机器学习基于一种算法,该算法从数据中获得学习能力,而无需依靠基于规则的编程。随着数字化的进步和计算能力日趋便宜,使得数据科学家能够停止建造模型,转而训练计算机来进行这一工作,因此机器学习在20世纪90年代晚期作为一门科学学科出现在了大众的视野中。目前全世界瞩目的大数据因其难以管理的巨大数量和复杂性增加了使用机器学习的潜能——以及对机器学习的需求。
2007年,斯坦福人工智能实验室主任李菲菲放弃了给计算机编程来识别物体这一工作,开始给百万幅3岁小孩都认得的原始图像打上标签,将这些图输入到计算机中。通过向计算机输入成百上千张带有标签的图片,比如说标示这些图片为猫,计算机能够自行判断一组特定的数码像素是否真的是只猫。去年11月,李菲菲带领的团队开发出一个程序,能够高精度地识别出任一图片中的视觉元素。IBM的沃森机器在2011年依靠类似的从成百上千的潜在答案中自发生成的评分系统打败了Jeopardy!游戏中的世界***玩家。
虽然这些壮举如此耀眼,但机器学习完全不像是人类感官类的学习。然而它在分析任意量的数据和所有变量组合方面已经做得非常出色了——将来也会做得更好。由于机器学习是在最近才刚刚作为主流管理工具涌现出来,这经常给我们带来些疑惑。在这篇文章中,我们列举了一些我们经常听到的问题,并以一种我们希望对任何使用者来说都能有用的方式予以解答。现在是时候解决这些问题了,因为由机器学习强化的商业模型带来了骤然飙升的竞争力。确实,管理学家Ram Charan表示「任何现在还不会使用数学或无法迅速掌握数学的机构都将是行将就木的公司了。」
1. 传统行业如何利用机器学习来收集新的商业视点?
好,让我们从体育开始。今年春季,美国NBA赛事的参赛者依赖于一家加州机器学习创业公司的二次谱法分析,通过数字化过去几个赛季的比赛,创造了预测模型,使教练能够分辨出如其CEO Rajiv Maheswaran所描述的「得分的差射手,和不得分的好射手」,以此来调整他的战略部署。
没有比通用电气更值得尊敬或更传统的了,它是历经119年道琼斯工业指数上唯一留下的老成员了。通用已经通过处理从深海油井或飞机引擎收集到的数据来优化其表现力,预见故障和提升维护效率,从而赚到了亿万美元。但是去年年底从IBM离职后作为软件研发部副总裁加入GE的Colin Parris认为,在数据处理能力、传感器和预测算法方面的持续改进不久将会对其公司独特的喷射引擎带来深刻影响,这不亚于谷歌对西好莱坞一位24岁网民的在线行为带来的影响
2. 北美之外的地方如何呢?
在欧洲,超过数十家银行更换了旧的统计分析模型,用上了机器学习技术,在某些情况下,新产品的销售提升了10个百分点,资本支出节省了20个百分点,兑现收集增加了20个百分点,流失损耗减少了20个百分点。银行通过为零售客户和中小型企业设定新的推介引擎实现了上述目标。他们也建立了宏观目标模型,来更加精确地预测哪些人会取消服务,或无法归还贷款,以及如何***的介入这一切。
更贴近生活些的,最近一篇麦肯锡季刊上的报道指出,我们的同行已经将硬性的分析学应用于软性的人才管理这类事物中了。去年秋季,他们测试了由外部供应商提供的三种算法和内部自研的一种算法,这些算法主要通过检验扫描的简历,预测这家公司最终会在超过10000名的应征者中录取哪些人。预测结果与实际结果十分贴切。有趣的是,机器所选的应征者中女性占据稍高的比例,这保证了利用分析技术来使概况更加广泛,并克服了隐藏的人类偏见性。
随着模拟世界越发的数字化,我们通过研发测试算法从数据中学习的能力对于那些现在被视为传统商业的情况来说只会越来越重要。谷歌***经济学家Hal Varian将之称之为「计算机持续改进」。他认为,「只是因为大量产品改变了曾经的组装方式,持续改进改变了曾经的制造业情况,所以持续的『通常也是自动化的』实验将会改善我们在机构中优化商业过程的方式。」
3. 机器学习的早期基础是什么?
机器学习基于大量的早期构造模块,起始于经典统计学。统计推论确实为当前人工智能的落实构建了重要基础。但需要意识到经典统计学技术在18世纪到20世纪早期得到了发展,应用于很多比我们现在处理的小的多的数据组中。机器学习不受统计学预设的假设限制。因此,它能够得出人类分析师看不到的见解,并做出精度更高的预测。
最近,在20世纪30年代到40年,计算机先驱(比如阿兰·图灵,他对人工智能有着深刻持久的兴趣)开始研究并改善基本技术,比如使今天的机器学习成为可能的神经网络。但这些技术留在实验室的时间比很多其他技术要长的多,大多数情况下,这些技术不得不等待强大的计算机发展与建设的完成,而这直到70年代晚期和80年代早期才初具规模。这可能就是机器学习导入曲线的起始点。新技术被引入进现代经济——比如,蒸汽机、电力、电力马达和计算机——似乎花费了将近80年的时间,才从实验室过渡到你可能会称之为文化缺位的时刻。计算机现在还未退出大众视野,但这可能会在2040年发生。而机器学习退居幕后可能不会花费很多时间。
4. 那我们从何开始?
如果高管们把机器学习视为一个制作和实施公司战略愿景的工具, 那么他们会***程度的利用它。但这也意味着将战略放在首位。若不以战略为出发点, 机器学习可能沦为忙于处理公司日常运营的工具: 它能提供一定的帮助, 但其长期价值很可能被局限于***重复的”饼干模型”应用中, 比如建模来获得新客户, 刺激和保有客户等。
我们发现了与并购类似的有益之处,毕竟这是一种达到明确目的的手段。 没有哪个明智的商家会匆忙地开始一场并购然后坐等结果。从事机器学习的公司应该像从事并购的公司一样做出三个承诺。***,调查所有的可行方案;第二,全力追踪高管的战略;第三, 使用(如果有需要的话)高管已有的专长和知识来引导战略的应用。
负责制定战略远景的人很可能(或曾经)是数据科学家. 但在定义问题和战略所需的结果时, 他们需要来自监管其他重要战略举措高管同事的指导。更广泛来说, 公司需要两种人来释放机器学习的潜力.「定量分析家(Quants)」接受语言和方法训练。「翻译家(Translators)」能搭建数据科学,机器学习和根据定量分析家的复杂结果重构成公司总经理可执行的有价值的情报所做决策之间的桥梁。
对于有效的机器学习来说需要有用可靠的数据,比如在测试中发现沃森预测肿瘤结果的能力比医生要好,而Facebook最近成功的教会了计算机识别特定的人脸,其精确度几乎和人类一样。真正的数据战略起始于识别数据间的差距,决定填补这些差距所需的时间和花费,并打破这些孤岛。通常,部门囤积信息并将之政治化——这也是一些公司创建负责将所需要的信息整合在一起的***数据官这一新岗位的原因。其他因素还包括基层管理者需要负责产生数据等。
由小开始——寻找小方面的成果并鼓励任何早期的成功。这将帮助招募到基层的支持并增强个体行为及员工补偿买入的变化,从而最终决定一个机构能否有效应用机器学习。***,根据明确的成功标准来进行评估。
5. 高层管理应扮演什么角色?
改变行为是至关重要的,高层管理人员的一个关键任务就是去影响和鼓励它。比如说,传统的管理人员将必须熟悉自己在A/B测试中的变化,其中,这种测试是被数码公司用来检验什么会或者不会吸引线上消费者的一项技术。尽管有日益强大的计算机提供建议,一线的管理人员还是必须要学会自己做更多决策,紧随高层管理人员设定的大方向,只有在出现意外时才重新校准方向。普及数据分析是需要时间的,比如让一线人员掌握必要的技能、对分享数据实施合适的激励等。
***级别的***执行层人员应该分三个阶段来运用机器学习——机器学习1.0、2.0和3.0,或者,我们更愿意分别称之为描述、预测和处方。他们或许无需过分担心处方阶段,因为大部分公司已经过了这个阶段。那是所有关于往数据库中收集数据(基于目标),发展出能够为管理层提供基于过去的新洞察的工作。OLAP(在线分析处理)对大多数大公司来说已经是一项较完善的例行工作。
对预测阶段的需求显得更加紧迫。这也是目前正在发生的事。今天的前沿技术不仅允许公司查看过去的历史数据,还能预测未来的行为或结果——比如说,可以帮助银行的信用风险控制人员评估哪些客户更容易欠债不还,或者能让电信公司预测近期可能流失哪些客户。
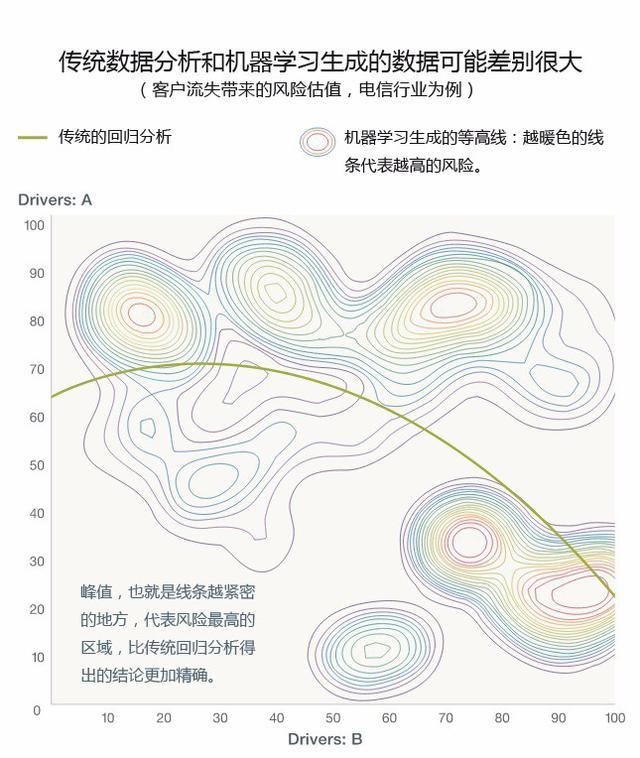
在预测阶段,***层管理人员最担心的就是数据的质量。这种担心常常阻滞事务的执行。尽管,根据我们的经验,最近十年的IT投资已经让绝大多数公司足以从哪怕不完整和混乱的数据集中获取新的洞察,如果这些公司选择了正确的算法的话。比起挖掘旧数据库,引入新的数据源可能只会带来微乎其微的益处。面对这种挑战,正是「***数据科学家」(chief data scientist)的任务。
处方阶段是机器学习中的第三个阶段,也是***级的阶段,代表着未来的机会,应当得到***层管理者的高度重视。毕竟,只预测消费者未来的行为是远远不够的,只有理解了他们行为背后的原因,公司才能鼓励或防止这些未来的行为。从技术上说,在人工翻译的辅助下,今天的机器学习算法已经能够做到这一点了。比如说,一家国际银行担忧自己零售业务中拖欠借款的规模,它最近锁定了一批客户,他们使用信用卡的时间从白天突然变成了半夜。这种刷卡模式伴随着他们存款率的急剧下降。在咨询支行经理后,银行还发现,这些人最近都经历了一些压力很大的事件。结果,所有被算法贴上这个标签的客户都被银行细分到一个小的市场区隔内,自动设定了新的信用额度,并向他们提供了财务顾问。
机器学习的处方阶段开创了人机协作的新时代,将为我们的工作方式带来巨大的变革。在机器识别模式的同时,人类翻译者的责任就是用这些模式来对市场进行进一步细分,并提出行动建议。在此,***层管理者应该直接参与制定和修订目标中,充分优化算法。
6. 长远来看,这很像要用自动化来取代人类。那么,近期机器是否会取代管理人员呢?
真的,变化来得如此迅速(数据已经有了),以至于依靠人来做决策很快会变得不实际。我们预计,三到五年后,会有更高级的人工智能,分布式自治系统(DAC, distributed autonomous corporations.)也会得到更大的发展。这些自激励、自给自足的环节组成了一个系统,能够自动设定目标,而无需任何直接的人类监管。某些DAC肯定还能实现自我编程。
有一种观点认为,分布式自治系统对我们的文化而言是一种不利的威胁。但是,当它们发展完全时,机器学习将会在文化中变得隐形,就像20世纪那些科技发明一样,完全隐没在文化的背景中。人类的角色将是管理和引导算法,以实现它们背负的目标。这是2008年金融危机中,造成巨大损失的自动交易算法带给人们的教训。
不管计算机能揭示出多少新的洞察,只有人类管理人员才有能力决定什么问题是最根本的,比如说公司正要解决什么关键的业务问题。正如人类职员需要定期回顾和评估一样,这些「聪明的机器」和它们的业绩也需要定期由经验丰富、能明辨是非、拥有专业知识的高管们进行评估、精炼——甚至被炒鱿鱼,或被要求转向其他方向,谁知道呢。
***的赢家不会是单独的机器,也不会是单独的人类,而是两者高效的协同工作。
7. 所以,长期来看,我们不需要担心吗?
很难给出一个确切的答案,但是,在***层管理人员的日常工作中,分布式自治系统和机器学习的程度应该会很高。我们期待着未来有一天,何为智能(无论人工与否)的哲学讨论终将结束,因为那时将不再有什么智能——只有各种过程。如果分布式自治系统的表现、执行和反应都很智能,那么,关于「是否存在除人之外的高级智能」的争论必将停止。同时,我们应该开始思考应该让它们做些什么,对它们的表现有何期望,以及我们应当如何同它们一起工作。