2015年8月29日由七牛公司举办为期两天主题为—数据重构未来的七牛·数据时代峰会在上海国际时尚中心。本次大会邀请国内外知名数据专家、互联网行业、传统行业数据大咖亲临现场,带来一场有关数据的饕餮盛宴。
芒果TV依托湖南广电的内容、用户资源在2014年迅速成长,同年 7月5日周点击量超过1.7亿。本次七牛数据时代峰会特别邀请芒果TV数据负责人彭哲夫分享芒果TV数据处理实践分享。
以下是演讲实录:
芒果TV团队从去年开始筹建,现在有十个人,150多个节点,通过数据1.5PB。整体分为三个业务系统分别是数据魔方—负责一些重要指标的统计。第二是系统推荐,是芒果TV 将流量进行转化引导。第三是视频内容分析系统,很多互联网的数据可以转化成传统媒体需要的数据,因此芒果TV将一些用户的记录可以提供给导演来提供精彩的内容或者剧情发展。
现在芒果TV的数据部门支撑了70%-80%的业务,而今天的演讲也分为三个部分:***是基础篇,第二是整合篇,第三是数据管理篇。
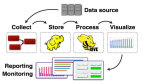
采集是数据的生产方,决定了数据是否可用,而在做搜集时我们会关注一下宽带成本,作为一家视频公司,宽带和版权是成本构成的重要部分。因此我们自己开发了一个SDK把采集到的数据发送到我们自定义的系统上,再进行分类一块发到FDS上,最终会转化成数据,形成数据库。
在实时计算方面,主要是用于播放过程中质量监控。我们回到ES里面去做一些即时查询。
在采集过程中会列出一个元素然后调用一个方法,然后把所有的参数传送给服务商,但是弊端在于随着采集点的增多,代码需要维护,而且缺少系统性。因此我们做了一个抽象,在采集过程中机型一次分类,比如页面数据、错误数据、播放数据。
另外就是事件问题,事件因为什么处罚?我们通过后端配置把一个元素的名称和事件整合起来在页面加载的时候,会把这一块的配置加载到后端页面,后端会根据这些加载的配置来决定什么数据需要上报,什么不需要上报。
如果我们需要一个很长的开发周期,使用这个模式时我们只需要在后台进行一个配置,数据马上就会过来了。搜集方面,一般采用的是放一个像素的图片吧一些参数带到这个图片后面,但是这种方式会造成宽带成本非常大,光搜索宽带会占到600兆左右。为了把服务器资源降低到极值,可以改为PT进行篡数。这样可以节省接近三分二的带宽成本。
在传输方面我们遇到了一些坑,最重要的问题是占用资源过大,实际上我们队每一块进行具体分析也不难解决这个问题。
在数据量过大时我们会遇到一些情况,主要是在于每隔一段时间会建一个文件夹,然而在测试时,时间就要长的很多。所以我们对其做了一个调整,使用单线程的方式做了一个很不错的优化,当到了1.5 1.6之后会直接导致系统内存膨胀的厉害,所以我们一般会加一条配置参数或者直接把位置进行改掉。
在一般类型文件和文件夹之间选择,主要考虑效率问题,之前有人提出将二者综合在数据量高的情况下使用文件。在写FTX时会导致文件进入关闭的状态,会导致我们错误失败,我们需要进行监控。另外可能会产生很多小文件会造成比较大的压力。因为是大数据,数据量不言而喻我们使用的压缩方式可以压缩80%的数据量。
在队列传输方面,我们只要使用Kafka,在实践中来看,并不是分区越多越好,如果分区越多,客户端和服务端所使用的内存限制也就越多,一个分区会产生两个文件,这两个文件会导致具体数量增加,而且Kafka本身的机制—kafka里面有一个页面分区,会产生投票过程分区越多时间越长会影响使用。
我们的做法是:选择一台机器只创建一个分区,然后测试产生和消费的情况如何,我们最关心的是吞吐量,所以TP和TC的***值可以做我们的分区。
在存储这一块,我们用的是多级存储方式,当然遇到的问题在于,当数据量增加时,很多冷数据在里边,工作压力会比较大。所以我们会分成三级,主要特点是CPU和内存会比较丰富一点,还可以减少副本以及把冷数据丢到云存储上面。
在存储方面另外一个问题就是压缩,在前期没有规划好时,我发现存储空间已经不够用了,我们会根据自己的业务进行选择,使用归档日志对小文件进行整理。
在配置方面,我们会把配置整合起来,进行推送,主要是基于RPC的控制模型,对所有的组进行全员的控制。我们的数据服务平台需要支持公司的很多业务他们只需要一个账号就可以进行我们采集服务器的传输服务、实时计算服务,我们也提供资源流量监控服务……
主要说一下我们如何在平台上管理数据。只要分为几个部分。一时日志种类的抽象,这和公司的业务息息相关,我们将日志进行分类—播放类日志、广告类日志。在这其中有一个特别有意思的地方,在芒果TV更关心PV VV这些核心指标,但是如果我们的计算指标的方式和其他同行不一样,这个数据在行业内就没有可对比性。所以会从几个方面去定义:一个是它的概念—运用的常理,如何上报,会导致什么样的结果。
***上报内容和计算公式,数据到了平台以后最重要的就是对数据进行管理,为什么要做管理?其实是为了把数据进行分门别类,随之产生的就是主题式管理—以某一个点为核心,在必须关注的方面我们再次进行分类,这个方式与我们的日志抽象非常相似。
在数据仓库建立之后,别人需要使用你的仓库数据们需要一个明细,需要做一个数据的数据。这个元数据分为两类,一类是技术性元数据主要给开发人员使用,包括一些仓库结构,以及原始性抽取的一些规则,不然的话数据毫无质量可言。
***为什么需要数据集市?在这个过程中,每一个公司会有很多业务部门,每一个业务部门面临的问题是不一样的,比如从统计角度,会更关注哪些数据。但是如果这样数据仓库是没法稳定的。因此需要数据集市进行隔离,在这个过程中我们可以把数据抽出来进行一些队列,放到我们的关系成本里,这些集市之间的结果是可以互相分享和交换的,更重要的是在于事实表和维表的管理和维护。