在软件定义的世界里,企业通过Web应用和移动应用程序来提供大部分的服务,而Node.js迅速成为时下最为流行的一个平台之一,就和它可以搭建 响应速度快、易于扩展的web应用和移动应用很很大关系,并凭借这点成为了新的主流。作为大规模使用Node.js 的云计算服务提供商,UCloud积累了丰富的使用经验。
本文为UCloud 公司高级工程师文天乐在深JS大会上发表的演讲内容,主要介绍了UCloud内部如何利用Node.js 构建分布式集群,并分享了实践过程中走过的坑,希望对正在使用Node.js或是即将使用Node.js的朋友有一些帮助。

图:UCloud高级工程师文天乐
UCloud内部大规模使用了Node.js 技术,利用Node.js研发了一套RPC框架,主要涉及API、Web Console、服务中间层、运营报表、内部运营工具和内部系统等,解决以下四个问题:
1. 服务调动发现程序间解耦;
2. 自动快速扩容服务能力;
3. 脚本语⾔言提高研发效率;
4. 配置集中管理变更应用自动加载。
架构演进
在RPC框架V1版本的架构中,如下图。从图中可以看出,是一个金字塔架构,也就意味所有通信服务需要首先和名字服务进行通信,获取到对端节点状态和IP端口信息,然后再进行通信,这样导致系统的高耦合,增加了系统的复杂性,这并不是一件好事。
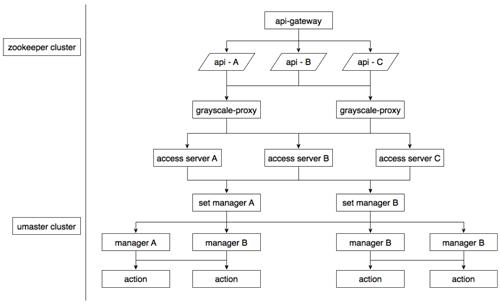
图1
为此,我们改进了RPC框架架构,如图2。在V2版本中,可以看到改进的架构已是一个网状架构,实现了将所有消息出入口统一到RabbitMQ Server ,以便所有的通信可以在不知道对端节点状态时,就可以调用对端服务,从而实现了服务端调用关系解耦。
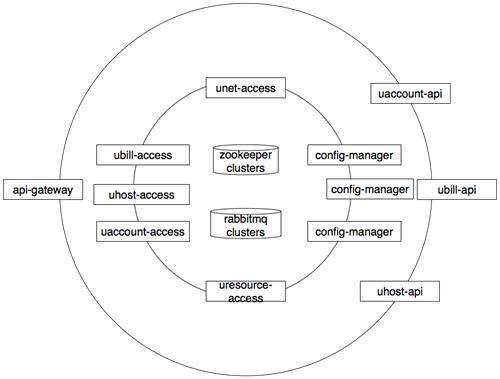
图2
实现方案
那么到底是如何实现服务端调用解耦的呢?在实现方案中,我们采用了(Node.js + Protocol Buffers + Zookeeper + RabbitMQ)的组合,从而实现配置集中化管理:
1. Node.js,主要用于开发业务逻辑。
作为天生的异步脚本语言,Node.js 使用事件驱动、 非阻塞I/O模型大大提升了研发效率,非常适合在分布式设备上运行的数据密集型的实时应用。
我们通过 fibers库采用协程的方式来解决Node.js 异步编程匿名回调问题,将异步回调逻辑转化为同步,同时也满足了程序员使用同步方法编写异步程序的情怀。
可参考官方介绍:https://nodejs.org/
https://github.com/laverdet/node-fibers
2. Protocol Buffers,用于强约束消息定义。
Protocol Buffers一种数据交换的格式,它独立于语言,独立于平台。由于它是一种二进制的格式,相比XML和JSON,传输效率会更高,可以将它用于分布式应 用之间的数据通信或者异构环境下的数据交换。我们主要将Protocol Buffers用来模版化定义消息结构。
可参考:https://github.com/google/protobuf
3. Zookeeper,实现配置集中管理。
Zookeeper分布式服务框架是Apache Hadoop 的一个子项目,简单的说,Zookeeper=文件系统+通知机制。它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
我们使用ZooKeeper看重的是它不仅支持集群高可用,还支持持久化节点、临时节点存储和节点变更监控的特点,主要使用了它提供的命名服务、配置管理和集群管理服务。其中,临时节点特性用以实现名字服务注册,节点变更监控实现配置集中管理。
参考:https://zookeeper.apache.org
4. RabbitMQ,实现异构通讯服务间的解耦。
Rabbitmq是一种应用程序对应用程序的通信方法,选择RabbitMQ的原因在于它可以支持集群高可用、简单易用、性能出色和完善的管理工具(如:Web ui / Rest API )的特点。
使用Rabbitmq中间件服务端实现解耦,其中主要是利用( Work Queue + Topics Exchange )来实现后端的无缝扩容,并采用Publish/ Subscribe + RPC 实现调用解耦,并利用MQ 统一输入输出。
参考:https://www.rabbitmq.com
走过的一些坑
***,总结经验避免犯同样的错,是非常重要的,还有一些技术遗留问题,需要我们自行避开这些坑。以下是我们在构建RPC框架过程中遇到的一些坑:
♦ 异步编程效率问题(Fibers)& Node.js 内存泄漏问题
在复杂在构建复杂应用的时候,很多地方都可能发生内存泄露,也需要考虑异步编程效率问题。为解决这两个问题,我们目前主要采取以下四个手段来解决:
a) 框架封装所有网络通信,业务方只关注业务逻辑、提高研发效率;
b) 通过Fibers 封装所有异步匿名函数调用转换为同步方法;
c) 谨慎选择第三方库。
♦ 异步框架中日志跟踪
异步程序记录日志乱序不利于跟踪业务逻辑调用路径。为解决这个问题,我们通过包装 Fibers 对每一个 Fiber 实例进行编号,在所有日志输出中打印 Fiber id 记录异步调用路径,并配合跨模块会话编号实现请求调用跟踪,以此解决日志纪录的无序问题。
♦ RabbitMQ HA 高可用问题
如果需要实现RabbitMQ HA 高可用特性,有两种途径可以实现:Server 端 HA 和 Client HA。Server 端的高可用性可使用 LVS 或 HAProxy来实现,Client 端的高可用性也是一种选择,这样可以减少架构复杂度和层次依赖。值得注意的是,实现高可用特性时,要记得开启Queue 高可用配置。
(https://www.rabbitmq.com/ha.html)
♦ RabbitMQ HA 网络闪断导致节点分区问题
网络不稳定导致RabbitMQ HA 网络闪断,进而导致节点分区问题。针对这个问题,需要添加对 /api/nodes 进行监控,并及时处理分区问题。
具体的解决方法可参考: https://www.rabbitmq.com/partitions.html。
♦ ZooKeeper Session Expired
针对ZooKeeper 会话过期问题,需要大家特别关注处理Zookeeper 集群断开后的重连处理,因为如果重连逻辑没有处理好的话,所有依赖ZooKeeper的特性都将不可用。
具体解决方法可参考:http://wiki.apache.org/hadoop/ZooKeeper/FAQ
【结语】
经过应用实践,目前看来 Node.js几乎可以做到其他后端语言所能做到所有的事情,ES6特性正式发布如今有人已经开始高喊“JavaScript: The World's Best Programming Language”,但我也并不认为整个后端完全用Node.js来实现会是一个很好的方案。
本文中提到了Node.js的诸多优点,如异步、非阻塞和事件驱动等,但其也存在一些缺点,如默认单进程单线程不能利用多核,脚本弱类型容易出现运 行时BUG,同时因为它简单易用,也导致了代码质量不易控制,对开发人员也提出了更高的要求。所以,就个人经验来看,建议偏复杂业务逻辑控制使用 Node.js,如果是偏***性能的业务建议和C++等其他方案结合使用。