大数据在近些年来越来越火热,人们在提到大数据遇到了很多相关概念上的问题,比如云计算、 Hadoop等等。那么,大
大数据概念早在1980年,著名未来学家阿尔文·托夫勒提出的概念。2009年美国互联网数据中心证实大数据时代的来临。随着谷歌MapReduce和 GoogleFile System (GFS)的发布,大数据不再仅用来描述大量的数据,还涵盖了处理数据的速度。目前定义:大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过目前主流软件工具在合理时间内获取、管理、处理、并整理为帮助企业经营决策。
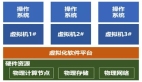
大数据目前分为四大块:大数据技术、大数据工程、大数据科学和大数据应用。其中云计算是属于大数据技术的范畴,是一种通过Internet以服务 的方式提供动态可伸缩的虚拟化的资源的计算模式。那么这种计算模式如何实现呢,Hadoop的来临解决了这个问题,Hadoop是Apache(阿帕切) 的一个开源项目,它是一个对大量数据进行分布式处理的软件架构,在这个架构下组织的成员HDFS(Hadoop分布式文件系统),MapReduce、 Hbase 、Zookeeper(一个针对大型分布式系统的可靠协调系统),hive(基于Hadoop的一个数据仓库工具)等。
1.云计算属于大数据中的大数据技术范畴。
2.云计算包含大数据。
3.云和大数据是两个领域。
云计算是指利用由大量计算节点构成的可动态调整的虚拟化计算资源,通过并行化和分布式计算技术,实现业务质量的可控的大数据处理的计算技术。而作为云计算技术中的佼佼者,Hadoop以其低成本和高效率的特性赢得了市场的认可。Hadoop项目名称来源于创立者Doung Cutting儿子的一个玩具,一头黄色的大象。

Hadoop项目的目标是建立一个可扩展开源软件框架,能够对大数据进行可靠的分布式处理。
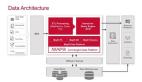
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。HDFS是一个分布式文件系统,具有低成本、高可靠性性、高吞吐量的特点。MapReduce是一个变成模型和软件框架。
简单理解,Hadoop是一个开源的大数据分析软件,或者说编程模式。它是通过分布式的方式处理大数据的,因为开元的原因现在很多的企业或多或少的在运用hadoop的技术来解决一些大数据的问题,在数据仓库方面hadoop是非常强大的。但在数据集市以及实时的分析展现层面,hadoop也有着明显的不足,现在一个比较好的解决方案是架设hadoop的数据仓库而数据集市以及实时分析展现层面使用永洪科技的大数据产品,能够很好地解决hadoop的分时间长以及其他的问题。
Hadoop大数据技术案例
让Hadoop和其他大数据技术如此引人注目的部分原因是,他们让企业找到问题的答案,而在此之前他们甚至不知道问题是什么。这可能会产生引出新产品的想法,或者帮助确定改善运营效率的方法。不过,也有一些已经明确的大数据用例,无论是互联网巨头如谷歌,Facebook和LinkedIn还是更多的传统企业。它们包括:
情感分析: Hadoop与先进的文本分析工具结合,分析社会化媒体和社交网络发布的非结构化的文本,包括Tweets和Facebook,以确定用户对特定公司,品牌或产品的情绪。分析既可以专注于宏观层面的情绪,也可以细分到个人用户的情绪。
风险建模: 财务公司、银行等公司使用Hadoop和下一代数据仓库分析大量交易数据,以确定金融资产的风险,模拟市场行为为潜在的“假设”方案做准备,并根据风险为潜在客户打分。
欺诈检测: 金融公司、零售商等使用大数据技术将客户行为与历史交易数据结合来检测欺诈行为。例如,信用卡公司使用大数据技术识别可能的被盗卡的交易行为。
客户流失分析: 企业使用Hadoop和大数据技术分析客户行为数据并确定分析模型,该模型指出哪些客户最有可能流向存在竞争关系的供应商或服务商。企业就能采取最有效的措施挽留欲流失客户。
用户体验分析: 面向消费者的企业使用Hadoop和其他大数据技术将之前单一 客户互动渠道(如呼叫中心,网上聊天,微博等)数据整合在一起, 以获得对客户体验的完整视图。这使企业能够了解客户交互渠道之间的相互影响,从而优化整个客户生命周期的用户体验。
当然,上述这些都只是大数据用例的举例。事实上,在所有企业中大数据最引人注目的用例可能尚未被发现。这就是大数据的希望。