













如果我们在服务端存储文件,例如一个O2O应用中的图片或者企业级云盘里的文档,以前我们可能会毫不犹豫地把它们放到文件系统里,比如说NAS设备或者GlusterFS等分布式文件系统,但是,随着技术的发展,我们有了一个新的选择——对象存储,今天我们来讨论一下,对象存储相对于文件系统有什么特点?什么时候我们应该选择对象存储?文件系统将来的发展方向是什么?
一、对象存储的概念
对象存储和我们经常接触到的硬盘和文件系统等存储形态不同,它提供Key-Value(简称K/V)方式的RESTful数据读写接口,并且常以网络服务的形式提供数据的访问。
在早些年,特别是2006年以前,人们提到对象存储,往往指的是以类似标准化组织SNIA定义的OSD(object storage device)和MDS(Metadata Server)为基本组成部分的分布式存储,通常是分布式文件系统。我们经常听到的分布式存储Ceph的底层RADOS(Reliable Autonomous Distributed Object Store),即属于这类对象存储。
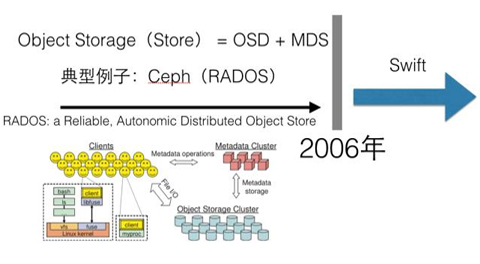
(图片部分内容引用自Ceph官网和SwiftStack)
而2006年以后,人们说到对象存储,往往指的是以AWS的S3为代表的,通过HTTP接口提供访问的存储服务或者存储系统。类似的系统还有Rackspace于2009年开始研发并于2010年开源的OpenStack Swift(Rackspace的对象存储服务开始于2008年,但是Swift项目的开发是从2009年开始的,Rackspace用Swift项目对其云存储系统进行了彻底重构)。这里的“对象”(Object)和我们平时说的文件类似,如果我们把一个文件传到对象存储系统里面存起来,就叫做一个对象。
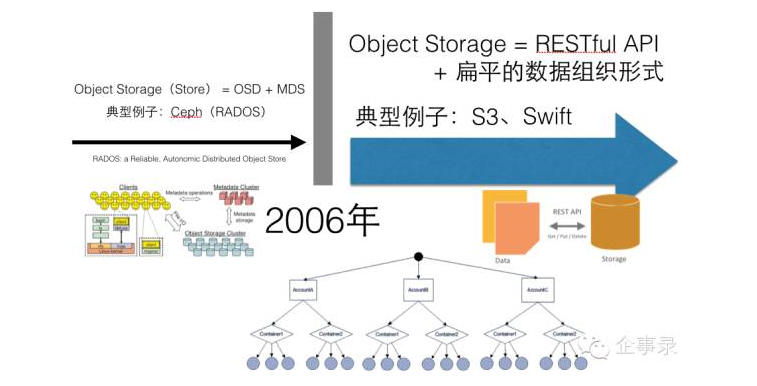
从另一个角度来说,2006年以前常说的对象存储,指的是一种存储系统的架构;而2006年以后,人们说到对象存储常指的是一种存储形态,我们这里讨论的对象存储也正是后者。
目前,对象存储已经得到了广泛的应用。具有代表性的大规模实现主要在各个公有云服务商,比如AWS的S3、Rackspace的CloudFiles,国内的七牛云存储、阿里云的开放存储服务OSS也属于对象存储,最近,青云也发布了对象存储服务。
对象存储也有一些著名的开源实现,如OpenStack Swift,开源的统一存储系统Ceph也可以通过Ceph Object Gateway提供对象存储服务,也称作RADOS Gateway,缩写为RADOSGW。
二、对象存储与文件系统的比较
与文件系统相比,以AWS S3和Swift为代表的对象存储有两个显著的特征——REST风格的接口和扁平的数据组织结构。
1、对象存储的接口
对于大多数文件系统来说,尤其是POSIX兼容的文件系统,提供open、close、read、write和lseek等接口。
而对象存储的接口是REST风格的,通常是基于HTTP协议的RESTful Web API,通过HTTP请求中的PUT和GET等操作进行文件的上传即写入和下载即读取,通过DELETE操作删除文件。
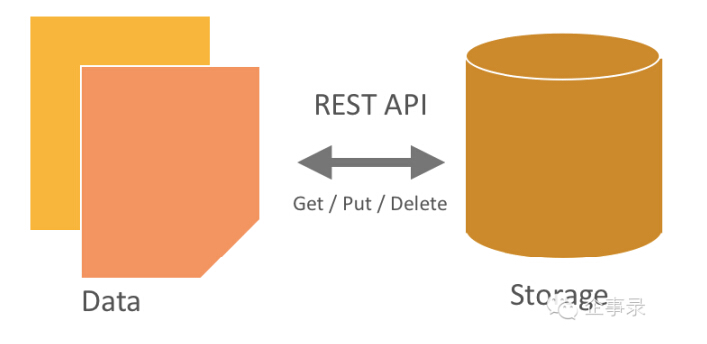
(图片内容来自SwiftStack)
对象存储和文件系统在接口上的本质区别是对象存储不支持和fread和fwrite类似的随机位置读写操作,即一个文件PUT到对象存储里以后,如果要读取,只能GET整个文件,如果要修改一个对象,只能重新PUT一个新的到对象存储里,覆盖之前的对象或者形成一个新的版本。
如果结合平时使用云盘的经验,就不难理解这个特点了,用户会上传文件到云盘或者从云盘下载文件。如果要修改一个文件,会把文件下载下来,修改以后重新上传,替换之前的版本。实际上几乎所有的互联网应用,都是用这种存储方式读写数据的,比如微信,在朋友圈里发照片是上传图像、收取别人发的照片是下载图像,也可以从朋友圈中删除以前发送的内容;微博也是如此,通过微博API我们可以了解到,微博客户端的每一张图片都是通过REST风格的HTTP请求从服务端获取的,而我们要发微博的话,也是通过HTTP请求将数据包括图片传上去的。在没有对象存储以前,开发者需要自己为客户端提供HTTP的数据读写接口,并通过程序代码转换为对文件系统的读写操作。
能够放弃随机读写接口而采用REST接口的一个重要原因是计算机系统本身的演进呼唤存储系统的变革,目前的计算机的内存大小已经和当初设计POSIX文件系统接口时大不一样了。文件系统诞生于1960年代,当时的内存是以KB为单位的,内存资源非常宝贵,同时外存的数据读写速率也非常低,所以把文件中的一小部分数据加载进内存进行操作显得非常有必要。而如今,计算机的内存是以GB为单位的,往往在几十、几百GB量级,而常常需要存取的文件——如图片、文档等,则是在MB级别,GB以上的文件数量非常少(多为长视频、归档文件、虚拟机镜像等,这一类数据我们会在本系列的后面几篇中进行讨论),外存和网络的吞吐率较之1960年代,也有了数千倍的提升,把一个文件完全加载到内存中进行处理和可视化的已经开销微不足道了,而带来的计算效率和用户体验的提升却是显著的。
#p#
2、扁平的数据组织结构
对比文件系统,对象存储的第二个特点是没有嵌套的文件夹,而是采用扁平的数据组织结构,往往是两层或者三层,例如AWS S3和华为的UDS,每个用户可以把它的存储空间划分为“容器”(Bucket),然后往每个容器里放对象,对象不能直接放到租户的根存储空间里,必须放到某个容器下面,而不能嵌套,也就是说,容器下面不能再放一层容器,只能放对象。OpenStack Swift也类似
这就是所谓“扁平数据组织结构”,因为它和文件夹可以一级一级嵌套不同,层次关系是固定的,而且只有两到三级,是扁平的。每一级的每个元素,例如S3中的某个容器或者某个对象,在系统中都有唯一的标识,用户通过这个标识来访问容器或者对象,所以,对象存储提供的是一种K/V的访问方式。
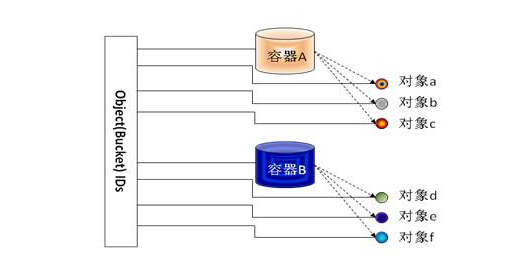
(图片内容来自华为)
采用扁平的数据组织结构抛弃了嵌套的文件夹,避免维护庞大的目录树。随着大数据和互联网的发展,如今的存储系统中,动辄数百万、千万甚至上亿个文件/对象,单位时间内的访问次数和并发访问量也达到了***的量级,在这种情况下,目录树会给存储系统带来很大的开销和诸多问题,成为系统的瓶颈。反观目录结构的初衷——数据管理,如今作用非常有限,我们已经很难通过目录的划分对文件进行归类和管理了,因为一个文件最终只能放到一个文件夹下,作为目录树的叶子节点存在,而文件的属性是多维度的。目前各类应用中广泛采用元数据检索的方式进行数据的管理,通过对元数据的匹配得到一个Index或者Key,再根据这个Index或者Key找到并读取数据,所以,对象存储的扁平数据组织形式和K/V访问方式更能满足数据管理的需求。
不难看出,对象存储有着鲜明的互联网和大数据时代的特点,随着“互联网+”的推进,互联网技术正在渗透到各行各业,数据量也在成指数倍数增长,对象存储将发挥越来越大的作用。
三、文件系统和对象存储系统的优劣和发展趋势分析
上述分析了对象存储的特点并与文件系统做了比较,接下来就不得不回答一个问题:文件系统是不是没有生命力了?答案当然是否定的。对象存储打破了文件系统一统天下的局面,给我们带来了更多的选择,并不意味着我们就要否定文件系统。
而对于一些场景,比如虚拟机活动镜像的存储,或者说虚拟机硬盘文件的存储,还有大数据处理等场景,对象存储就显得捉襟见肘了。而文件系统在这些领域有突出的表现,比如Nutanix的NDFS(Nutanix Distributed Filesystem)和VMware的VMFS(VMware Filesystem)在虚拟机镜像存储方面表现很出色,Google文件系统GFS及其开源实现HDFS被广泛用于支撑基于MapReduce模型的大数据处理支持得很好,而且能够很好地支持百GB级、TB级甚至更大文件的存储。
由此看来文件系统将来的发展趋势更多的是专用文件系统,而不再是像以前那样,以前一套Filesystem适用于所有场景,更有一些部分要让位于对象存储或者其他存储形态。
从另一个角度来看,现代对象存储系统的“甜区”在哪里:1. 互联网和类似互联网的应用场景,这不仅仅是因为REST风格的HTTP的接口,而且还因为大多数对象存储系统在设计上能够非常方便地进行横向扩展以适应大量用户高并发访问的场景;2. 海量十KB级到GB级对象/文件的存储,小于10KB的数据更适用于使用K/V数据库,而大于10GB的文件***将其分割为多个对象并行写入对象存储系统中,多数对象存储系统都有单个对象大小上限的限制。所以,如果应用具有上述两种特点,对象存储是***。
也有人在对象存储上做出进一步的开发或者改进,使其能够很好地支持归档备份、MapReduce大数据处理等场景,甚至将对象存储的接口转为文件系统接口;反之,OpenStack Swift等对象存储系统也支持使用GlusterFS等通用文件系统作为存储后端。人们为什么会在这些对象存储和文件系统相互转换的技术上进行人力和资金的投入?这些做法的意义何在?应该在什么时候使用这些技术?我们将在本系列的后续章节中给出答案。
本系列还将以OpenStack Swift为例来剖析对象存储的设计与实现,并且讨论对象存储在实际应用中所遇到的问题以及在Swift中是如何解决的,进而讨论对象存储的发展对底层硬件带来的挑战和机遇。另外,由于对象存储和传统存储形态的差别,性能评估已经不能以IOPS和读写速率等传统指标来衡量,应当如何对对象存储进行评估?我们也将在后续章节中进行探讨。












