简介
近年来,随机森林模型在界内的关注度与受欢迎程度有着显著的提升,这多半归功于它可以快速地被应用到几乎任何的数据科学问题中去,从而使人们能够高效快捷地获得***组基准测试结果。在各种各样的问题中,随机森林一次又一次地展示出令人难以置信的强大,而与此同时它又是如此的方便实用。
需要大家注意的是,在上文中特别提到的是***组测试结果,而非所有的结果,这是因为随机森林方法固然也有自己的局限性。在这篇文章中,我们将向你介绍运用随机森林构建预测模型时最令人感兴趣的几个方面。
随机森林的发展史
谈及随机森林算法的产生与发展,我们必须回溯到20世纪80年代。可以说,该算法是Leo Breiman, Adele Cutler, Ho Tin Kam, Dietterich, Amit和Geman这几位大师呕心沥血的共同结晶,他们中的每个人都对随机森林算法的早期发展作出了重要的贡献。Leo Breiman和 Adele Cutler最早提出了执行随机森里的关键算法,这一算法也成为了他们的专利之一。Amit, Gemen和Ho Tim Kam各自独立地介绍了特征随即选择的思想,并且运用了Breiman的“套袋”思想构建了控制方差的决策树集合。在此之后,Deitterich在模型中引入了随即节点优化的思想,对随机森里进行了进一步完善。
什么是随机森林?
随机森林是一种多功能的机器学习算法,能够执行回归和分类的任务。同时,它也是一种数据降维手段,用于处理缺失值、异常值以及其他数据探索中的重要步骤,并取得了不错的成效。另外,它还担任了集成学习中的重要方法,在将几个低效模型整合为一个高效模型时大显身手。
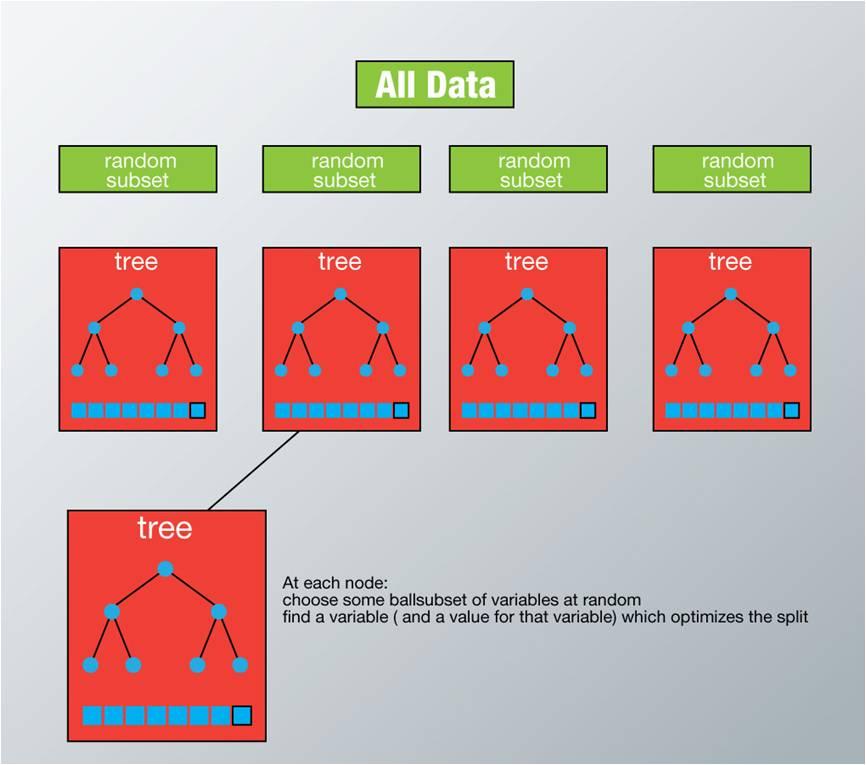
在随机森林中,我们将生成很多的决策树,并不像在CART模型里一样只生成唯一的树。当在基于某些属性对一个新的对象进行分类判别时,随机森林中的每一棵树都会给出自己的分类选择,并由此进行“投票”,森林整体的输出结果将会是票数最多的分类选项;而在回归问题中,随机森林的输出将会是所有决策树输出的平均值。
随机森林在Python和R中的实现
随机森林在R packages和Python scikit-learn中的实现是当下非常流行的,下列是在R和Python中载入随机森林模型的具体代码:
Python
#Import Libraryfromsklearn.ensemble import RandomForestClassifier #use RandomForestRegressor for regression problem#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset# Create Random Forest objectmodel= RandomForestClassifier(n_estimators=1000)# Train the model using the training sets and check scoremodel.fit(X, y)#Predict Outputpredicted= model.predict(x_test)
R Code
library(randomForest)x<- cbind(x_train,y_train)# Fitting modelfit<- randomForest(Species ~ ., x,ntree=500)summary(fit)#Predict Outputpredicted= predict(fit,x_test)
好了,现在我们已经了解了运行随机森林算法的代码,接下来让我们看看这个算法本身的运作方式是什么样的吧!
#p#
随机森林算法是如何工作的?
在随机森林中,每一个决策树“种植”和“生长”的规则如下所示:
1.假设我们设定训练集中的样本个数为N,然后通过有重置的重复多次抽样来获得这N个样本,这样的抽样结果将作为我们生成决策树的训练集;
2.如果有M个输入变量,每个节点都将随机选择m(m<M)个特定的变量,然后运用这m个变量来确定***的分裂点。在决策树的生成过程中,m的值是保持不变的;
3.每棵决策树都***可能地进行生长而不进行剪枝;
4.通过对所有的决策树进行加总来预测新的数据(在分类时采用多数投票,在回归时采用平均)。
随机森林的优点与缺点
优点:
1.正如上文所述,随机森林算法能解决分类与回归两种类型的问题,并在这两个方面都有相当好的估计表现;
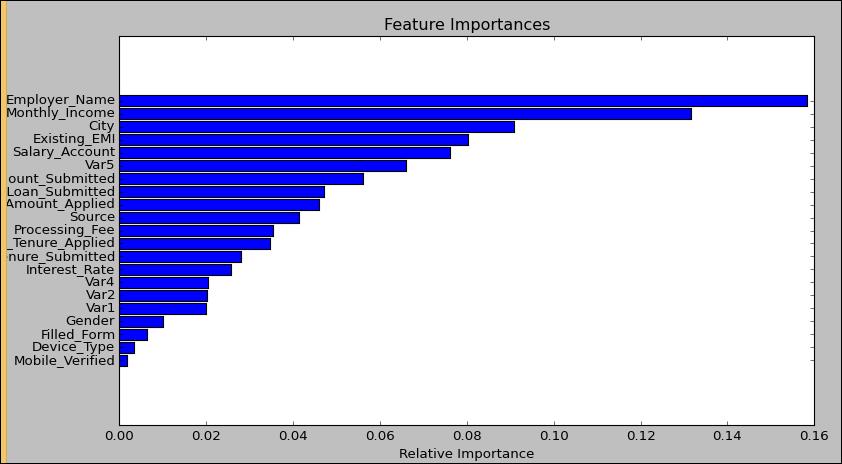
2.随机森林对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出变量的重要性程度,这是一个非常便利的功能。下图展示了随机森林对于变量重要性程度的输出形式:
3.在对缺失数据进行估计时,随机森林是一个十分有效的方法。就算存在大量的数据缺失,随机森林也能较好地保持精确性;
4.当存在分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法;
5.模型的上述性能可以被扩展运用到未标记的数据集中,用于引导无监督聚类、数据透视和异常检测;
6.随机森林算法中包含了对输入数据的重复自抽样过程,即所谓的bootstrap抽样。这样一来,数据集中大约三分之一将没有用于模型的训练而是用于测试,这样的数据被称为out of bag samples,通过这些样本估计的误差被称为out of bag error。研究表明,这种out of bag方法的与测试集规模同训练集一致的估计方法有着相同的精确程度,因此在随机森林中我们无需再对测试集进行另外的设置。
缺点:
1.随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
2.对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
调整随机森林模型中的参数
到目前为止,我们已经对整个随机森林模型进行了基本的了解,与此同时,对于模型中各种参数的调整与修改也十分重要,下列为python scikit-learn中随机森林模型的语法:
classsklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,max_leaf_nodes=None,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0,warm_start=False, class_weight=None)
具体的参数说明这里不再赘述,大家可以到scikit-learn.org的3.2.4.3.1章节进行查看。

这些参数在调节随机森林模型的准确性方面起着至关重要的作用。科学地使用这些指标,将能显著的提高模型工作效率。