首先还是要声明一下,这个文章是我在入职阿里云1个月以来,对于分布式计算的一点肤浅的认识,可能有些地方不够妥善,还请看官可以指出不足的地方,共同进步。
一.背景
随着互联网的发展,数据量的增大,很多对于数据的处理工作(例如一些推荐系统、广告推送等)都迁移到了云端,也就是分布式计算系统上。衍生了很多牛逼的分布式计算的计算模型,比较著名的就是MapReduce、MPI、BSP等。后来也产生了一些分布式计算系统,大家耳熟能详的Hadoop就是基于 MapReduce实现的。
本文的主人公是Parameter Server,其实也不算是新宠了,这个模型已经被提出好几年了,只不过在国内还不是特别热。不过最近一些云服务巨头们开始了对于PS的深入开发和研究。
引用一位算法大神的话简单描述下什么事Parameter Server:总结是一种计算模型SSP+一种分布式设计看板模式Client+Server(partitioned table)+基于算法的调度策略(Scheduler)。可能有些同学还不太理解这句话,没关系,下面通过一个实例来介绍一下PS。
二.场景
因为我在学习PS的过程中是对照Map Reduce来学习的。所以也通过一个机器学习算法的并行计算的实例,来比较Map Reduce和PS。为了更好地突出PS的优势,这里用到的算法是一个梯度逼近***结果的一种算法-逻辑回归(Logical Regression)。
为了更好地帮大家理解这些内容,我也罗列了一些必须的知识储备:
1.逻辑回归算法-***fork里面的代码看一下
2.随机梯度下降SGD
3.李沐大神实现的一个PS开源库,上面有一个论文,一定要读
4.并行逻辑回归-等会会借用里面的内容来讲
5.ps开源代码网站
三.Work Flow
首先还是要补充几句,Map-Reduce在实现并行算法的过程中有它的优势,但是也有很大的弊端,它在处理梯度问题上没有很好的效率。这一点PS通过client+server的模式很好的解决了这个问题。
1.Map-Reduce处理LR
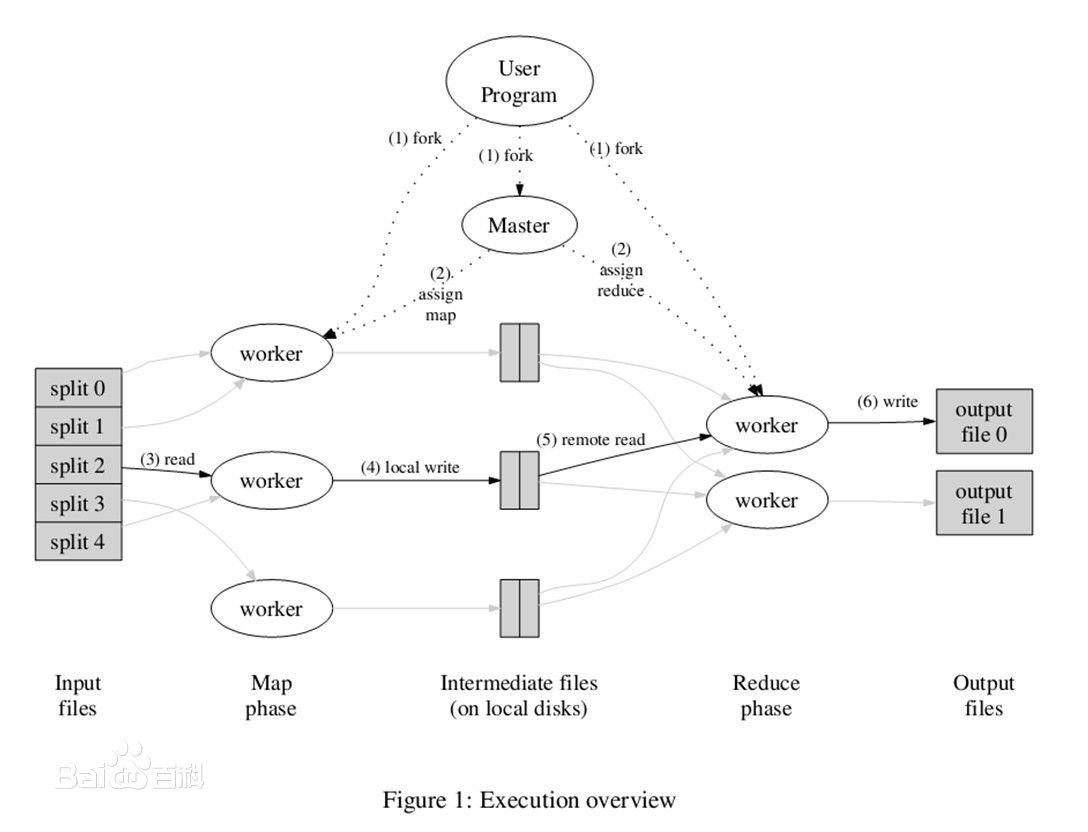
首先来看下Map-Reduce是如何解决逻辑回归(下文统一称为LR)的。首先是map的过程,将很大的数据切割成key-value的形式,我们在这里假设所有的数据都是稠密的。比如说你有100行数据,切割成5份,那么每一个worker就处理其中的20行数据。Reduce主要是负责统一 worker的计算结果。下面具体到LR的算法实现来讲解下Map-Reduce的过程。
先来看看整体的流程图:
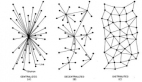
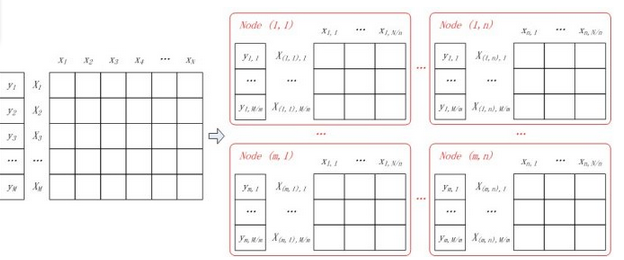
***步:首先是进行map阶段对于长尾数据的分割,我们假设数据是稠密非稀疏的。逻辑回归的并行计算的数据分割,可以按行分、按列分或者行列一起分。分好的数据通过key-value的形式传到每一个worker中,对应上图的map phase阶段的worker。当然,map里也包含LR的计算逻辑,逻辑请大家看上面的资料自己学习下。分割图如下:
第二步:利用随机梯度(SGD)方法逼近***解,在凸函数中LR是可以***接近***模型的,可以通过限定循环次数和收敛条件来实现。这其中就有一个问题,认真研究LR的同学可能会发现,如果我们使用SGD的话,因为worker之间虽然有一定的通信机制,但是并不是实时同步的,所以每一个worker并不知道对方的梯度是多少,形象的描述一下就是我们可以把SGD看成一个下坡问题。
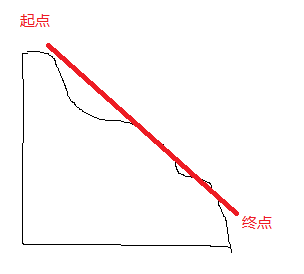
每个worker都在往终点方向下山(收敛模型),但是它们彼此间并不能实时协作,也就是说A不知道B爬到哪里,C不知道A爬到哪里。传入一个路径,我就接着向下爬一点,可能会走重复的路径。所以说Map-Reduce的SGD是一种范围的梯度。每个worker不一定一直往下走,可能走走停停甚至往后走一点,但是因为数据量巨大总是可以走到终点的。 但是这样就会浪费了很多效率,这也就是Parameter Server重点解决的问题。
第三步:负责reduce的服务器统一出一个模型输出。
#p#
2.Parameter Server的一些机制
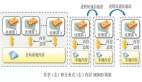
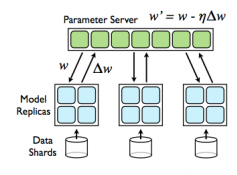
下面我们看下Parameter Server是怎么解决这个问题。首先看下PS的总体架构,PS是由client和server组成的,client对应于上文的worker,负责计算。server是负责统一所有的client它们的参数,server间是联通的。
如下图:
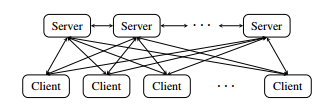
总体来看,PS的优势是通过server来协同client的输出,如上一节的下山问题,PS可以协同每一个client按照一个方向直线下山,从而提高了效率。而这其中也有很多的技术细节需要考虑。
1).并行化设计
PS可以运用很多并行化的思想从而提高效率。
(1)首先在client端,计算和上传数据是采用的多线程机制,计算和数据传输在不同的线程中进行从而增加了效率。同时server并不是等待所有参数都上传完成,才向下分发的。如果一个client_a计算比较慢,server可以暂时不采用client_a的数据,而采用历史数据。
(2)数据上传也可以用树状结构代替直接上传,在client和server之间增加一层树状结构可以提高数据传输效率,节约server的处理资源。可以从下图的左边,变为右边。
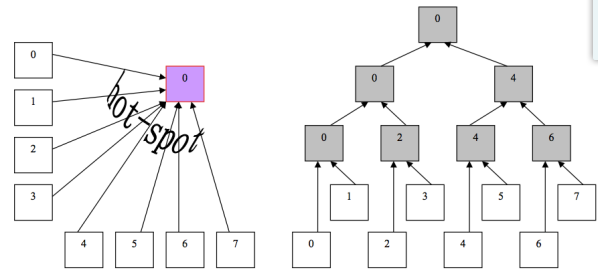
2).pull和push机制
首先,是在client端应该上传怎样的数据,因为每个client节点都会不停的接受和反馈数据给server,那么到底应该push怎样的数据上去呢?这个一般来讲是选择步长最长的参数,也就是***的梯度值的参数push上去。
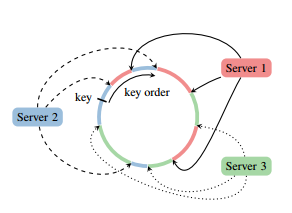
3).server端的异构形式
因为每个client只处理一部分参数,server端需要将这些参数拼接起来,所以server端是一个异构的组成形式。
3.Parameter Server处理LR
上面讲了很多PS的机制,这里具体说一下PS怎么实现LR。因为LR的输出是一个线性的回归模型。输出的结果是下面的这种式子:
z=w1*x1+w2*x2…..+w10*x2+….
我们要求的是里面的w1,w2,w3….这些参数,在PS中每个client计算的是其中的某些△w。通过server将这些△w同步上去,然后再push下去继续迭代计算。这样的好处是对于梯度问题,每个client可以沿着一个方向走。
后话:我的理解还很浅,具体实现还有非常多的技术细节要敲定,部署在集群上也会出现各种问题,如:log怎么输出,有的client挂了怎么办等等。建议有空可以看下李沐的开源项目的代码,还有上面提到的一些文档。
博文出处:http://blog.csdn.net/buptgshengod/article/details/46819051