我们有无数方法可用于删除字符串中的所有空白,但是哪个更快呢?
介绍
我们有无数方法可用于删除字符串中的所有空白。大部分都能够在绝大多数的用例中很好工作,但在某些对时间敏感的应用程序中,是否采用最快的方法可能就会造成天壤之别。
如果你问空白是什么,那说起来还真是有些乱。许多人认为空白就是SPACE 字符(UnicodeU+0020,ASCII 32,HTML ),但它实际上还包括使得版式水平和垂直出现空格的所有字符。事实上,这是一整类定义为Unicode字符数据库的字符。
本文所说的空白,不但指的是它的正确定义,同时也包括string.Replace(” “, “”)方法。
这里的基准方法,将删除所有头尾和中间的空白。这就是文章标题中“所有空白”的含义。
背景
这篇文章一开始是出于我的好奇心。事实上,我并不需要用最快的算法来删除字符串中的空白。
检查空白字符
检查空白字符很简单。所有你需要的代码就是:
- char wp = ' ';
- char a = 'a';
- Assert.True(char.IsWhiteSpace(wp));
- Assert.False(char.IsWhiteSpace(a));
- 但是,当我实现手动优化删除方法时,我意识到这并不像预期得那么好。一些源代码在微软的参考源代码库的char.cs挖掘找到:
- public static bool IsWhiteSpace(char c) {
- if (IsLatin1(c)) {
- return (IsWhiteSpaceLatin1(c));
- }
- return CharUnicodeInfo.IsWhiteSpace(c);
- }
- 然后CharUnicodeInfo.IsWhiteSpace成了:
- internal static bool IsWhiteSpace(char c)
- {
- UnicodeCategory uc = GetUnicodeCategory(c);
- // In Unicode 3.0, U+2028 is the only character which is under the category "LineSeparator".
- // And U+2029 is th eonly character which is under the category "ParagraphSeparator".
- switch (uc) {
- case (UnicodeCategory.SpaceSeparator):
- case (UnicodeCategory.LineSeparator):
- case (UnicodeCategory.ParagraphSeparator):
- return (true);
- }
- return (false);
- }
- GetUnicodeCategory()方法调用InternalGetUnicodeCategory()方法,而且实际上相当快,但现在我们依次已经有了4个方法调用!以下这段代码是由一位评论者提供的,可用于快速实现定制版本和JIT默认内联:
- // whitespace detection method: very fast, a lot faster than Char.IsWhiteSpace
- [MethodImpl(MethodImplOptions.AggressiveInlining)] // if it's not inlined then it will be slow!!!
- public static bool isWhiteSpace(char ch) {
- // this is surprisingly faster than the equivalent if statement
- switch (ch) {
- case '\u0009': case '\u000A': case '\u000B': case '\u000C': case '\u000D':
- case '\u0020': case '\u0085': case '\u00A0': case '\u1680': case '\u2000':
- case '\u2001': case '\u2002': case '\u2003': case '\u2004': case '\u2005':
- case '\u2006': case '\u2007': case '\u2008': case '\u2009': case '\u200A':
- case '\u2028': case '\u2029': case '\u202F': case '\u205F': case '\u3000':
- return true;
- default:
- return false;
- }
- }
删除字符串的不同方法
我用各种不同的方法来实现删除字符串中的所有空白。
分离合并法
这是我一直在用的一个非常简单的方法。根据空格字符分离字符串,但不包括空项,然后将产生的碎片重新合并到一起。这方法听上去有点傻乎乎的,而事实上,乍一看,很像是一个非常浪费的解决方式:
- public static string TrimAllWithSplitAndJoin(string str) {
- return string.Concat(str.Split(default(string[]), StringSplitOptions.RemoveEmptyEntries));
- }
- LINQ
- 这是优雅地声明式地实现这个过程的方法:
- public static string TrimAllWithLinq(string str) {
- return new string(str.Where(c => !isWhiteSpace(c)).ToArray());
- }
正则表达式
正则表达式是非常强大的力量,任何程序员都应该意识到这一点。
- static Regex whitespace = new Regex(@"\s+", RegexOptions.Compiled);
- public static string TrimAllWithRegex(string str) {
- return whitespace.Replace(str, "");
- }
字符数组原地转换法
该方法将输入的字符串转换成字符数组,然后原地扫描字符串去除空白字符(不创建中间缓冲区或字符串)。***,经过“删减”的数组会产生新的字符串。
- public static string TrimAllWithInplaceCharArray(string str) {
- var len = str.Length;
- var src = str.ToCharArray();
- int dstIdx = 0;
- for (int i = 0; i < len; i++) {
- var ch = src[i];
- if (!isWhiteSpace(ch))
- src[dstIdx++] = ch;
- }
- return new string(src, 0, dstIdx);
- }
字符数组复制法
这种方法类似于字符数组原地转换法,但它使用Array.Copy复制连续非空白“字符串”的同时跳过空格。***,它将创建一个适当尺寸的字符数组,并用相同的方式返回一个新的字符串。
public static string TrimAllWithCharArrayCopy(string str) {
var len = str.Length;
var src = str.ToCharArray();
int srcIdx = 0, dstIdx = 0, count = 0;
for (int i = 0; i < len; i++) {
if (isWhiteSpace(src[i])) {
count = i - srcIdx;
Array.Copy(src, srcIdx, src, dstIdx, count);
srcIdx += count + 1;
dstIdx += count;
len--;
}
}
if (dstIdx < len)
Array.Copy(src, srcIdx, src, dstIdx, len - dstIdx);
return new string(src, 0, len);
}
循环交换法
用代码实现循环,并使用StringBuilder类,通过依靠StringBuilder的内在优化来创建新的字符串。为了避免任何其他因素对本实施产生干扰,不调用其他的方法,并且通过缓存到本地变量避免访问类成员。***通过设置StringBuilder.Length将缓冲区调整到合适大小。
// Code suggested by http://www.codeproject.com/Members/TheBasketcaseSoftware
public static string TrimAllWithLexerLoop(string s) {
int length = s.Length;
var buffer = new StringBuilder(s);
var dstIdx = 0;
for (int index = 0; index < s.Length; index++) {
char ch = s[index];
switch (ch) {
case '\u0020': case '\u00A0': case '\u1680': case '\u2000': case '\u2001':
case '\u2002': case '\u2003': case '\u2004': case '\u2005': case '\u2006':
case '\u2007': case '\u2008': case '\u2009': case '\u200A': case '\u202F':
case '\u205F': case '\u3000': case '\u2028': case '\u2029': case '\u0009':
case '\u000A': case '\u000B': case '\u000C': case '\u000D': case '\u0085':
length--;
continue;
default:
break;
}
buffer[dstIdx++] = ch;
}
buffer.Length = length;
return buffer.ToString();;
}
循环字符法
这种方法几乎和前面的循环交换法相同,不过它采用if语句来调用isWhiteSpace(),而不是乱七八糟的switch伎俩 :)。
public static string TrimAllWithLexerLoopCharIsWhitespce(string s) {
int length = s.Length;
var buffer = new StringBuilder(s);
var dstIdx = 0;
for (int index = 0; index < s.Length; index++) {
char currentchar = s[index];
if (isWhiteSpace(currentchar))
length--;
else
buffer[dstIdx++] = currentchar;
}
buffer.Length = length;
return buffer.ToString();;
}
原地改变字符串法(不安全)
这种方法使用不安全的字符指针和指针运算来原地改变字符串。我不推荐这个方法,因为它打破了.NET框架在生产中的基本约定:字符串是不可变的。
public static unsafe string TrimAllWithStringInplace(string str) {
fixed (char* pfixed = str) {
char* dst = pfixed;
for (char* p = pfixed; *p != 0; p++)
if (!isWhiteSpace(*p))
*dst++ = *p;
/*// reset the string size
* ONLY IT DIDN'T WORK! A GARBAGE COLLECTION ACCESS VIOLATION OCCURRED AFTER USING IT
* SO I HAD TO RESORT TO RETURN A NEW STRING INSTEAD, WITH ONLY THE PERTINENT BYTES
* IT WOULD BE A LOT FASTER IF IT DID WORK THOUGH...
Int32 len = (Int32)(dst - pfixed);
Int32* pi = (Int32*)pfixed;
pi[-1] = len;
pfixed[len] = '\0';*/
return new string(pfixed, 0, (int)(dst - pfixed));
}
}
原地改变字符串法V2(不安全)
这种方法几乎和前面那个相同,不过此处使用类似数组的指针访问。我很好奇,不知道这两种哪种存储访问会更快。
public static unsafe string TrimAllWithStringInplaceV2(string str) {
var len = str.Length;
fixed (char* pStr = str) {
int dstIdx = 0;
for (int i = 0; i < len; i++)
if (!isWhiteSpace(pStr[i]))
pStr[dstIdx++] = pStr[i];
// since the unsafe string length reset didn't work we need to resort to this slower compromise
return new string(pStr, 0, dstIdx);
}
}
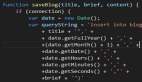
String.Replace(“”,“”)
这种实现方法很天真,由于它只替换空格字符,所以它不使用空白的正确定义,因此会遗漏很多其他的空格字符。虽然它应该算是本文中最快的方法,但功能不及其他。
但如果你只需要去掉真正的空格字符,那就很难用纯.NET写出胜过string.Replace的代码。大多数字符串方法将回退到手动优化本地C ++代码。而String.Replace本身将用comstring.cpp调用C ++方法:
FCIMPL3(Object*,
COMString::ReplaceString,
StringObject* thisRefUNSAFE,
StringObject* oldValueUNSAFE,
StringObject* newValueUNSAFE)
下面是基准测试套件方法:
public static string TrimAllWithStringReplace(string str) {
// This method is NOT functionaly equivalent to the others as it will only trim "spaces"
// Whitespace comprises lots of other characters
return str.Replace(" ", "");
}
许可证
这篇文章,以及任何相关的源代码和文件,依据The Code Project Open License (CPOL)的许可。
译文链接:http://www.codeceo.com/article/donet-remove-whitespace-string.html
英文原文:Fastest method to remove all whitespace from Strings in .NET