本文就Amazon ECS服务的两大核心:集群管理和容器调度,进行了简单的阐述,并介绍了ECS是如何实现支持并发操作的键值对存储的,为我们实现相关服务提供了一定参考。
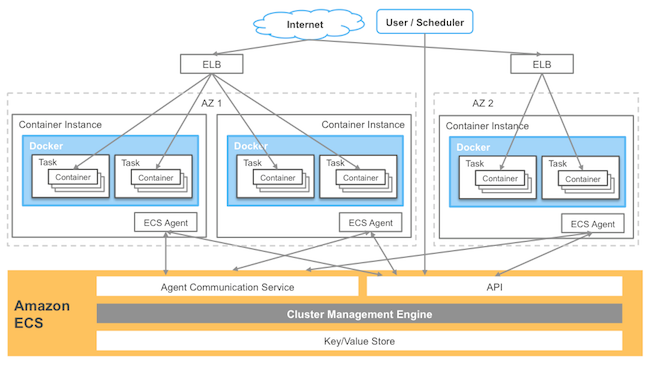
在最近一篇关于Amazon EC2容器服务(Amazon ECS)的文章中。我讨论了在一个集群中运行现代化分布式应用的两个关键组件:可靠的状态管理和灵活的调度。Amazon ECS简化了构建和运行容器化应用的流程,但是如何实现才是Amazon ECS真正有意思的地方。今天,我想要探讨Amazon ECS架构并阐述这个架构能够做些什么。如下是Amazon ECS的基本组件图:
我们如何协调(Coordination)集群
让我们来谈谈Amazon ECS到底做了什么。Amazon ECS的核心是集群管理器,它是一个后台服务,能够处理集群协调和状态管理的任务。在集群管理器之上是不同的调度器。集群管理和容器调度是互相解耦的,所以Amazon支持客户使用和创建他们自己的调度器。集群其实就是应用可以使用的计算资源池。而这里的资源池就是根据容器划分的Amazon EC2实例的CPU、内存和网络资源。Amazon ECS通过运行在集群中每个EC2实例上的容器代理来协调集群。代理允许Amazon ECS与集群中的EC2实例进行通信,并根据用户或调度器的请求来启动、终止和监控容器。代理使用Go语言编写,资源占用少,目前在GitHub上基于Apache协议开源。欢迎大家贡献和反馈。
我们如何管理状态
为了协调集群,我们的集群上需要有一个SSOT[单一数据源]:集群中的EC2实例,运行在EC2实例上的任务,组成任务的容器,可用/占用资源(例如,网络端口、内存、CPU等)。在获得精确的集群状态信息之前,我们是不可能成功开启和终止容器的。为了解决这个问题,需要在某个地方存储状态,因此现代集群管理器的心脏是键值数据库。
这个键值数据库对任何集群输入的和存储于此的信息表现为SSOT。为了保证可靠性和可扩展性,这个键值数据库需要采用分布式来确保持久性和可用性,并规避网络划分和硬件故障带来的影响。也正因为键值数据库是分布式的,确保数据一致性以及正确的进行并发修改会变得更加困难,这种情况在状态持续变化的环境(比如,容器的停止和启动)中尤甚。对此,为了保证多状态修改不会出现冲突,某些形式的并发控制就需要落实到位了。打个比方,假设有2个开发者从某个EC2实例请求剩余的内存以供他们的容器使用,这个时候,只有其中一个容器能够真正得到这些资源,而另一个则会被告知请求未完成。
为了实现并发控制,我们采用了Amazon分布式系统的核心原语之一来实现Amazon ECS,这是一个基于Paxos的事务日志的数据存储系统,它保存了每一项数据变更的记录。在日志中,任何数据的写入均以事务的形式提交,并对应一个特定顺序的ID。数据当前的值就是日志中记录的那些事务的总和。对于任何数据的读取,得到的都只是日志当前时间点的一个快照。如果写操作是继上次读取操作完成以来***提交的事务,则判定写操作成功。这种原语允许Amazon ECS以乐观锁的形式存储集群的状态信息,对于共享数据经常变动的场景(比如当需要表达诸如ECS之类的计算资源共享池的状态时)而言,这是一种理想的方式。这个架构使得Amazon ECS具有高可用性、低延迟和高吞吐量的特点,因为数据存储并未使用悲观锁(译者注:作者自己表述得很含糊,大家参见多版本并发控制MVCC)。
通过API访问
既然我们有了一个键值数据库,那么我们便能够成功协调集群,并确保所需数量的容器正在运行,因为我们有一种可靠的方法来存取集群的状态。之前提到过,我们解耦了集群管理和容器调度两个模块,因为我们希望客户能够充分利用Amazon ECS状态管理的能力。我们已经通过一系列API开放了Amazon ECS集群管理器,它允许客户以结构化的方式访问存储在键值数据库中的集群状态信息。
通过list命令,客户可以读取托管的集群,特定集群中运行的EC2实例,运行中的任务以及组成任务的容器配置(如任务定义)。通过describe命令,客户可以获取EC2实例的具体信息以及每个实例上的可用资源。最近,客户亦可以启动和停止任何集群中的任务了。近期,我们针对Amazon ECS进行了一系列的负载测试,我们希望分享一些性能要点,客户在Amazon ECS上创建应用的时候应该会关注它们的。
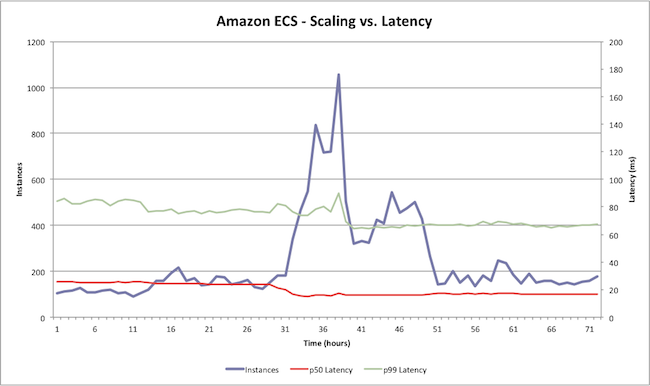
上图显示了一个负载测试的结果,在这次测试中,我们在Amazon ECS集群中添加和删除实例,并测量72小时的周期内,调用‘Describe Task’API时,百分比排列位于第50位和第99位的延迟。你可以看到,尽管集群数量有较大的波动,但是延迟相对而言并没有什么抖动。Amazon ECS可以如你所需地进行扩展,不管你的集群规模有多大,且根本无需操作或扩展集群管理器。
这组API是客户在Amazon ECS上搭建解决方案的基础。调度器只是提供了关于何时、何地以及如何开启和停止容器的逻辑。Amazon ECS的架构为分享集群状态而设计,它允许客户根据需要为应用运行各种调度器(如二进制打包、发布等)。这个架构允许调度器查询集群的具体状态,并从通用池中分配资源。乐观并发控制允许调度器无冲突地获取它们所请求的资源。一些客户已经在Amazon ECS上创建了各种有趣的解决方案,下面我们来分享一些具体的示例。
#p#
Hailo——弹性资源池上的定制调度
Hailo是一个免费的移动APP,它允许人们招呼一辆认证的出租车到其所在地。Hailo拥有一个全球网络,囊括了超过60000名司机以及一百万以上的乘客。Hailo于2011年成立,从***天开始就使用了AWS。在过去的几年中,Hailo 从AWS单一区域上运行的应用集合演化为贯穿多个区域的微服务架构。之前,每个微服务都跑在静态划分的实例集群上。Hailo遇到的问题是跨分区的资源使用率较低。这个架构并不具备很强的扩展性,并且Hailo也不希望它的工程师关心基础设施的细节或者微服务的部署问题。
为此,Hailo决定基于服务优先级以及其它的运行时指标对容器进行调度。后来他们选择了Amazon ECS来作为集群管理器,因为ECS可以轻松的管理任务状态并访问集群状态的API。同样,Hailo可以根据自己的需求来定制调度器。
Remind——平台即服务
Remind是一个web端和移动端应用,使得老师能够给学生发送信息并和家长取得联系。Remind平台上拥有24M用户和超过1.5M的老师。它每月传递150M条信息。Remind起初使用Heroku来运行整个应用设施,从消息推送引擎、前后端 API、Web客户端到聊天后台。这些设施中的大部分都以庞大的应用块进行部署。
随着用户的增长,Remind希望拥有横向扩展的能力。因此大约在2014年年底,它的工程师团队开始摸索着向基于容器的微服务架构迁移。团队希望基于AWS搭建一个PaaS,确保它能够兼容Heroku的API。一开始,团队期望能有一个开源的解决方案(比如,CoreOS和 Kubernetes)来负责集群的管理以及容器的协作,但是由于团队的规模较小,因此他们没有时间来管理集群的基础设施,同时保证高可用性。
在简要评估了Amazon ECS之后,团队决定在此服务的基础上搭建PaaS。Amazon ECS是全托管式的,这使得工程资源能够被集中于开发和部署应用;这里并没有集群需要管理和扩展。在6月份,Remind开源了他们基于ECS的PaaS解决方案,名为“Empire”。凭借Empire,Remind得到了可观的性能提升(例如,延迟和稳定性)以及安全优势。他们接下来几个月的计划是将90%以上的核心设施迁移到Empire。
Amazon ECS——一个全托管的平台
上述只是我们从客户处看到的其中两个用例。Amazon ECS架构允许我们提供一个具有高可扩展、高可用、低延迟的容器管理服务。通过API乐观并发(译者注:乐观锁)地访问共享集群状态的能力,使得用户得以按需创建任何定制容器解决方案。我们一直致力于为客户消除重复而繁重的任务。通过Amazone ECS,根本不需要安装或操作集群管理程序,客户理应仅仅专注于开发优秀的应用。