果我们想要的话,我们可以再一次指定 type: :HAS_CATEGORY
创建Recommendations
如果我们想要获得所有和我们的 资产共享一个 category 的所有 资产(asset)会怎样?
- 2.2.0 :003 > asset.categories.assets.to_a
- => [#<Asset uuid: "d2ef17b5-4dbf-4a99-b814-dee2e96d4a09", title: "WineGraph">, ...]
那这样又会发生什么事?ActiveNode 生成一个数据库查询,指定了一个从我们的 资产(asset)到所有其他共享一个 category 的 资产(asset)的路径。然后数据库会发回那些 资产(asset)给我们。下面给出它用到的查询:
- MATCH
- asset436, asset436-[rel1:`HAS_CATEGORY`]->(node3:`Category`),
- node3<-[rel2:`HAS_CATEGORY`]-(result_assets:`Asset`)
- WHERE (ID(asset436) = {ID_asset436})
- RETURN result_assets
- Parameters: {ID_asset436: 436}
这种查询语言叫做 Cypher,它等同于 Neo4j 的 SQL。特别注意括号周围节点和接头的 ASCII 风格所代表的关系。这种 Cypher 查询有点冗余,因为 ActiveNode 在算法上面会生成这些查询。如果一个人去写这种查询,它将会看起来像这样:
- MATCH source_asset-[:HAS_CATEGORY]->(:Category)<-[:HAS_CATEGORY]-(result_assets:Asset)
- WHERE ID(source_asset) = {source_asset_id}
- RETURN result_assets
- Parameters: {source_asset_id: 436}
同时,我也发现 Cypher 比 SQL 要容易并且更强大, 但是我们在这里我们不会担心 Cypher 太多。如果你之后想学习更过关于 Cypher 的知识,你可以查找 totorials 和 refcard。
正如你所看到的,我们可以使用 Neo4j 来跨实体。太了不起了!我们也可以使用带有成对 JOINS 的 SQL 来做到。虽然 Cypher 看起来很酷,但是我们还没有什么重大的突破。假设我们想要使用这些查询来创建一些基于共享 category 的 asset recommendation 会怎样?我们会想要去对 asset 排序然后按照最多共同 category 来排序。让我们在我们的模型中创建一个方法:
- class Asset
- ...
- Recommendation = Struct.new(:asset, :categories, :score)
- def asset_recommendations_by_category(common_links_required = 3)
- categories(:c)
- .assets(:asset)
- .order('count(c) DESC')
- .pluck('asset, collect(c), count(c)').reject do |_, _, count|
- count < common_links_required
- end.map do |other_asset, categories, count|
- Recommendation.new(other_asset, categories, count)
- end
- end
- end
这里有几个有趣的地方值得注意一下:
-
我们定义变量作为后续使用链的一部分(c 或者 asset)
-
我们使用 Cypher 的 collect 函数来给我们一个包含一个共享 category 数组的结果列(参考下面的表)。还要注意,我们得到了完整的对象,不仅仅是列/属性:
|
asset |
collect(c) |
count(c) |
|---|---|---|
|
#<Asset> |
[#<Category>] |
1 |
|
#<Asset> |
[#<Category>, #<Category>, …] |
4 |
|
#<Asset> |
[#<Category>, #<Category>] |
2 |
|
… |
… |
… |
你注意到这里没有一个 GROUP BY 字句了吗?Neo4j 非常智能地意识到 collect 和 count 是聚合函数,并且在我们的结果中通过非聚合列排序(在这个案例中只有 asset变量)。
注意那条 SQL!
作为***一步,我们能够创建的不仅仅是相同 category 的 recommendation。想象一下我们有下面 Neo4j 子图:
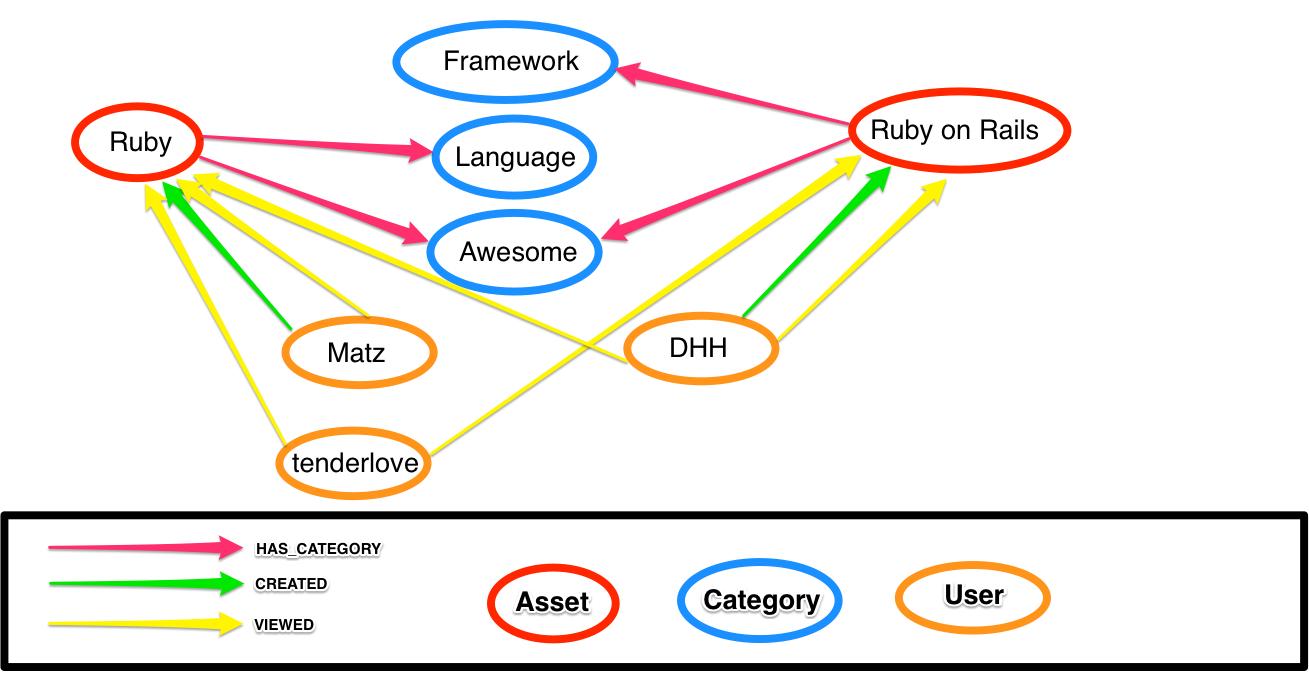
除了共享的 category 之外,让我们来解释一下 creators 和 viewers asset 有多少共同之处:
- class Asset
- ...
- Recommendation = Struct.new(:asset, :score)
- def secret_sauce_recommendations
- query_as(:source)
- .match('source-[:HAS_CATEGORY]->(category:Category)<-[:HAS_CATEGORY]-(asset:Asset)').break
- .optional_match('source<-[:CREATED]-(creator:User)-[:CREATED]->asset').break
- .optional_match('source<-[:VIEWED]-(viewer:User)-[:VIEWED]->asset')
- .limit(5)
- .order('score DESC')
- .pluck(
- :asset,
- '(count(category) * 2) + (count(creator) * 4) + (count(viewer) * 0.1) AS score').map do |other_asset, score|
- Recommendation.new(other_asset, score)
- end
- end
- end
在这里我们深入研究并开始构建我们自己的查询。结构一样,但不仅仅是通过在共享 category 的两个 asset 之间查找一条path, 我们也会指定两个更多的可选path。我们可以指定三个可选path,但是 Neo4j 需要使用数据库里边每一个其他的 资产(asset) 来对比我们的 资产(asset)。为我们的 category 节点使用 match 而不是 optional_match,我们要求至少有一个共享 category。这样极大的限制了我们的搜索空间。
在图中有1个共享 category,0个共享 creator 以及两个共享的 viewer。这意味着”Ruby“和”Ruby on Rails“之间的分数将会是:
(1*2) + (0*4) + (2*0.1) =2.2
还要注意,我们在这三条path上的 count 聚合函数上做计算(和排序)。对我来说很酷,它使得我有点兴奋地去思考。。。
容易授权
让我们来处理另外一个普遍的问题。假设你的 CEO 来到你桌子前对你说,“我们已经构建了一个非常棒的 app,但是客户想要能够控制谁可以看他们的东西。你可以建立一些隐私控制吗?”看起来很简单。让我们依赖一个标记来访问私有资产(asset):
- class Asset
- ...
- property :public, default: true
- def self.visible_to(user)
- query_as(:asset)
- .match_nodes(user: user)
- .where("asset.public OR asset<-[:CREATED]-user")
- .pluck(:asset)
- end
- end
使用这些设计,你可以显示用户可以看到的所有资产(asset),因为资产(asset)是公开的或者因为观察者拥有它。没问题,但同样不是个大问题。在另外一个数据库里边,你可以在两个列/属性上面做搜索。让我们来感受一下!
产品经理来到你身边说,“嘿,谢谢你,但是现在人们想要给其他用户直接访问他们私有的东西”。没问题!你可以创建以个 UI 来让用户添加和移除他们资产(asset)的 VIEWALBE_BY 关系,并且可以这样查询:
- class Asset
- ...
- def self.visible_to(user)
- query_as(:asset)
- .match_nodes(user: user)
- .where("asset.public OR asset<-[:CREATED]-user OR asset-[:VIEWABLE_BY]->user")
- .pluck(:asset)
- end
- end
另外这将是一个连接表。你仍在用户可以获取资产(asset)的另外一个路径。花费一些时间来欣赏 Neo4j 无模式的本质。
满足于你的工作日,靠在椅子上和喝着下午茶。当然,前提是社交媒体客户服务代表说“用户喜欢新的功能,但是他们希望能够创建分组以及分配访问分组。 你可以做到吗?并且,能允许任意层次的分组吗?你深深得看着他们的眼睛几分钟,然后说:”当然!“。之后开始变得复杂,来看个例子:
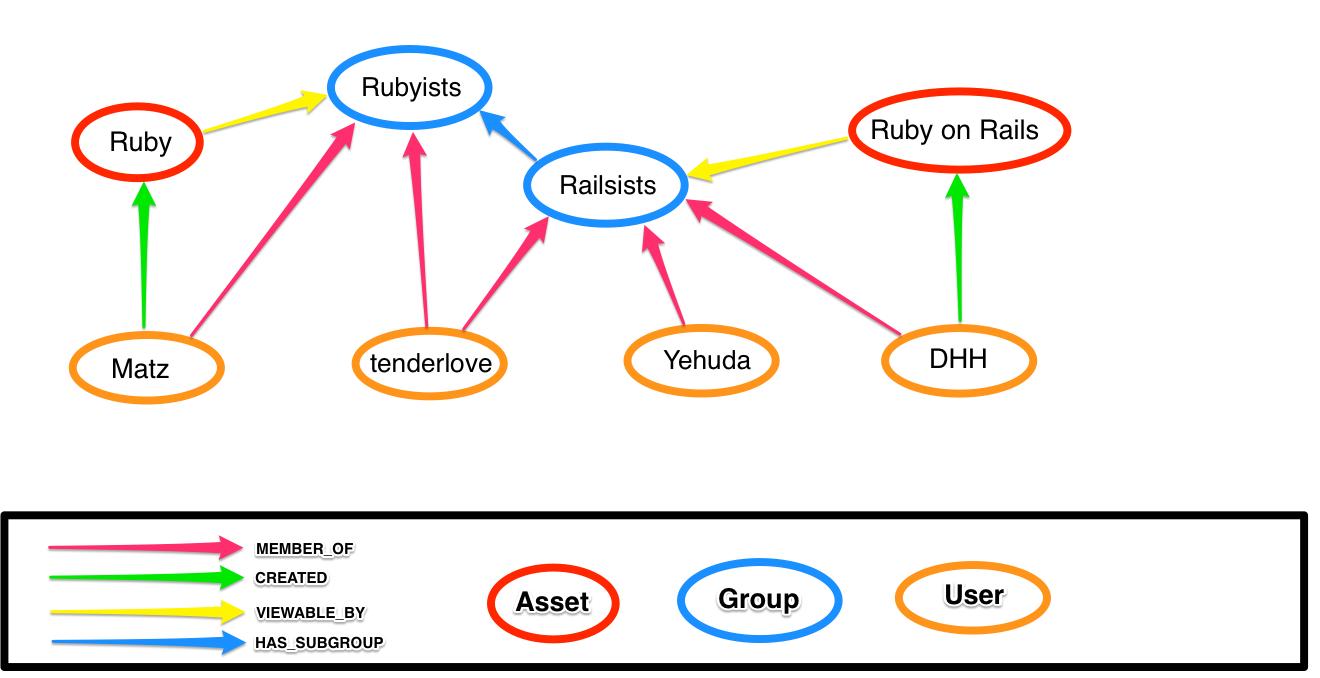
如果这些资产都是私人代码,到目前为止给 Matz 和 tenderlove 去访问 Ruby,以及 DHH 去访问 Ruby on Rails。添加分组支持,你开始直接分配分组:
- class Asset
- ...
- def self.visible_to(user)
- query_as(:asset)
- .match_nodes(user: user)
- .where("asset.public
- OR asset<-[:CREATED]-user OR asset-[:VIEWABLE_BY]->user OR
- asset-[:VIEWABLE_BY]->(:Group)<-[:BELONGS_TO]-user")
- .pluck('DISTINCT asset')
- end
- end
这个是很简单的,因为你只需要添加另外一条路径。当然,到目前为止那是我们的旧帽子。 Tenderlove 和 Yehuda 就能够看到”Ruby on Rails“资源(asset),因为他们是“Railsists”分组的。还要注意:现在一些用户有多个资产(asset)路径(像 Matz 去 Ruby 通过 Rubyists 分组和通过 CREATED 关联)你需要返回 DISTINCT asset。
然而通过一个层次结构组织来指定一个任意的path需要花费你较多的时间。你可以查看Neo4j文档直到你找到一些叫做”variable relationships“的东西并试试:
- class Asset
- ...
- def self.visible_to(user)
- query_as(:asset)
- .match_nodes(user: user)
- .where("asset.public OR asset<-[:CREATED]-user OR asset-[:VIEWABLE_BY]
- ->user OR asset-[:VIEWABLE_BY]->(:Group)<-[:HAS_SUBGROUP*0..5]-(:Group)<-[:BELONGS_TO]-user")
- .pluck('DISTINCT asset')
- end
- end
这里你已经做到了!这种查询会找到可访问一个 group 的 资产(asset)并且贯穿了0到5的 HAS_SUBGROUP关系,***以一个查看用户是否在***一个 group 里边的检查结束。你是这个故事的男主角,你的公司会为你能够快速做好这项工作而给你奖金。
结论
你可以用 Neo4j 做很多我做不到并且很棒的事情(包括使用它的 amazing web interface 去利用 Cyper 查找你的数据)。它不仅仅是一种杰出的方式用一个简单而直观的方式来存储你的数据,而且提供了很多高度联系的数据查询效率的好处(相信我你的数据是高度联系的,尽管你没有意识到)。我鼓励你去看看 Neo4j 并在你的下一个项目中试试。