












这其实是一篇 WWDC 2015 Session 220 的学习笔记,顺便整理了下 Core Data 批量操作和聚合操作的小技巧.
批量操作
Core Data 把数据库封装成了”object graph(对象图)”,虽然对于面向对象编程来说有了管理 Model 间继承与关系的便利性,但同样也牺牲了性能.比如批量操作时就需要将每条记录作为NSManagedObject 对象读取到内存中,修改之后再存入数据库.然而用 SQL 语句执行既方便又高效.
于是苹果在 iOS8 发布时顺便弄了个”Batch Updates”,在 iOS9 发布时又弄了个”Batch Deletions”.这两个”新技术”说白了就是直接操作持久层数据库,然后还需要手动更新/删除内存中的 context 好使得我们的 UI 从 context 读取的内容不会出错.这样做的好处就是省去了向内存的一次写操作和查找操作,而越过 context 直接操作持久层,最后我们需要自己手动将持久层的变更结果(BatchResult)重新写入 context.只有当需要更新/删除大批量数据的时候才需要用到这两个技术.
然而苹果至今未提供二者的文档,关于”Batch Updates”我在CoreData处理海量数据中给出了用法和例子.看了 WWDC2015 Session 220 后觉得 “Batch Deletions” 应该与 “Batch Updates” 用法类似,并且坑爹. PS: 我在 iOS9 上测试 “Batch Updates” 发现了一个 bug, 每次更新 context 都会漏掉一条记录,这让我十分郁闷.
聚合操作
说完了批量操作,再谈谈聚合操作.在 SQL 语法中有一类聚合函数,比如count(),sum(),max(),min(),avg() 等,它们一般搭配着 group by 甚至 having来使用.然而在号称”object graph”的 Core Data 中,这种聚合操作在 NSFetchRequest 中也是有替代品的.下面的例子取自CORE DATA AND AGGREGATE FETCHES IN SWIFT:
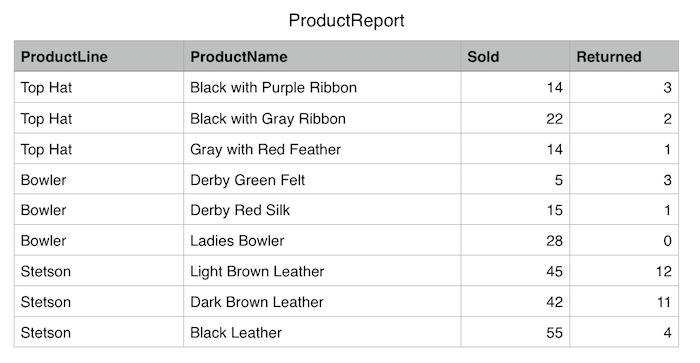
我们想计算出每条产品线的销售量和退货量,可以用下面的 SQL 语句搞定:
- SELECT ProductLine, SUM(Sold) as SoldCount, SUM(Returned) as ReturnedCount FROM Products GROUP BY ProductLine
NSFetchRequest 有个 propertiesToGroupBy 属性,正好对应着 group by 语句:
- // Build out our fetch request the usual way
- let request = NSFetchRequest(entityName: self.entityName)
- // This is the column we are grouping by. Notice this is the only non aggregate column.
- request.propertiesToGroupBy = ["productLine"]
下面还需要映射 SQL 语句中聚合函数及其计算后的结果,此时我们需要用到NSExpressionDescription 和 NSExpression 来替换 SQL 中的ProductLine, SUM(Sold) as SoldCount, SUM(Returned) as ReturnedCount:
- // Create an array of AnyObject since it needs to contain multiple types--strings and
- // NSExpressionDescriptions
- var expressionDescriptions = [AnyObject]()
- // We want productLine to be one of the columns returned, so just add it as a string
- expressionDescriptions.append("productLine")
- // Create an expression description for our SoldCount column
- var expressionDescription = NSExpressionDescription()
- // Name the column
- expressionDescription.name = "SoldCount"
- // Use an expression to specify what aggregate action we want to take and
- // on which column. In this case sum on the sold column
- expressionDescription.expression = NSExpression(format: "@sum.sold")
- // Specify the return type we expect
- expressionDescription.expressionResultType = .Integer32AttributeType
- // Append the description to our array
- expressionDescriptions.append(expressionDescription)
- // Create an expression description for our ReturnedCount column
- expressionDescription = NSExpressionDescription()
- // Name the column
- expressionDescription.name = "ReturnedCount"
- // Use an expression to specify what aggregate action we want to take and
- // on which column. In this case sum on the returned column
- expressionDescription.expression = NSExpression(format: "@sum.returned")
- // Specify the return type we expect
- expressionDescription.expressionResultType = .Integer32AttributeType
- // Append the description to our array
- expressionDescriptions.append(expressionDescription)
NSExpressionDescription 是用于表示那些抓取结果中实体中不存在的列名,比如我们这次用的聚合函数所计算的结果并不能在实体中找到对应的列,于是我们就得给它起个新名字,这就相当于 SQL 中的 as,这里对应着 NSExpressionDescription 的 name 属性.而聚合函数表达式就需要用 NSExpression 对象来表示,比如 NSExpression(format: "@sum.returned")就是对”returned”这列求和.
像本例中这样初始化 NSExpression 需要对格式化语法较为熟悉(比如"@sum.returned"),初学者建议看看官方的例子,使用容易理解的构造方法一步步拼凑成想要的结果:Core Data Programming Guide
将以上这三个”列描述”依次添加到 expressionDescriptions 数组中,最后要赋值给NSFetchRequest 的 propertiesToFetch 属性:
- // Hand off our expression descriptions to the propertiesToFetch field. Expressed as strings
- // these are ["productLine", "SoldCount", "ReturnedCount"] where productLine is the value
- // we are grouping by.
- request.propertiesToFetch = expressionDescriptions
propertiesToFetch 属性其实是个 NSPropertyDescription 类型数组,能表示属性,一对一关系和表达式.既然是个大杂烩,NSPropertyDescription 也就有一些子类:NSAttributeDescription,NSExpressionDescription,NSFetchedPropertyDescription,NSRelationshipDescription.我们这里用到的便是 NSExpressionDescription.
在设定 propertiesToFetch 属性之前必需要设定好 NSFetchRequest 的 entity 属性,否则会抛出 NSInvalidArgumentException 类型的异常.并且只有当 resultType 类型设为NSDictionaryResultType 时才生效:
- // Specify we want dictionaries to be returned
- request.resultType = .DictionaryResultType
最终结果:
- [
- ["SoldCount": 48, "productLine": Bowler, "ReturnedCount": 4],
- ["SoldCount": 142, "productLine": Stetson, "ReturnedCount": 27],
- ["SoldCount": 50, "productLine": Top Hat, "ReturnedCount": 6]
- ]
WWDC2015 Core Data 的一些新特性
苹果号称有超过40万个 APP 使用 Core Data,并能让开发者少写50%~70%的代码.并在内存性能上强调卓越的内存拓展和主动式惰性加载,炫耀了它跟 UI 良好的绑定机制,还提供了几种多重写入的合并策略.然而这不能阻止开发者对 Core Data 的吐槽,毕竟建立于持久层之上的”object graph”还做不到像 SQL 那样面面俱到,于是今年针对 Core Data 新增的 API 更像是查缺补漏,并没有带来重大功能更新.
NSManagedObject 新增 API
hasPersistentChangedValues
- var hasPersistentChangedValues: Bool { get }
用此属性可确定 NSManagedObject 的值与 “persistent store” 是否相同.
objectIDsForRelationshipNamed
- func objectIDsForRelationshipNamed(_ key: String) -> [NSManagedObjectID]
适用于大量的多对多关系.由于我们不想将整个关系网络加载到内存中,所以这个方法仅返回相关联的 ID.下面是一个例子:
- let relations = person.objectIDsForRelationshipNamed("family")
- let fetchFamily = NSFetchRequest(entityName:"Person")
- fetchFamily.fetchBatchSize = 100
- fetchFamily.predicate = NSPredicate(format: "self IN %@", relations)
- let batchedRelations = managedObjectContext.executeFetchRequest(fetchFamily)
- for relative in batchedRelations {
- //work with relations 100 rows at a time
- }
通过给出的关系名称 “family” 来获取对应的 ID, 并每次遍历100行记录,实现了内存占用的可控性.
#p#
NSManagedObjectContext 新增 API
refreshAllObjects
- func refreshAllObjects()
正如其名字所描述的那样,它的功能就是刷新 context 中所有对象,但会保留未保存的变更.相比reset 方法不同的是它会依然保留 NSManagedObject 对象的有效性,我们无需重新抓取任何对象.正因如此,它很适用于打破一些因遍历双向关系循环而产生的保留环.
mergeChangesFromRemoteContextSave
- class func mergeChangesFromRemoteContextSave(_ changeNotificationData: [NSObject : AnyObject], intoContexts contexts: [NSManagedObjectContext])
在 store 中使用多个 coordinator 时,这个方法将会从一个 coordinator 接受一个通知,并将其应用到另一个 coordinator 中的 context 上.这使得我们可以在所有 context 中存有最新的数据,Core Data 会维护好所有的 context.
shouldDeleteInaccessibleFaults
- var shouldDeleteInaccessibleFaults: Bool
Core Data 偶尔会抛异常,但Core Data 不能加载故障, 因为它的主动式惰性加载对象使得内存中只保留对象图中的一部分.所以很有可能当我遍历关系时要试图回到磁盘上查找,但此时对象早已被删除了.于是 shouldDeleteInaccessibleFaults 属性应运而生,默认值为 YES.
如果我们在某处遇到了故障,我们会将其标记为已删除.任何丢失的属性将会被设为null,nil或0.这就使得我们的 app 继续运行,并认为发生故障的对象已被删除.这样程序就不会再崩溃.
NSPersistentStoreCoordinator 新增 API
增加这两个新的 API 的原因是很多开发者绕过 Core Data 的 API 来直接操作底层数据库文件.因为NSFileManager 和 POSIX 对数据库都不友好,并且如果此时文件的 open 连接没关闭的话会损坏文件.
destroyPersistentStoreAtURL
- func destroyPersistentStoreAtURL(_ url: NSURL, withType storeType: String, options options: [NSObject : AnyObject]?) throws
传入的选项与 addPersistentStoreWithType 方法要一样,删除对应类型的 persistent store.
replacePersistentStoreAtURL
- func replacePersistentStoreAtURL(_ destinationURL: NSURL, destinationOptions destinationOptions: [NSObject : AnyObject]?, withPersistentStoreFromURL sourceURL: NSURL, sourceOptions sourceOptions: [NSObject : AnyObject]?, storeType storeType: String) throws
与上面的 destroy 一个套路,就是 replace 而已.如果目标位置不存在数据库,那么这个 replace 就相当于拷贝操作了.
Unique Constraints
很多时候我们在创建一个对象之前会查看它是否已经存在,如果存在的话就会更新它,否则就创建对象.这很可能产生一个竞态条件,如果多线程同时执行下面这段代码, 很可能就创建了多个重复的对象:
- managedObjectContext.performBlock {
- let createRequest = NSFetchRequest(entityName: "Recipe")
- createRequest.resultType = ManagedObjectIDResultType
- let predicate = NSPredicate(format: "source = %@", source)
- let results = managedObjectContext.executeFetchRequest(createRequest)
- if (results.count) {
- //update it!
- } else {
- //create it!
- }
- }
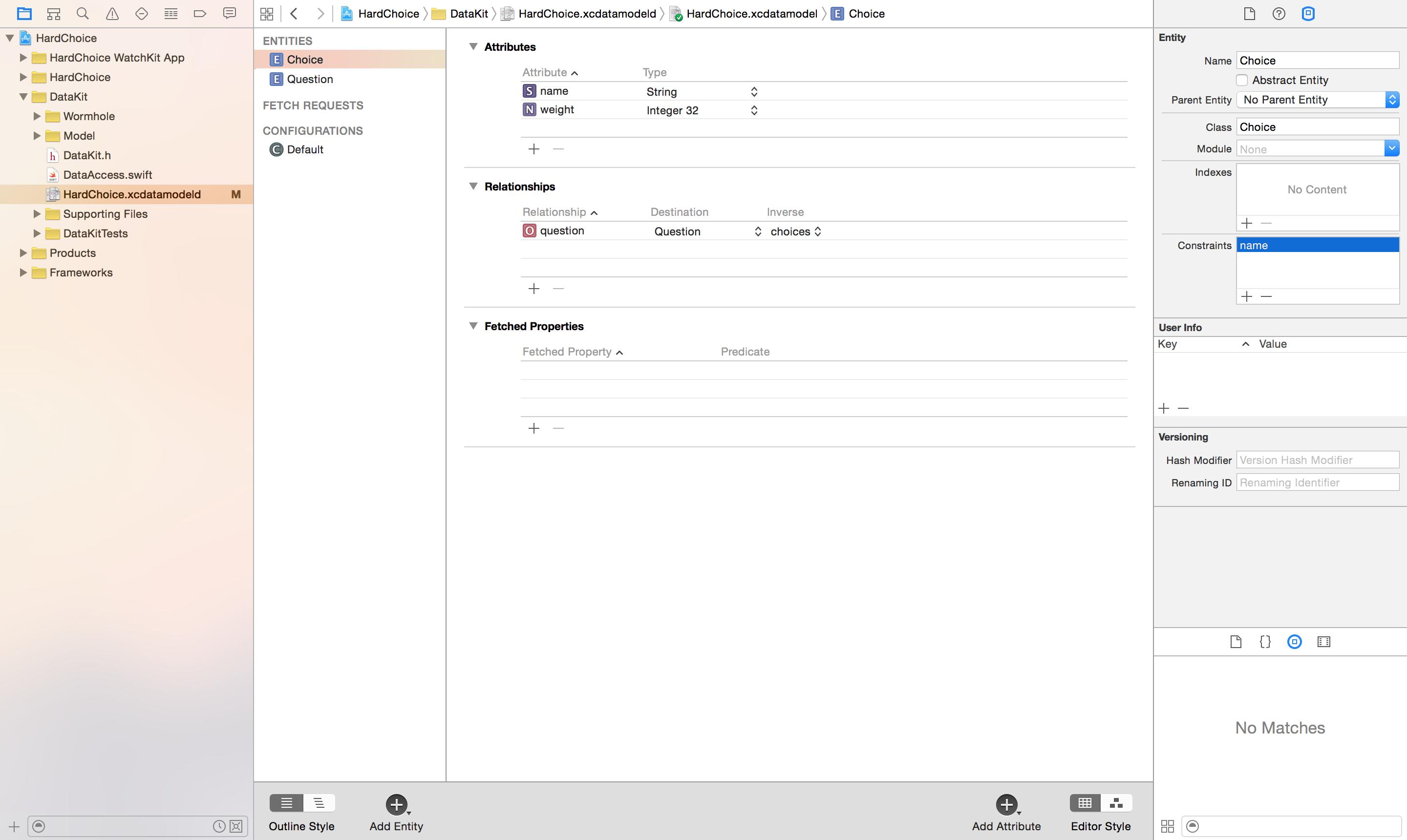
现在 Core Data 可以搞定这个事情了.我们设定属性的值唯一,类似于 SQL 中的 unique 约束.诸如电子邮件,电话号, ISBN 等场景都适用此.同时别忘了 Core Data 的对象图中实体的继承关系,这里规定子类会从父类继承到具有 Unique 约束的属性,并可以将更多的属性设为 Unique.
为实体设置 Unique 属性十分简单,只需要在 Xcode 中选中对应的实体,打开 “Data Model inspector” 就可以看到 “Constraints”, 点击加号添加就好:
Model Caching
这是个轻量级的数据版本自动迁移解决方案.它会缓存旧版本数据中已创建的NSManagedObject 对象会被缓存到 store 中,并被迁移到合适的 store 中.
Generated Subclasses
在 Xcode7 中,自动创建 NSManagedObject 子类时将不再在对应实体子类文件中自动填充模板代码,而是同时创建Category(Objective-C文件) 或 extension(Swift文件),并将模板代码自动填写进去.这样带来的好处是将我们自己写的代码跟 Xcode 生成的模板代码分开,更易于更新维护.














