hadoop是什么?hadoop能有哪些应用?hadoop和大数据是什么关系?下面我们将围绕这几个问题详细阐述。
hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
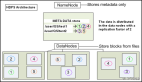
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
项目起源
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到***由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
Hadoop 是***的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
发展历程
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop 最初只与网页索引有关,迅速发展成为分析大数据的领先平台。
目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估。
Hadoop应用案例—全球著名企业应用案例
美国国会图书馆是全球***的图书馆,自1800年设立至今,收藏了超过1.5亿个实体对象,包括书籍、影音、老地图、胶卷等,数字数据量也达到了235TB,但美国eBay拍卖网站,8千万名用户每天产生的数据量就有50TB,5天就相当于1座美国国会图书馆的容量。
在国外,不只eBay这种跨国电子商务业者感受到巨量数据的冲击,其他如美国连锁超市龙头Wal-Mart、发行信用卡的Visa公司等,在台湾如台湾集成电路(台积电)、中华电信等手上拥有大量顾客资料的企业,都纷纷感受到这股如海啸般来袭的Big Data巨量资料浪潮。这样的巨量数据并非是没有价值的数据,其中潜藏了许多使用者亲身经验的***手原始数据,不少企业更是从中嗅到了商机。
这些企业纷纷向最早面临大数据挑战的搜索引擎业者Google、Yahoo取经,学习处理巨量数据的技术和经验,其中,最受这些企业青睐,用来解决巨量数据难题的技术就是Apache基金会的分布式计算技术Hadoop项目。
Hadoop应用案例1-全球***超市业者 Wal-Mart
Wal-Mart分析顾客商品搜索行为,找出超越竞争对手的商机
全球***连锁超市Wal-Mart利用Hadoop来分析顾客搜寻商品的行为,以及用户透过搜索引擎寻找到Wal-Mart网站的关键词,利用这些关键词的分析结果发掘顾客需求,以规画下一季商品的促销策略,甚至打算分析顾客在Facebook、Twitter等社交网站上对商品的讨论,期望能比竞争对手提前一步发现顾客需求。
Wal-Mart虽然十年前就投入在线电子商务,但在线销售的营收远远落后于Amazon。后来,Wal-Mart决定采用Hadoop来分析顾客搜寻商品的行为,以及用户透过搜索引擎寻找到Wal-Mart网站的关键词,利用这些关键词的分析结果发掘顾客需求,以规画下一季商品的促销策略。他们并进一步打算要分析顾客在Facebook、Twitter等社交网站上对商品的讨论,甚至Wal-Mart能比父亲更快知道女儿怀孕的消息,并且主动寄送相关商品的促销邮件,可说是比竞争对手提前一步发现顾客。
Hadoop应用案例2-全球***拍卖网站 eBay
eBay用Hadoop拆解非结构性巨量数据,降低数据仓储负载
经营拍卖业务的eBay则是用Hadoop来分析买卖双方在网站上的行为。eBay拥有全世界***的数据仓储系统,每天增加的数据量有50TB,光是储存就是一大挑战,更遑论要分析这些数据,而且更困难的挑战是这些数据报括了结构化的数据和非结构化的数据,如照片、影片、电子邮件、用户的网站浏览Log记录等。
eBay是全球***的拍卖网站,8千万名用户每天产生的数据量就达到50TB,相当于五天就增加了1座美国国会图书馆的数据量。这些数据报括了结构化的数据,和非结构化的数据如照片、影片、电子邮件、用户的网站浏览Log记录等。eBay正是用Hadoop来解决同时要分析大量结构化数据和非结构化的难题。
eBay分析平台高级总监Oliver Ratzesberger也坦言,大数据分析***的挑战就是要同时处理结构化以及非结构化的数据。
eBay在5年多前就另外建置了一个软硬件整合的平台Singularity,搭配压缩技术来解决结构化数据和半结构化数据分析问题,3年前更在这个平台整合了Hadoop来处理非结构化数据,透过Hadoop来进行数据预先处理,将大块结构的非结构化数据拆解成小型数据,再放入数据仓储系统的数据模型中分析,来加快分析速度,也减轻对数据仓储系统的分析负载。
Hadoop应用案例3-全球***信用卡公司 Visa
Visa快速发现可疑交易,1个月分析时间缩短成13分钟
Visa公司则是拥有一个全球***的付费网络系统VisaNet,作为信用卡付款验证之用。2009年时,每天就要处理1.3亿次授权交易和140万台ATM的联机存取。为了降低信用卡各种诈骗、盗领事件的损失,Visa公司得分析每一笔事务数据,来找出可疑的交易。虽然每笔交易的数据记录只有短短200位,但每天VisaNet要处理全球上亿笔交易,2年累积的资料多达36TB,过去光是要分析5亿个用户账号之间的关联,得等1个月才能得到结果,所以,Visa也在2009年时导入了Hadoop,建置了2套Hadoop丛集(每套不到50个节点),让分析时间从1个月缩短到13分钟,更快速地找出了可疑交易,也能更快对银行提出预警,甚至能及时阻止诈骗交易。
这套被众多企业赖以解决大数据难题的分布式计算技术,并不是一项全新的技术,早在2006年就出现了,而且Hadoop的核心技术原理,更是源自Google打造搜索引擎的关键技术,后来由Yahoo支持的开源开发团队发展成一套Hadoop分布式计算平台,也成为Yahoo内部打造搜索引擎的关键技术。
#p#
大数据与Hadoop之间的关系
大数据,一种新兴的数据挖掘技术,它正在让数据处理和分析变得更便宜更快速。大数据技术一旦进入超级计算时代,很快便可应用于普通企业,在遍地开花的过程中,它将改变许多行业业务经营的模式。但是很多人对大数据存在误解,下面就来缕一缕大数据与Hadoop之间的关系。
我们都听过这个预测:到2020年,电子数据存储量将在2009年的基础上增加44倍,达到35万亿GB。根据IDC数据显示,截止到2010年,这个数字已经达到了120万PB,或1.2ZB。如果把所有这些数据都存入DVD光盘,光盘高度将等同于从地球到月球的一个来回也就是大约 480,000英里。
对于那些喜欢杞人忧天的人来说,这是数据存储的末日即将到来的不祥预兆。而对于机会主义者们而言,这就好比是个信息金矿,随着技术的进步,金矿开采会变得越来越容易。
走进大数据,一种新兴的数据挖掘技术,它正在让数据处理和分析变得更便宜更快速。大数据技术一旦进入超级计算时代,很快便可应用于普通企业,在遍地开花的过程中,它将改变许多行业业务经营的模式。
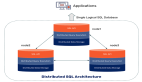
在计算机世界里,大数据被定义为一种使用非传统的数据过滤工具,对大量有序或无序数据集合进行的挖掘过程,它包括但不仅限于分布式计算(Hadoop)。
大数据已经站在了数据存储宣传的风口浪尖,也存在着大量不确定因素,这点上非常像“云”。我们请教了一些分析人士和大数据爱好者,请他们解释一下大数据究竟是什么,以及它对于未来数据存储的意义。
大数据走进历史舞台
适用于企业的大数据已经出现,这在部分程度上要归功于计算能耗的降低以及系统已具备执行多重处理的能力这样一个事实。而且随着主存储器成本的不断下降,和过去相比,公司可以将更多的数据存到存储器中。并且,将多台计算机连到服务器集群也变得更容易了。这三个变化加在一起成就了大数据,IDC 数据库管理分析师Carl Olofson如是说。
“我们不仅要把这些事情做好,还要能承受得起相应的开支”,他说。 “过去的某些超级计算机也具有执行系统多重处理的能力,(这些系统紧密相连,形成了一个集群)但因为要使用专门的硬件,它的成本高达几十万美元甚至更多。”现在我们可以使用普通硬件完成相同的配置。正因为这样,我们能更快更省得处理更多数据。"
大数据技术还没有在有大型数据仓库的公司中得到广泛普及。IDC认为,想让大数据技术得到认可,首先技术本身一定要足够便宜,然后,必须满足IBM称之为3V标准中的2V,即:类型(variety),量(volume)和速度(velocity)。
种类要求指的是待存储数据的类型分为结构化数据和非结构化数据。量是指存储和分析的数据量可以很庞大。 “数据量不只是几百TB,”
Olofson说: “要视具体情况而定,因为速度和时间的关系,有时几百GB可能就算很多了。如果我现在一秒能完成过去要花一小时才能完成的300GB的数据分析,那结果将大为不同。大数据就是这样一种技术,它可以满足这三个要求中的至少两个,并且普通企业也能够部署。”
关于大数据的三大误解
对于大数据是什么以及大数据能干什么存在很多误会。下面就是有关大数据的三个误解:
1、关系数据库无法大幅增容,因此不能被认为是大数据技术(不对)
2、无需考虑工作负载或具体使用情况,Hadoop或以此类推的任何MapReduce都是大数据的***选择。(也不对)
3、图解式管理系统时代已经结束。图解的发展只会成为大数据应用的拦路虎。(可笑的错误)
大数据与开源的关系
“很多人认为Hadoop和大数据基本上是一个意思。这是错误的,”Olofson说。并解释道: Teradata, MySQL和“智能聚合技术”的某些安装启用都用不到Hadoop,但它们也可以被认为是大数据。
Hadoop是一种用于大数据的应用程序,因为它是建立在MapReduce基础上的,所以引起了极大的关注。(MapReduce是一种用于超级计算的普通方法,之后经过了主要由Google资助的一个项目的优化,因此被简化并变得考究了。) Hadoop是几个紧密关联的Apache项目组成的混合体的主要安装启用程序,其中包括MapReduce环境中的HBase数据库。
为了充分利用Hadoop和类似的先进技术,软件开发商们绞尽脑汁研发出了各种各样的技术,其中很多都是在开源社区里开发出来的。
Olofson 说“他们已经开发出了大量的所谓noSQL数据库,种类之多让人眼花缭乱,其中大部分都是键值配对数据库,能利用多种技术对性能或种类或容量进行优化。”
开源技术还没有得到商业支持。“所以在这方面还需要经过一段时间的发展完善,这一过程可能需要几年。基于这个原因,大数据可能需要一些时日才能在市场上走向成熟”他补充道。
据IDC预计,年内至少有三家商业公司能以某种方式给予Hadoop支持。同时,包括Datameer 在内的几家企业将发布配有Hadoop组件的分析工具,这种工具能帮助企业开发自己的应用程序。Cloudera和Tableau公司的产品清单里已经出现了Hadoop。
hadoop是什么?在阅读完上面的资料后,相信读者对hadoop有了一定了解。