LinkedIn 创建于 2003 年,主要目标是连接你的个人人脉以得到更好的的工作机会。上线***周只有 2700 个会员,之后几年,LinkedIn 的产品、会员、服务器负载都增长非常快。
今天,LinkedIn 全球用户已经超过 3.5 亿。我们每天每秒有上万个页面被访问,移动端流量已占到 50% 以上。所有这些接口请求都从后台获取,达到每秒上***。
那么,我们是怎么做到的呢?
早些年 – Leo
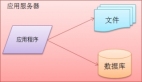
LinedIn 开始跟很多网站一样,只有一台应用服务做了全部工作。这个应用我们给它取名叫“Leo”。它包含了所有的网站页面(JAVA Servlets),还包含了业务逻辑,同时连接了一个轻量的 LinkedIn 数据库。
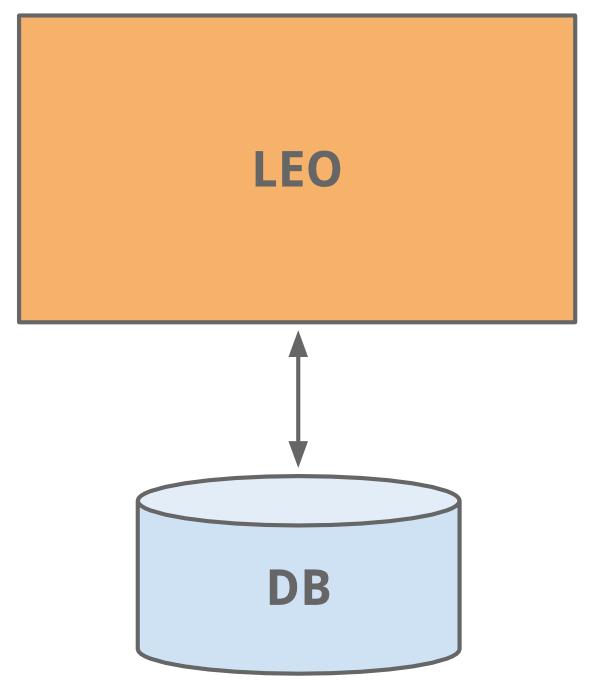
哈!早年网站的形态-简单实用
会员图表
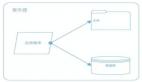
***件要做的是管理会员与会员间的社交网络。我们需要一个系统来图形化遍历用户之间连接的数据,同时又驻留内存以达到有效和高性能。从这个不同的需 求来看,很明显我们需要可以独立可扩展的 Leo。一个独立的会员图示化系统,叫“云”的服务诞生了 – LinkedIn 的***个服务。为了让图表服务独立于 Leo,我们使用了 Java RPC 用来通讯。
也大概在这期间我们也有搜索服务的需求了,同时会员图表服务也在给搜索引擎-Lucene 提供数据。
复制只读数据库
当站点继续增长,Leo 也在增长,增加了角色和职责,同时自然也增加了复杂度。负载均衡的多实例 Leo 运转起来了。但新增的负载也影响了 LinkedIn 的其它关键系统,如会员信息数据库。
一个通常的解决方案是做垂直扩展 – 即增加更多的 CPU 和内存!虽然换取了时间,但我们以后还要扩展。会员信息数据库受理了读和写请求,为了扩展,一个复制的从数据库出现了,这个复制从库, 是会员主库的一个拷贝,用早期的 databus 来保证数据的同步(现在开源了)。从库接管了所有的读请求,同时添加了保证从库与主库一致的逻辑。
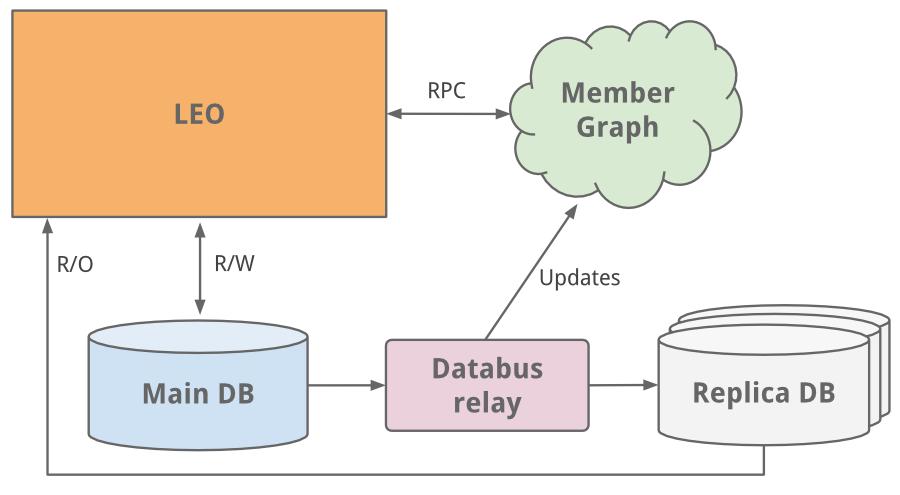
当主-从架构工作了一段时间后,我们转向了数据库分区
当网站开始看起来越来越多流量,我们的应用服务 Leo 在生产环境经常宕机,排查和恢复都很困难,发布新代码也很困难,高可用性对 LinkedIn 至关重要,很明显我们要“干掉”Leo,然后把它拆分成多个小功能块和无状态服务。
面向服务的架构 – SOA
工程师从分解负担 API 接口和业务逻辑的微服务开始,如搜索、个人信息、通讯及群组平台,然后是展示层分解,如招募功能和公共介绍页。新产品和新服务都放在 Leo 之外了,不久,每个功能区的垂直服务栈完成了。
我们构建了从不同域抓取数据模型的前端服务器,用于表现层展示,如生成 HTML(通过 JSPs)。我们还构建了中间层服务提供 API 接口访问数据模型及提供数据库一致性访问的后端数据服务。到 2010 年,我们已经有超过 150 个单独的服务,今天,我们已经有超过 750 个服务。
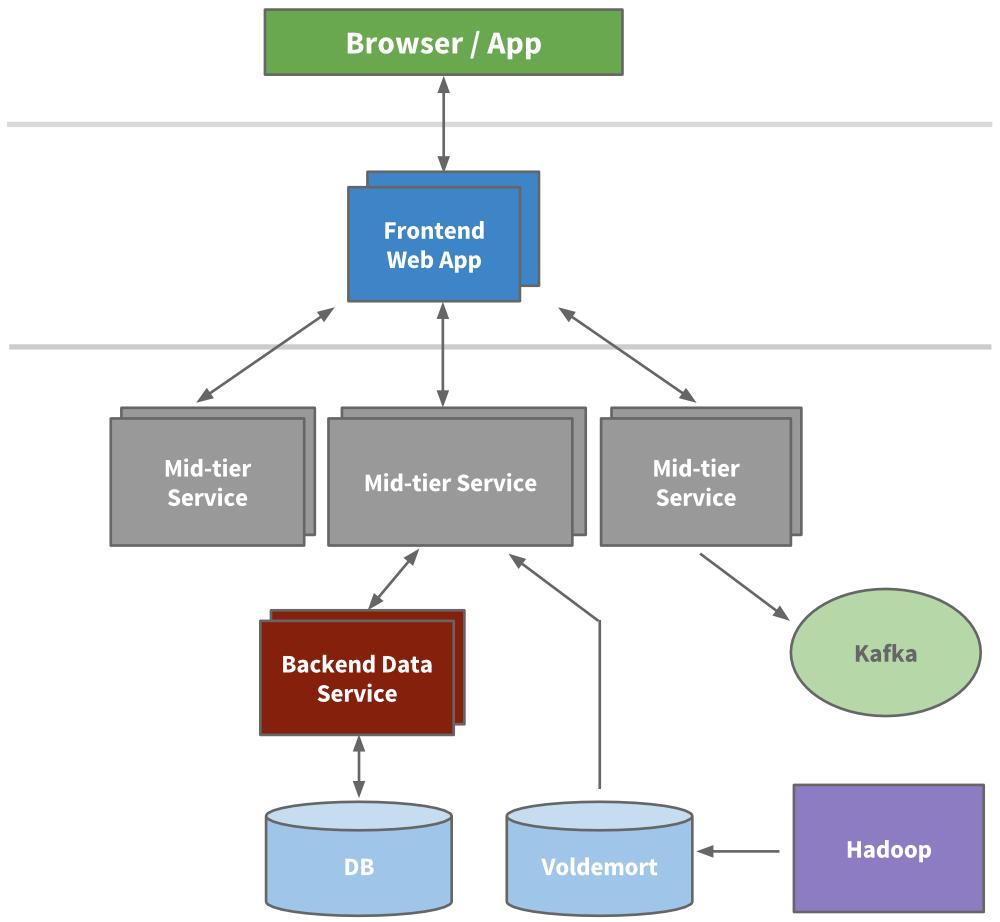
因为无状态,可以直接堆叠新服务实例及用硬件负载均衡实现扩展。我们给每个服务都画了警戒红线,以便知道它的负载,从而制定早期对策和性能监控。
缓存
LinkedIn 可预见的增长,所以还需要进一步扩展。我们知道通过添加更多缓存可以减少集中压力的访问。很多应用开始使用如 memcached/couchbase 的中间层缓存,同时在数据层也加了缓存,某些场景开始使用 useVoldemort 提供预结果生成。
又过一了段时间,我们实际上去掉了很多中间层缓存,中间层缓存数据往往来自多个域,但缓存只是开始时对减少负载有用,但更新缓存的复杂度和生成图表变得更难于把控。保持缓存最接近数据层将降低潜在的不可控影响,同时还允许水平扩展,降低分析的负载。
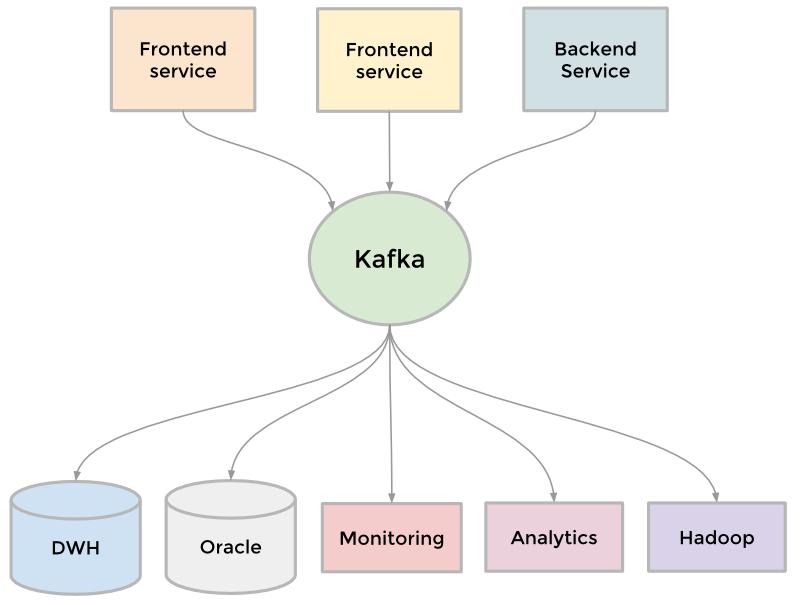
Kafka
为了收集不断增长的数据,LinkedIn 开始了很多自定义的数据管道来流化和队列化数据,例如,我们需要把数据保存到数据仓库、我们需要发送批量数据到 Hadoop 工作流以分析、我们从每个服务聚合了大量日志、我们跟踪了很多用户行为,如页面点击、我们需要队例化 InMail 消息服务、我们要保障当用户更新个人资料后搜索的数据是***的等等。
当站点还在增长,更多定制化管道服务出现了,因网站需要可扩展,单独的管道也要可扩展,有些时候很难取舍。解决方案是使用 kafka,我们的分布式发布-订阅消息平台。Kafka 成为一个统一的管道服务,根据提交的日志生成摘要,同时一开始就很快速和具有可扩展性。它可以接近于实时的访问所有数据源,驱动了 Hadoop 任务,允许我们构建实时的分析,广泛的提升了我们站点监控和告警的能力,同时支持将调用可视化。今天,Kafka 每天处理超过 5 亿个事件。
反转
扩展可从多个维度来衡量,包括组织结构。2011 年晚些时候,LinkedIn 内部开始一个创新,叫”反转”(Inversion)。我们暂停了新功能开发,允许所有的开发部门集中注意力提升工具和布署、基础架构及实用性开发。这对 于今天敏捷开发新的可扩展性产品很有帮助。
近几年 – Rest.li
当我们从 Leao 转向面向服务的架构后,之前基于 JAVA 的 RPC 接口,在团队中已经开始分裂了,并且跟表现层绑得太死,这,只会变得更坏。为了搞定这个问题,我们开发了一套新的 API 模型,叫 Rest.li,它是一套以数据为中心的架构,同时保证在整个公司业务的数据一致性且无状态的 Restful API。
基于 HTTP 的 JSON 数据传递,我们新的 API 最终很容易支持到非 java 编写的客户端,LinkedIn 今天依然主要用 Java,但同时根据已有的技术分布也利用了 Python、Ruby、Node.js 和C++。脱离了 RPC,同时也让我们从前端表现层及后端兼容问题解耦,另外, 使用了基于动态发现技术(D2)的 Rest.li,我们每个服务层 API 获得了自动负载均衡、发现和扩展的能力。
今天,LinkedIn 所有数据中心每天已经有超过 975 个 Rest.li 资源和超过千亿级 Rest.li 调用。
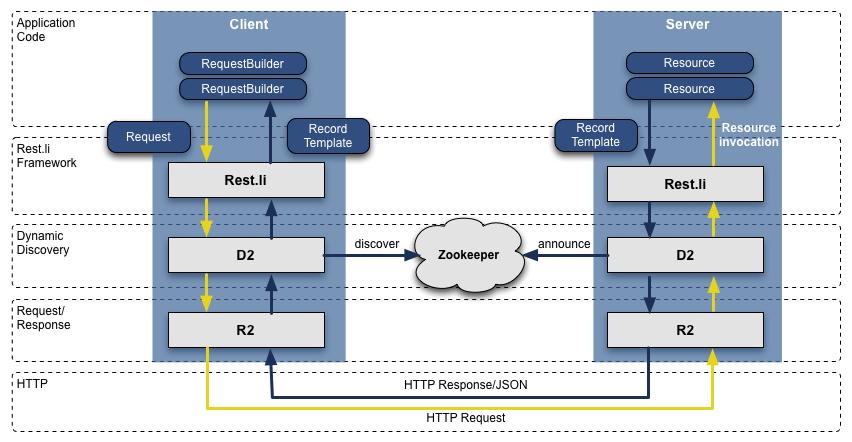
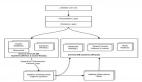
Rest.li R2/D2 技术栈
超级块
面向服务的架构对于域解耦和服务独立扩展性很有帮助,但弊端是,大都我们的应用都需要很多不同类型的数据,按序会产品数百个延伸的调用。这就是通常 说的“调用线路图”,或伴随着这么多延伸调用的“扇出”(fan-out)。例如,任何个人信息页都包含了远不止于相册、连接、群组、订阅、关注、博客、 人脉维度、推荐这些。调用图表可能会很难管理,而且只会把事件搞得越来越不规则。
我们使用了”超级块”的概念 – 一个只有单一 API 接口的群组化后台服务。这样可以允许一个小组去优化一个“块”,同时保证每个客户端的调用情况可控。
多数据中心
作为一个会员快速增长的全球化公司,我们需要将数据中心进行扩展,我们努力了几年来解决这个问题,首先,从两个数据中心(洛杉矶和芝加哥)提供了公 共个人信息,这表明,我们已经可以提供增强的服务用来数据复制、不同源的远程调用、单独数据复制事件、将用户分配到地理位置更近的数据中心。
我们大多的数据库运行在 Espresso(一个新的内部多用户数据仓库)。Espresso 支持多个数据中心,提供了主-主的支持,及支持复杂的数据复制。
多个数据中心对于高可用性具有不可思议的重要性,你要避免因单点故障不仅只导致某个服务失效,更要担心整个站点失效。今天,LinkedIn 运行了 3 个主数据中心,同时还有全球化的 PoPs 服务。
我们还做了哪些工作?
当然,我们的扩展故事永远不止这么简单。我们的工程师和运维团队这些年做了不计其数的工作,主要包括这些大的初创性的:
这些年大多关键系统都有自己的丰富的扩展演化历史,包括会员图表服务(Leo 之外的***个服务),搜索(第二个服务),新闻种子,通讯平台及会员资料后台。
我们还构建了数据基础平台支持很长一段时间的增长,这是 Databus 和 Kafka 的***次实战,后来用 Samza 做数据流服务,Espresso 和 Voldemort 作存储解决方案,Pinot 用来分析系统,以及其它自定义解决方案。另外,我们的工具也进步了,如工程师可自动化布署这些基础架构。
我们还使用 Hadoop 和 Voldemort 数据开发了大量的离线工作流,用以智能分析,如“你可能认识的人”,“相似经历”,“感觉兴趣的校友”及“个人简历浏览地图”。
我们重新考虑了前端的方法,加了客户端模板到混合页面(个人中心、我的大学页面),这样应用可以更加可交互,只要请求 JSON 或部分 JSON 数据。还有,模板页面通过 CDN 和浏览器缓存。我们也开始使用了 BigPipe 和 Play 框架,把我们的模型从线程化的服务器变成非阻塞异步的。
在代码之外,我们使用了 Apache 的多层代理和用 HAProxy 做负载均衡,数据中心,安全,智能路由,服务端渲染,等等。
***,我们继续提升服务器的性能,包含优化硬件,内存和系统的高级优化,利用新的 JRE。
下一步是什么
LinkedIn 今天仍在快速增长,仍然有大量值得提升的工作要做,我们正在解决一些问题,看起来只解决了一部分 – 快来加入我们吧!