在「HTTP/2 与 WEB 性能优化(一)」这篇博客中,我主要写了 HTTP/2 中的 Server Push 给 WEB 性能优化带来的便利,今天继续来聊一聊 HTTP/2 其他方面的改变。
我们知道,HTTP/2 并没有改动 HTTP/1 的语义部分,例如请求方法、响应状态码、URI 以及头部字段等核心概念依旧存在。HTTP/2 最大的变化是重新定义了格式化和传输数据的方式,这是通过在高层 HTTP API 和低层 TCP 连接中引入二进制分帧层来实现。这样改动的好处是原来的 WEB 应用完全不用修改,就能享受到协议升级带来的收益。
HTTP/2 的连接
HTTP/1 的请求和响应报文,都是由起始行、首部和实体正文(可选)组成,各部分之间以文本换行符分隔。而 HTTP/2 将请求和响应数据分割为更小的帧,并对它们采用二进制编码。下面这幅图中的 Binary Framing 就是新增的二进制分帧层:
先来看看这几个概念:
帧(Frame):HTTP/2 数据通信的最小单位。帧用来承载特定类型的数据,如 HTTP 首部、负荷;或者用来实现特定功能,例如打开、关闭流。每个帧都包含帧首部,其中会标识出当前帧所属的流;
消息(Message):指 HTTP/2 中逻辑上的 HTTP 消息。例如请求和响应等,消息由一个或多个帧组成;
流(Stream):存在于连接中的一个虚拟通道。流可以承载双向消息,每个流都有一个唯一的整数 ID;
连接(Connection):与 HTTP/1 相同,都是指对应的 TCP 连接;
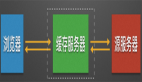
在 HTTP/2 中,同域名下所有通信都在单个连接上完成,这个连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。下面有一幅图说明帧、消息、流和连接的关系:
TCP 协议本身更适合用来长时间传输大数据,这样它的稳定和可靠性才能显露出来。HTTP/1 时代太多短而小的 TCP 连接,反而更多地将 TCP 的缺点给暴露出来了。
HTTP/1 的连接
在 HTTP/1 中,每一个请求和响应都要占用一个 TCP 连接,尽管有 Keep-Alive 机制可以复用,但在每个连接上同时只能有一个请求 / 响应,这意味着完成响应之前,这个连接不能用于其他请求(怎么判断响应是否结束,可以看这里)。如果浏览器需要向同一个域名发送多个请求,需要在本地维护一个 FIFO 队列,完成一个再发送下一个。这样,从服务端完成请求开始回传,到收到下一个请求之间的这段时间,服务端处于空闲状态。
后来,人们提出了 HTTP 管道(HTTP Pipelining)的概念,试图把本地的 FIFO 队列挪到服务端。它的原理是这样的:浏览器一股脑把请求都发给服务端,然后等着就可以了。这样服务端就可以在处理完一个请求后,马上处理下一个,不会有空闲了。甚至服务端还可以利用多线程并行处理多个请求。可惜,因为 HTTP/1 不支持多路复用,这个方案有几个棘手的问题:
服务端收到多个管道请求后,需要按接收顺序逐个响应。如果恰好第一个请求特别慢,后续所有响应都会跟着被阻塞。这种情况通常被称之为「队首阻塞(Head-of-Line Blocking)」;
服务端为了保证按顺序回传,通常需要缓存多个响应,从而占用更多的服务端资源,也更容易被人攻击;
浏览器连续发送多个请求后,等待响应这段时间内如果遇上网络异常导致连接被断开,无法得知服务端处理情况,如果全部重试可能会造成服务端重复处理;
另外,服务端和浏览器之间的中间代理设备也不一定支持 HTTP 管道,这给管道技术的普及引入了更多复杂性;
基于这些原因,HTTP 管道技术无法大规模使用,我们需要寻找其他方案。实际上,在 HTTP/1 时代,连接数优化不外乎两个方面:开源和节流。
开源
这里说的开源,当然不是「Open Source」那个开源。既然一个 TCP 连接同时只能处理一个 HTTP 消息,那多开几条 TCP 连接不就解决这个问题了。是的,浏览器确实是这么做的,HTTP/1.1 初始版本中允许浏览器针对同一个域名同时创建两个连接,在修订版(rfc7230)中更是去掉了这个限制。实际上,现代浏览器一般允许同域名并发 6~8 个连接。这个数字为什么不能更大呢?实际上这是出于公平性的考虑,每个连接对于服务端来说都会带来一定开销,如果浏览器不加以限制,一个性能好带宽足的终端就可能耗尽服务端所有资源,造成其他人无法使用。
但是,现在包含几十个 CSS、JSS,几百张图片的页面大有所在。为了进一步榨干浏览器,开更多的源,往往我们还会对静态资源做域名散列,将页面静态资源分散在多个子域下加载。多域名能提高并发连接数,也会带来很多问题,例如:
如果同一资源在不同页面被散列到不同子域下,会导致无法利用之前的 HTTP 缓存;
每个域名的第一个连接都要经历 DNS 解析的过程,这在移动端可能需要耗费几百毫秒;
更多的并发连接 + Keep-Alive 机制,会显著增加服务端和客户端的负担;
这里稍微吐槽下:本地 TCP 连接和本地端口也是一种资源,为了做 WEB 性能优化,开更多的域名让浏览器创建更多的并发连接,是很霸道和不公平的做法。
另外,HTTP/1 协议头部使用纯文本格式,没有任何压缩,且包含很多冗余信息(例如 Cookie、UserAgent 每次都会携带),所以一个页面的请求数越多,头部带来的额外开销就越大。我们一般会用短小且独立的域名来托管静态资源,就是为了减小这个开销(域名越短请求头起始行的 URI 就越短,独立域名不会共享主域的 Cookie,可以有效减小请求头大小,这个策略一般称之为 Cookie-Free Domain)。
节流
由于我们不能无限制开源,所以节流也很重要。除了砍掉页面内容,第二次访问时利用 HTTP 缓存之外,通常能做的就只有合并请求了。根据合并的内容不同,一般又分为以下几种:
异步接口合并(Batch Ajax Request);
图片合并,雪碧图(CSS Sprite);
CSS、JS 合并(Concatenation);
CSS、JS 内联(Inline);
图片、音频内联(Data URI);
上面这份列表并不完整,我也没打算列全,这些就足以说明 HTTP/1 时代我们在性能上所做过的不懈努力了。可惜,他们并不完美,分别列举一下他们的缺点:
异步接口合并:批量接口返回的时间受木桶效应影响,最慢的那个接口拖累了其他接口。
图片合并:首先,为了显示一张小图,而不得不加载合并后的整张大图,一是可能浪费流量;二是占用更多内存。其次,合并图片中任何一处修改,都会导致整张大图缓存失效。这些问题可以根据不同场景,选用 Data URI、Icon Font、SVG 等技术来改造。另外,雪碧图的生成和维护都比较繁琐,最好使用工具自动管理。
CSS、JS 合并:合并后的资源需要整体加载完才开始解析、执行。原本加载完一个文件就可以解析并执行一个,将很多个文件合并成一个巨无霸,会整体推后可用时间。为此,Chrome 新版引入了 Script Streaming 技术,能边加载边解析 JS 文件。Gmail 为了解决这个问题,将多个 JS 文件合并为一个由多个 inline script 片段组成的 html,用 iframe 引入,以达到边加载变解析执行的效果。另外,与图片合并类似,CSS、JS 合并也会遇到「无论多小的改动,都会导致整个合并文件缓存失效」的问题。
CSS、JS 内联:上篇文章我详细分析过内联的优点和弊端。主要两个问题:1)无法利用缓存;2)多页面无法共享。
图片、音频内联:除了也有上面两个问题之外,二进制文件以 Data URI 方式内联,需要进行 Base64 编码,体积会变大 1/3。
结论
HTTP/1 时代,我们为了节省昂贵的 HTTP 连接(TCP 连接),采用了各种优化手段,这些方案或多或少会引入一些问题,但是相比收益来说还是值得做,也应该做。但是,有了 HTTP/2 的多路复用和头部压缩,HTTP 连接变得可以随心所欲了,本文提到的这些连接数优化手段确实可以退休了。
哦对了,据官方预测,HTTP/1 至少还需要 10 年才能彻底退出历史舞台,另外尽管 HTTP/2 协议允许脱离 TSL 部署,但 Chrome 和 Firefox 都表示不支持非 TLS 的 HTTP/2,之后很可能一个网站会同时提供 HTTP/1.1、HTTP/1.1 over TLS、HTTP/2 over TLS 三种服务。如何在每种情况下,都能给用户提供最好的体验,需要更加深入的优化研究和更加精细的优化策略。由此可见,在很长一段时间内,WEB 性能优化非但不会落幕,反而会更加重要。