













【51CTO.com快译】Amazon刚刚经历的云服务停机事故引发业界对云技术的又一番争论。
就在上周日上午时段,Amazon Web Services数据中心遭遇一起相当严重的意外事故。
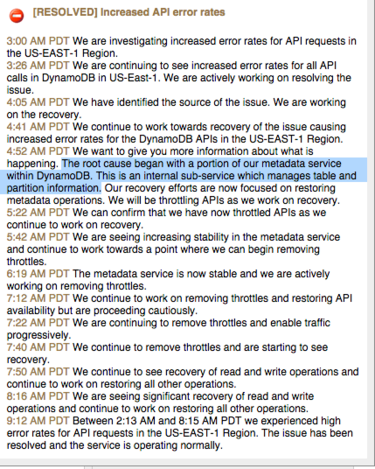
美国东部时间清晨六点,该公司负责承载AWS东弗吉尼亚区域负载的名为DynamoDB的大规模NoSQL数据库发生使用率暴涨状况——顺带一提,东弗吉尼亚州区域为该公司历史最悠久、规模***的九个全球性区域之一。到当日上午七点五十二分,AWS判断出问题根源:该数据库的元数据管理机制出现问题,直接影响到其服务的分区与表。
Amazon Web Services
Amazon Web Service的运行状况仪表板所示之上周日故障事件时间流程,其中包含引发问题的根本原因。
由于AWS服务使用极为复杂的互连机制,因此该问题滚雪球般影响到了总计117项受运行状况仪表板监控的服务类别当中的34项。从Elastic Comupte Cloud(即弹性计算云,简称EC2)到虚拟机、到Glacier存储服务再到Relational Database Service(即关系数据库服务)皆受到波及。根据媒体报道所言,其它采用AWS方案的企业客户亦遭到影响,其中包括Netflix、IMDB、Tinder、Pocket以及Buffer等知名公司。
截至上周日中午,AWS方面报告称问题已经得到解决,但在其期间Twitter及其它社交平台上出现了大量投诉与抱怨之声。
那么我们该从此次事故当中吸取哪些经验教训?下面请大家一同探讨其中的三项重点。
1.云服务巨头也有失蹄的时候
Amazon Web Services是目前公有IaaS云领域当之无愧的王者——虽然微软公司似乎也在这类业务身上砸下重金,但似乎仍然无法动摇Amazon的强势地位。上周日的事故则提醒我们,即使是规模***、经验最为老到的云服务供应商,也仍然有可能遭遇意料之外的突发状况。
2.时刻准备迎接停机事故
考虑到即使是市场上成熟程度***的云方案也仍然有可能——或者说实际遭遇到长达六个小时的服务停机,客户应当提前为此做好准备。AWS长久以来一直建议客户对自有系统进行架构规划,从而更加主动地应对可能出现的虚拟机或者其它服务停机。
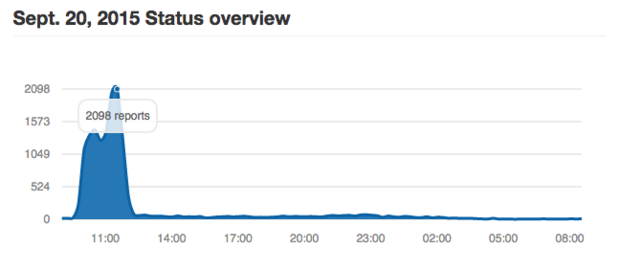
DownDetector.com网站统计图表显示,Netflix公司上周日早晨的错误报告频率远高于正常状况。不过根据该公司的一位发言人所说,其服务并没有受到显著影响。
作为Amazon公司旗下规模***且***知名度的云服务客户之一,Netflix公司通过发言人强调称,此次停机事故给其服务造成的影响被控制在了***程度,这是因为其以自动化方式将工作负载从出现问题的美国东部区域设施迁移到了其它运行正常的区域。任何使用AWS承载关键性业务应用的客户都应当对系统架构进行调整,从而确保其能够在相关云服务出现意外状况时做好应对措施。Netflix公司还开发出了一系列开源工具,旨在帮助自身系统进行随机崩溃测试。尽管Netflix方面并不承认其客户因此次事故受到严重影响,不过第三方停机追踪站点却发布报告称,Netflix在上周日早间遭遇到远超过正常水平的服务中断频率。换言之,即使是做好了充分准备的高水平客户,也没办法完全避免云服务中断造成的影响。
3.“莫谓言之不预”
福布斯网站的一位博主认为,此次服务中断并不会改变云计算的未来普及趋势。我个人基本同意这种看法。如果大家身为AWS的拥护者,那么肯定会从积极的角度看待此次事件,例如中断事故的发生频率远低于以往,如果客户采取AWS推荐的***实践、那么这些意外也不会造成太大影响等等。
不过换个角度来看,像上周日这样的服务中断状况将成为有力证据,促使那些不愿将工作负载交给公有云打理的客户抱持更加顽固的心态。
事实上中断事故是不可避免的,其可能出现在公有云服务中、任意供应商处甚至连企业自己负责运行的内部数据中心也不放过。而这正是IT事务的本质与宿命,所以一味强调公有云存在可用性问题确实不太客观。
原文作者: Brandon Butler
原文标题:3 Big takeaways from Amazon’s latest cloud outage
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】

















