美国著名科技历史学家梅尔文?克兰兹伯格(Melvin Kranzberg),曾提出过大名鼎鼎的科技六定律,其中第三条定律是这样的[1]:“技术是总是配“套”而来的,但这个“套”有大有小(Technology comes in packages, big and small)”。
这个定律用在当下,是非常应景的。因为,我们正步入一个“大数据(big data)”时代,但对于以往的“小数据(small data)”,我们能做到“事了拂衣去,深藏身与名”吗?答案显然不是。目前,大数据的前途似乎“星光灿烂”,但小数据的价值依然“风采无限”。克兰兹伯格的第三定律是告诉我们,新技术和老技术的自我革新演变,是交织在一起的。大数据和小数据,他们“配套而来”,共同勾画数据技术(Data Technology,DT)时代的未来。
对大数据的“溢美之词”,已被舍恩伯格教授、涂子沛先生等先行者及其追随者夸得泛滥成灾。但正如您所知,任何事情都有两面性。在众人都赞大数据很好的时候,我们也需说道说道大数据可能面临的陷阱,只是为了让大数据能走得更稳。当在大数据的光晕下,渐行渐远渐无小数据时,我们也聊聊小数据之美,为的是“大小并行,不可偏废”。大有大的好,小有小的妙,如同一桌菜,哪道才是你的爱?思量三番再下筷。
下文部分就是供读者“思量”的材料,主要分为4个部分:(1)哪个V才是大数据最重要的特征?在这一部分里,我们聊聊大数据的4V特征中,哪个V才是大数据最贴切的特征,这是整个文章的行文基础。(2)大数据的力量与陷阱。在这一部分,我们聊聊大数据整体的力量之美及可能面临的3个陷阱。(3)今日王谢堂前燕,暂未飞入百姓家,在这一部分,我们要说明,大数据虽然很火,但我们用数据发声,用事实说话,大数据真的没有那么普及,小数据目前还是主流。(4)你若安好,便是晴天。在这一部分,我们说说的小数据之美,如果用“n=all”来代表大数据,那么就可以用“n=me”来说明小数据(这里n表示数据大小),我们将会看到,小数据更是关系到我们的切身利益。
1.哪个V才是大数据最重要的特征?
在谈及大数据时,人们通常用4V来描述其特征,即4个以V为首字母的英文:Volume(大量)、Variety(多样)、Velocity(速快)及Value(价值)。如果 “闲来无事”,我们非要对这4个V在“兵器谱”上排排名,哪个才是大数据的贴切的特征呢?下面我们简要地说道说道,力图说出点新意,分析的结果或许会出乎您的意料之外。
1.1 “大”有不同——Volume(大量)
首先我们来说说大数据的第一个V——Volume(大量)。虽然数据规模巨大且持续保持高速增长,通常作为大数据的第一个特征。但事实上,早在20年前,在当时的IT环境下,天文、气象、高能物理、基因工程等领域的科研数据量,已是这些领域无法承受的“体积”之痛,当时实时计算的难度不比现在小,因为那时的存储计算能力差,亦没有成熟的云计算架构和充分的计算资源。
况且,“大”本身就是一个相对的概念,数据的大与小,通常都打着很强的时代烙印。为了说明这个观点,让我们先回顾一下比尔?盖茨的经典“错误”预测。

图1 比尔▪盖茨于1981年对内存大小的预测
早在1981年,作为当时的IT精英,比尔?盖茨曾预测说,“640KB的内存对每个人都应该足够了(640KB ought to be enough for anybody)”。但30多年后的今天,很多人都会笑话盖茨,这么聪明的人,怎么会预测地如此不靠谱,现在随便一个智能手机(或笔记本电脑)的内存的大小都是4GB、8GB的。
但是,需要注意的事实是,在1981年,当时的个人计算机(PC)是基于英特尔CPU 8088芯片的,这种CPU是基于8/16位(bit)混合构架的处理器,因此,640KB已经是这类CPU所能支持的寻址空间的理论极限(64KB)的 10倍[2],换句话说,640K在当时是非常非常地庞大了!再回到现在,当前PC机的CPU基本都是64bit的,其理论支持的寻址空间是2^64,而现在的4G内存,仅仅是理论极限的(2^32)/(2^64)= 1/(2^32)而!。
在这里,讲这个小故事的原因在于,衡量数据大小,不能脱离时代背景,不能脱离行业特征。此外,大数据布道者舍恩伯格教授在其著作《大数据时代》中指出[3],大数据在某种程度上,可理解为“全数据(即n=all)”。有时,一个所谓的“全”数据库,并不需要有以TB/PB计的数据。在有些案例中,某个“全”数据库大小,可能还不如一张普通的仅有几个兆字节(MB)数码照片大,但相对于以前的“部分”数据,这个只有几个兆字节(MB)大小的“全”数据,就是大数据。故此,大数据之“大”,取义为相对意义,而非绝对意义。
这样看来,互联网巨头的PB级数据,可算是大数据,几个MB的全数据也可算是大数据,如此一来,大数据之“大”——“大”有不同,可大可小,如此不“靠谱”,反而不能算作大数据最贴切的特征。
1.2 数据共征——“Velocity(快速)”与“Value(价值)”
英特尔中国研究院院长吴甘沙先生曾指出,大数据的特征“Velocity(快速)”,犹如“天下武功,唯快不破”一样,要讲究个“快”字。为什么要“快”?因为时间就是金钱。如果说价值是分子,那么时间就是分母,分母越小,单位价值就越大。面临同样大的数据“矿山”,“挖矿”效率是竞争优势。
不过,青年学者周涛教授却认为[4],1秒钟算出来根本就不是大数据的特征,因为“算得越快越好”,是人类自打有计算这件事情以来,就没有变化过,而现在,却把它作为一个新时代的主要特征,完全是无稽之谈。笔者也更倾向于这个说法,把一个计算上的“通识”要求,算作一个新生事物的特征,确实欠妥。
类似不妥的还有大数据的另外一个特征——Value(价值)。事实上,“数据即价值”的价值观古来有之。例如,在《孙子兵法?始计篇》中,早就有这样的论断“多算胜,少算不胜,而况于无算乎?”此处 “算”,乃算筹也,也就是计数用的筹码,它讲得就是,如何利用数字,来估计各种因素,从而做出决策。
在马陵之战中,孙膑通过编造“齐军入魏地为十万灶,明日为五万灶,又明日为三万灶(史记·孙子吴起列传)”的数据,利用庞涓的数据分析习惯,反其道而用之,对庞涓实施诱杀。
话说还有一个关于林彪将军的段子(真假不可考),在辽沈战役中,林大将军通过分析缴获的短枪与长枪比例、缴获和击毁小车与大车比例,以及俘虏和击毙的军官与士兵的比例“异常”,因此得出结论,敌人的指挥所就在附近!果不其然,通过追击从胡家窝棚逃走的那部分敌人,活捉国民党主帅新六军军长廖耀湘。
在战场上,数据的价值——就是辅助决策来获胜。还有一点值得注意的是,在上面的案例中,战场上的数据,神机妙算的军师们,都能“掐指一算”——这显然属于十足的小数据!但网上却流传有很多诸如“林彪也玩大数据”、“跟着林彪学习大数据”等类似的文章,这就纯属扯淡了。如果凡是有点数据分析思维的案例,都归属于大数据的话,那大数据的案例,古往今来,可真是数不胜数了。
因此,Value(价值)实在不能算是大数据专享的特征,“小数据”也是有价值的。在下文第4节的分析中,我们可以看到,小数据对个人而言,“价值”更是不容小觑。这样一来,如果大、小数据都有价值,何以“价值”成为大数据的特征呢?事实上,睿智的IBM,在对大数据的特征概括中,压根就没有“Value”这个V(如图2所示)。
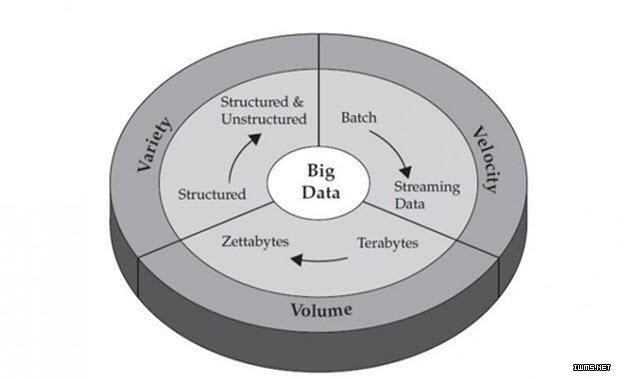
图2 IBM公司给出的大数据3V特征
我们知道,所谓“特征”者,乃事物异于它物之特点”。打个比方,如果我们说“有鼻子有眼是男人的特征”,您可能就会觉得不妥:“难道女人就没有鼻子没有眼睛吗?”是的,“有鼻子有眼”是男人和女人的“共征”,而非“特征”。同样的道理,Velocity 和Value这两个V字头词汇,是大、小数据都能有的“共征”, 实在也不算不上是大数据最贴切的特征。
1.3五彩缤“纷”——Variety(多样)
通常认为,大数据的多样性(Variety),是指数据种类多样。其最简单的种类划分,莫过于分为两大类:结构化的数据和非结构化数据,现在“非结构化数据”占到整个数据比例的70%~80%。早期的非结构化数据,在企业数据的语境里,可以包括诸如电子邮件、文档、健康、医疗记录等非结构化文本。随着互联网和物联网(Internet of things,IoT)的快速发展,现在的非结构化数据又扩展到诸如网页、社交媒体、音频、视频、图片、感知数据等,这诠释了数据的形式多样性。
但倘若深究下去,就会发现,“非结构化”未必就是个成立的概念。在信息中,“结构化”是永存的。而所谓的“非结构化”,不过是某些结构尚未被人清晰的描述出来而已。美国IT咨询公司Alta Plana的高级数据分析师Seth Grimes曾在IT领域著名刊物《信息周刊》(Information Week)撰文指出:不存在所谓的非结构化,现在所说的“非结构化”,应该是非模型化(unmodeled),结构本在,只是人们处理数据的功力未到,未建模而已(Most unstructured data is merely unmodeled)[5](如图3所示)。
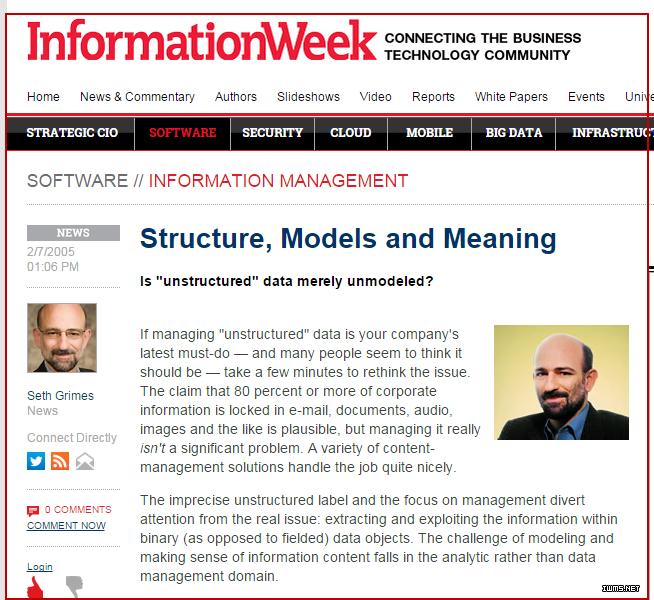
图3 Seth Grimes:非结构化乎,不!应是非建模
大数据的多样性(Variety),还体现在数据质量的参差不齐上。换句话说,这个语境下的多样性就是混杂性(Messy),即数据里混有杂质(或称噪音)。大数据的混杂性,基本上是不可避免的,既可能是数据产生者在产生数据过程出现了问题,也可能是采集或存储过程存在问题。如果这些数据噪音是偶然的,那么在大数据中,它一定会被更多的正确数据淹没掉,这样就使得大数据具备一定的容错性;如果噪音存在规律性,那么在具备足够多的数据后,就有机会发现这个规律,从而可有规律的“清洗数据”,把噪音过滤掉。吴甘沙先生认为[15],多元抑制的数据,能够过滤噪声、去伪存真,即为辩讹。更多有关混杂性的精彩描述,读者还可批判性地参阅舍恩伯格教授的大著《大数据时代》[3]。
事实上,大数据的多样性(Variety),最重要的一面,还是表现在数据的来源多和用途多上。每一种数据来源,都有其一定的片面性和局限性,只有融合、集成多方面的数据,才能反映事物的全貌。事物的本质和规律隐藏在各种原始数据的相互关联之中。对同一个问题,不同的数据能提供互补信息,可对问题有更为深入的理解。因此在大数据分析中,汇集尽量多种来源的数据是关键。中国工程院李国杰院士认为[6],这非常类似于钱学森老先生提出的“大成智慧学”,“必集大成,才能得智慧”。
著名历史学家许倬云先生,站在历史的高度,也给出了自己的观点,他说“大数据”之所以能称之为“大数据”,就在于,其将各种分散的数据,彼此联系,由点而线,由线而面,由面而层次,以瞻见更完整的覆盖面,也更清楚地理解事物的本质和未来取向。
英国数学家及人类学家托马斯·克伦普(Thomas Crump)在其著作《数字人类学》The(Anthropology of Numbers)指出[7],数据的本质是人,分析数据就是在分析人类族群自身,数据背后一定要还原为人。东南大学知名哲学教授吕乃基先生认为[8],虽然每个数据来源因其单项而显得模糊,然而由“无限的模糊”所带来的聚焦成像,会比“有限的精确”更准确。“人是社会关系的总和(马克思语)”。 大数据利用自己的“多样性”,比以往任何时候都趋于揭示这样的“总和”。
因此,李国杰院士认为[6],数据的开放共享,提供了多种来源的数据融合机会,它不是锦上添花的事,而是决定大数据成败的必要前提。
从上分析可见,虽然大数据有很多特征(甚至有人整出个11个V来),但大数据的多样性(Variety),无疑它是区分以往小数据的最重要特征。