













在昨天写了《IDF15:Xeon D被阉割?SSD性能的“色子效应”》一文之后,有位业内专家提出了批评,我先虚心接受。
“那是2012年3500刚出来的东西,现在的SSD,特别是3D的出现,已经把并发度的问题直接ko了。”
“现在SSD的应用,特别是用在云计算和RDS,队列深度肯定不止64了。有一家的RDS直接是64个实例。”
和专业人士比起来,我确实有些班门弄斧。不过,写东西出来也只是希望帮大家开阔一下思路,今天我再写点偏软件的,不算自己太擅长的领域吧:)
三种数据副本一致性模型
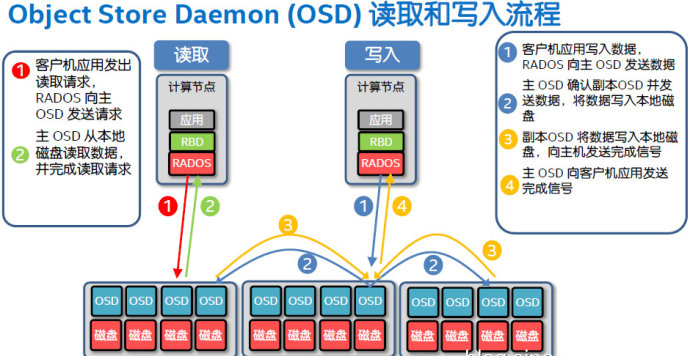
首先我们看下Ceph的读/写流程。以3副本为例,写入操作会先到主副本所在的服务器,然后复制到另外2个副本的服务器并全部返回ok,才向客户端确认。这属于主从副本强一致性的模型。而读取操作只针对主副本,在访问并发度足够的情况下,读请求会被打散到足够多的驱动器以消除热点。
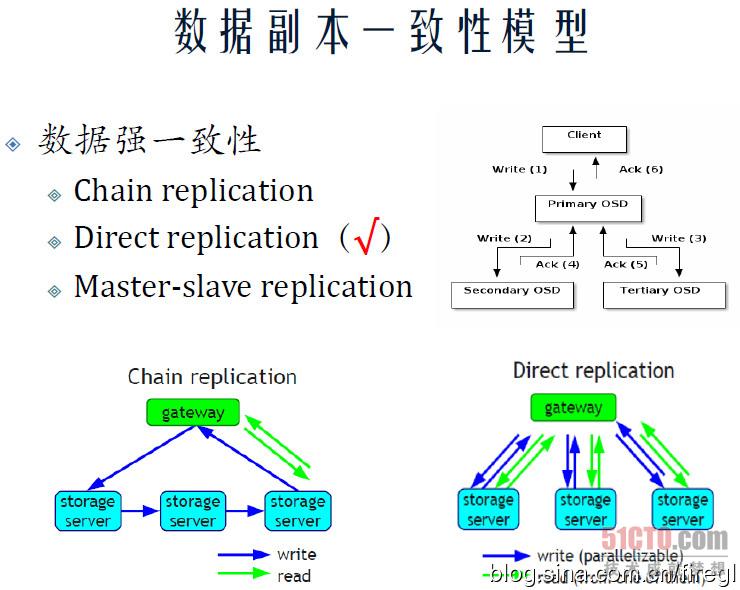
上图来自我的朋友@刘爱贵 的演讲资料,他是国内知名分布式文件系统专家,特别擅长Gluster,目前在Server SAN领域创业。
我们看到除了Ceph的Master-slave replication之外,还有另外两种强一致性模型——Chain replication(链式复制)和Direct replication(直接复制),Gluster采用的应该是直接复制。
Gluster这种方式的好处,就是存储节点之间没有数据流量,但客户端写入时直接就要3份(以3副本为例),那么网卡的带宽利用率只有1/3;Ceph的网络开销则增加在OSD存储节点之间的互连上面,1个万兆客户端接口要对应2个OSD集群连接才能充分发挥带宽,当然如果利用上全双工,3副本至少要用2个网口才算优化吧?
#p#
Ceph块存储性能预估与测试
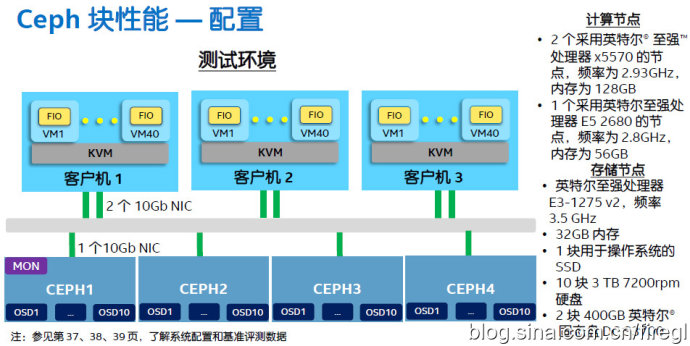
Intel资料里的测试环境,3台客户机配置不同,每台上面跑40个运行fio负载的虚拟机。4个存储节点配置相同,每台10块7200转硬盘,2个400GB DC S3700 SSD放的是Journal日志。
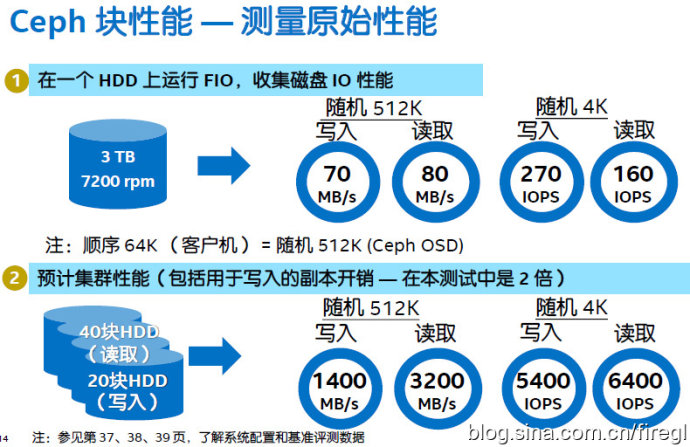
测量原始性能——也就是单个HDD的性能,单盘的4KB随机写比读还快是缓存的因素。这里在OSD上用随机512KB替代客户端64KB顺序负载的原因应该是:后者的连续存储目标会被Hash(CRUSH)算法打散在集群中的不同位置。我记得UnitedStack曾经在一个活动上用随机读来展示Ceph的性能(接近万兆网卡瓶颈),当时有人说是针对Ceph特点来设计的,我关键还在于提高并发度吧?
预计集群性能——这里是按照2副本来配置,所以理想状态下可以达到40块硬盘的读取性能,和20块硬盘的写入性能。
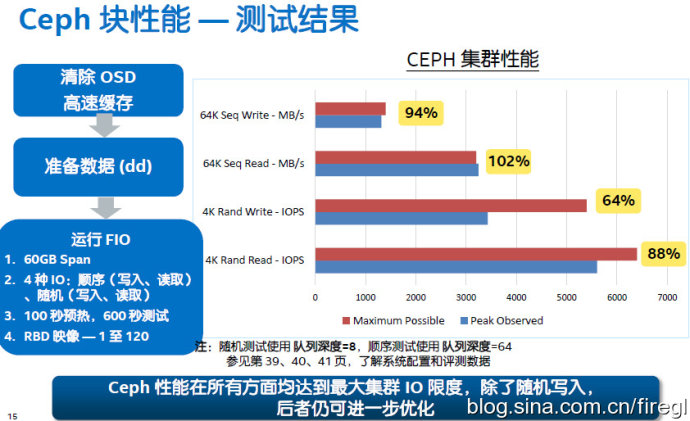
实测结果如上表,我就不过多解释了。
#p#
Ceph对象性能测试、瓶颈分析
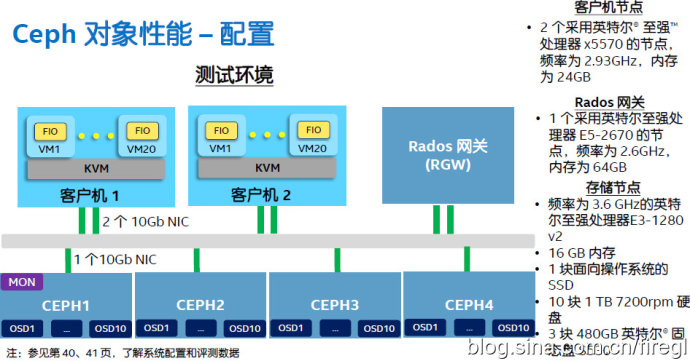
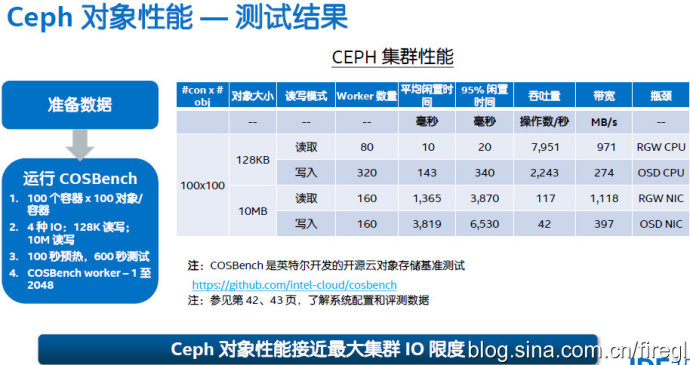
Ceph的对象存储需要增加Rados网关,这方面显然没有Swift这样原生来的理想,价值在哪里呢?下面我给出UnitedStack 朱荣泽 兄弟的2页ppt来解释一下,有些朋友应该看到过了:)
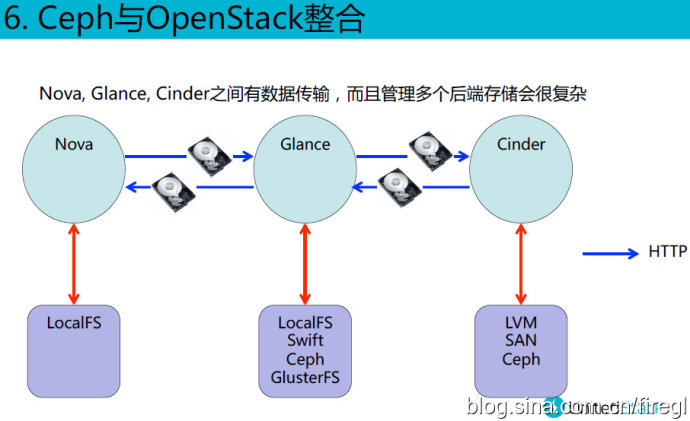
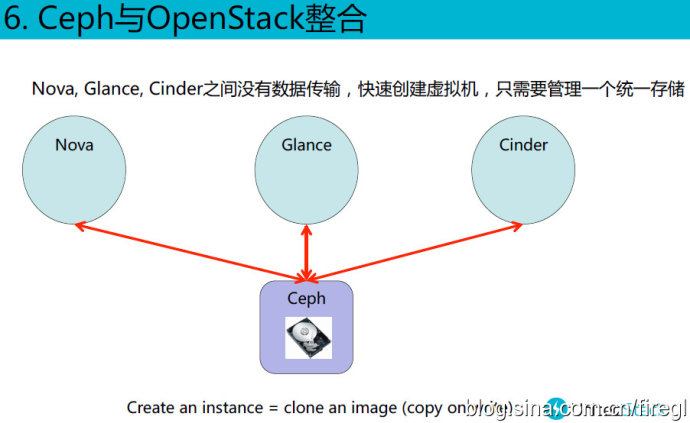
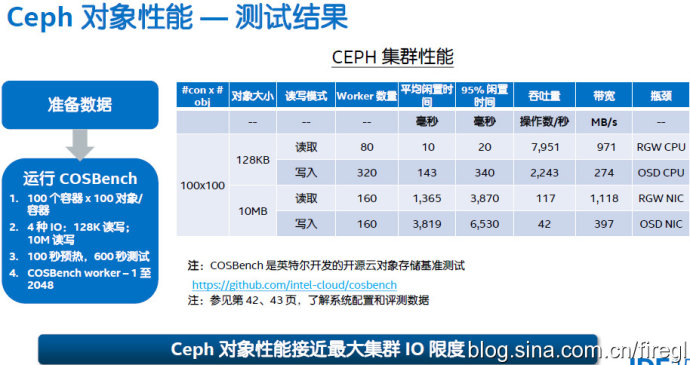
这里的测试方法与前面针对Ceph块设备的就不同了。首先128KB读取的“平均闲置时间”(翻译成平均访问时间应该更准确)可能是被缓存命中了?读IOPS和带宽基本上达到了写的3倍(因为是3副本),而10MB的读/写的平均访问时间基本上也是3倍的关系。不知道Gluster文件系统用类似的方法测试结果会如何?
最右边一列出的“瓶颈”分析也挺有价值的。其中10MB读/写带宽分别达到了RGW和OSD网卡的瓶颈,这里可以看出3副本的OSD节点用一个网口不够了吧?
#p#
SSD Cache分层和纠删码优化
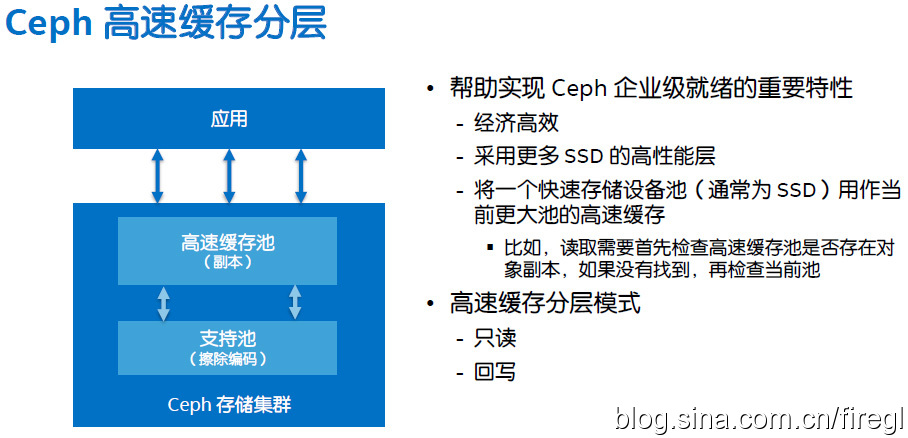
之前我们知道像UnitedStack托管云这样的配置了全SSD Ceph集群。对于冷数据比例较大的应用,可能对容量有更多需求,这时混合存储可能是个更好的方式,而Ceph对Cache分层的支持也在不断成熟。
如上图,SSD Cache层用副本保护模式,HDD支持层用纠删码进一步降低成本。这让我想起以前听过淘宝的TFS也有3副本和纠删码两个分层,不过都是在硬盘之间按数据冷热度迁移。
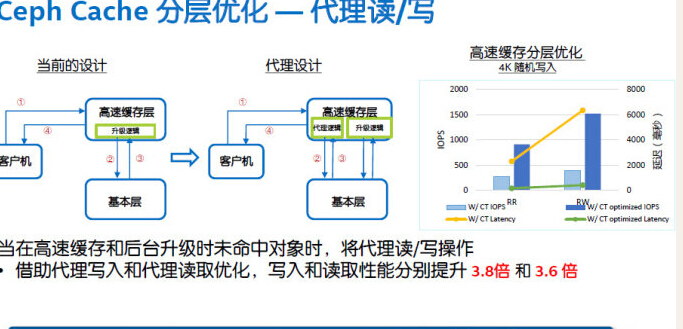
采用“代理读写”的方式优化,针对Cache层的IO路径变得更加直接。我联想到Dell Compellent阵列的自动分层存储也是数据先进到高速SSD层再“下沉”,不过这类技术的数据块定位有元数据来跟踪,而不是读/写都永远经过“代理”。
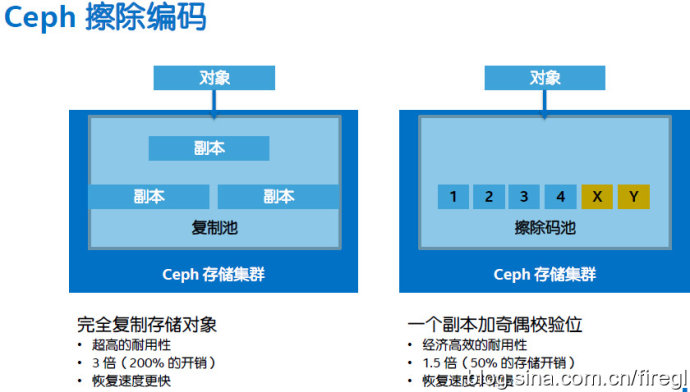
关于纠删码(擦除编码)和多副本的对比,我在去年的《IDF14:软硬兼施冷存储 Atom C2000打倒ARM?》一文中提到过。据了解Swift对象存储对它的支持还不成熟,不知道主要针对块存储(高性能)应用的Ceph进展如何?
一看到纠删码性能的优化,Intel又高兴了——这里再次出现ISA-L的身影。干用计算来换时间的事情,CPU强大的能力就不用担心被浪费,跑ZFS文件系统等也是如此。
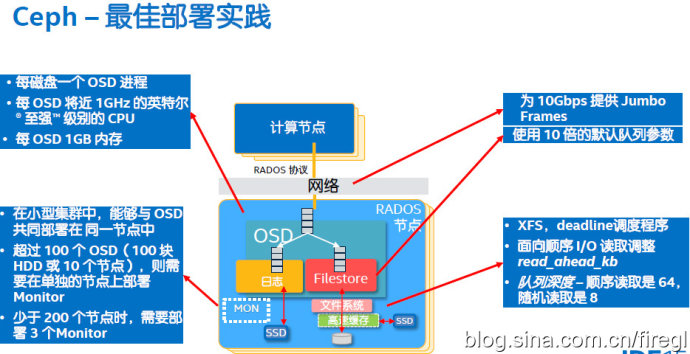
最后列出Ceph的最佳部署实践,仅供参考。
博文出处:http://blog.sina.com.cn/s/blog_69406f8d0102vhdo.html



















