这一篇我们来聊聊监控系统的架构。欢迎大家加入运维开发讨论交流群来交流,群号 365534424,本文仅授权51reboot、51cto上发布。
架构这个词太大了,这里我们缩小一下,只来谈谈宏观的监控系统整体架构。在这个范围里面,web由于负责统一的系统管理和操作功能,缩减为一个模块。
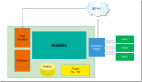
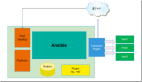
最简单的架构如下图:
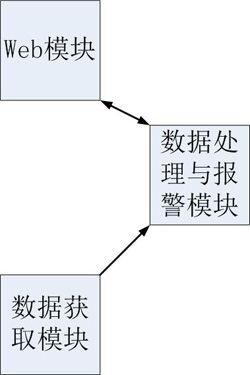
这是监控系统***层的架构。比照百度地图的话,我们可以认为这个是全国地图。最粗粒度的几个模块就是这三个:web、数据采集、数据处理。
PUSH和PULL
我们先来关注数据采集模块到数据处理和报警模块的这个环节。
推和拉,技术选型里面常常遇到的一个选择题。 在Client/server结构中,信息获取方式是按“拉”(Pull)的模型进行的:服务器根据用户终端发送的服务请求进行处理并返回用户所需的结果。在Push模型中,服务器把信息“推”给Client。虽然两者数据传输的方向都是从服务器流向Client,但操作的发起者是不同的。从“信源”与 “用户”的关系来看,信息的流动可分为两种模式,即信息推送与信息拉取模式。
两种模型的对比见表格:
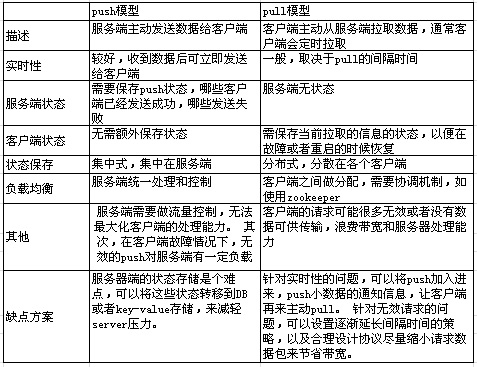
其中PUSH的好处是及时性好。但缺点是服务端要有比较复杂的状态管理。同时在到达率等方面都会有一些纠结的地方。而PULL的好处则是服务端简单,状态管理简单,但缺点是时效性上不可控。体现在监控系统上,如果所有要监控的监控项,都是需要Server端PUSH给Client,假设Client所在服务器关机了,那PUSH的时候就是不可达的。Server端就得想办法记录下来,并且再做重试等失败处理。而如果是Client端主动来PULL就好办了,服务器开机启动之后,Client立刻来拉取。到达率肯定要好,对Server的管理也简化了。但缺点就是想生效一个监控项,只能等着Client来 PULL,而无法立即生效。
这里还有一个比较经典的例子,也是我面试别人的时候总喜欢问的一个问题。当然我问面试者的时候主要是想去看看TA的逻辑思维能力。
题目:微博大家都用过。里面你可以关注一个人,也可以被人关注。当你发一条微博时,关注你的人都会收到一条提示。当你关注的人发一条微博时,你会收到一条提示。 请问这个提示,是PUSH 还是 PULL到你的微博客户端(浏览器或者手机微博)上的?
面试者:肯定会有人说,PUSH呗。
面试官:OK,然后我就会问了,姚晨在新浪微博上的粉丝数是5000多万,她发一条微博,是不是得PUSH 5000多万个消息到各个账号去?
面试者:额,那就是定时PULL
面试官:确定吗?几千万个客户端都PULL?
面试者:额。。。 面试者开始额头黑线了。
面试官:请问该怎么办?
PUSH的话,姚晨的一条微博,在系统里面就要产生5000万条消息要处理。如果她一天发个100条,估计新浪微博疯了。这还没有考虑很多客户端不登陆,消息就得缓存着。还有很多客户端一下子通知不到,还得处理失败。
PULL的话,如果大量用户在使用的生产系统,对存储和缓存是一个很大的挑战。
具体的,大家可以再去google一下,这个事情其实有很多方案。
经验比较丰富的研发一定会同意我的一个说法:两个争论不休的技术方案,最终能达成一个融合了二者的第三个方案。就好像两个特别对立的谈判方,到***谈判结果是一个融合或者叫妥协的方案。PUSH和PULL也可以二者融合,将做到取长补短,使二者优势互补。根据推、拉结合顺序及结合方式的差异,又分以下四种不同推拉模式:
◆先推后拉——先由服务端PUSH,再由Client端有针对性地拉;
◆先拉后推——根据Client端PULL的信息,服务端进一步主动PUSH与之相关的信息;
◆推中有拉——在数据推送过程中,允许Client随时中断并PULL更有针对性的信息;
◆拉中有推——根据Client端PULL的过程,Server主动推送相关的***信息
#p#
几个开源监控系统的PUSH、PULL选择
zabbix:带agent方式。agent主动推送数据到服务端。 从client的角度看,是PUSH数据到Server。
Cacti:SNMP协议,无Client,或者说Client是SNMP Client。从Client角度看,是PULL。
ganglia:从Client角度看,是PUSH。
在我过去生产环境所构造的监控系统里面,我们采用了PUSH和PULL结合的方式来达到及时性、到达率的同时解决。我们站在Client的角度来描述这个解决方案。对于监控项的生效,Web端变更之后立即使用PUSH的方式来通知Client。但这里一定有达到率的问题。比如Client所在服务器死机了、重启了、当时网络有问题不可达等等。所以我们在Client端,支持定时PULL。定时去主动联系Server端,获取自己应该生效的监控内容。
HASH
怎么突然又说到HASH了呢?HASH先来个概念普及吧!看完概念还是不了解的同学,自行面壁去,你计算机数据结构一定没好好学。
我说HASH是因为要为后面介绍高可用性架构有关系的。
HASH你别直接拿去搜,用百度的结果就是哈士奇。
关键词可以是哈希。
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
Hash在算法里面是很基础但使用非常广泛的。特别是在大数据量的情况下。
我这里强调Hash,是想说它的一个作用之一就是散列。把输入散列到几个地方去。提到Hash不得不提一个词叫做一致性Hash,这个算法对于解决缓存***率有很大好处。在内存缓存、CDN等存储系统中经常使用。
Hash的精髓之一就是按照某种计算规则,把输入散列到不同的输出通道上去。
无状态和有状态
我们拿无状态协议来体验一下无状态是个什么概念。
协议的状态是指下一次传输可以“记住”这次传输信息的能力。典型的如HTTP协议是不会为了下一次连接而维护这次连接所传输的信息,由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息。这有可能出现一个浏览器在短短几秒之内两次访问同一对象时,服务器进程不会因为已经给它发过应答报文而不接受第二期服务请求。由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议(Stateless Protocol)。
监控系统里面的HASH和状态
监控系统对数据的处理,主要是过滤异常数据出来并报警。比如某个服务器的CPU利用率超过了95%,需要报警。但这个时候突然数据处理模块所在服务器宕机了。那么,这个异常数据很有可能就丢掉了。
监控系统常见的报警条件是: CPU利用率超过95%,算一次异常。如果5分钟内有3次异常,报警给运维。
这里就有几个数字需要处理,5分钟,3次。前面提到的宕机,会导致一次异常数据丢掉了。假设5分钟内出现了3次,丢掉了一次,那自然不会报警出来。这就是一个有状态的场景。
有状态的情况下,做自动切换或者负载均衡,需要把状态也带过去才行。
比较典型的还有session的问题。如果web是多台主机负载均衡的时候,session存本地是会出问题的。因为用户有可能通过负载均衡的调度,多次请求落在不同的主机上。 本来HTTP协议是无状态的,支持负载均衡的调度。但因为session这个有状态的产物,必须要把session放在公共存储上才行。
结合前面提到的那个架构图。数据进入到了数据计算和报警模块。我们如何保证这个数据计算和报警模块是个高可用的架构。
答案是,把输入的监控数据Hash到不同的数据计算和报警模块实例上去,并且***是无状态或者弱状态的计算过程。(未完待续)