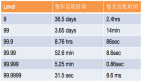
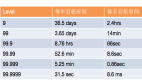
嘉宾介绍
张冠宇:花名关羽,目前在大众点评做运维架构师一职。在大众点评这几年时间,见证了点评运维从无到有,从低效向高效的转变过程。
分享内容
今天分享专题大纲如图所示,从5个方面跟大家一起探讨:

1、点评运维团队的配置
目前我们运维分为4个组,相信跟大部分公司一样,运维团队分为:应用运维、系统运维、运维开发和监控运维,当然还有DBA团队和安全团队,这里就不一一罗列了。整个运维团队全算上目前是不到40人规模。
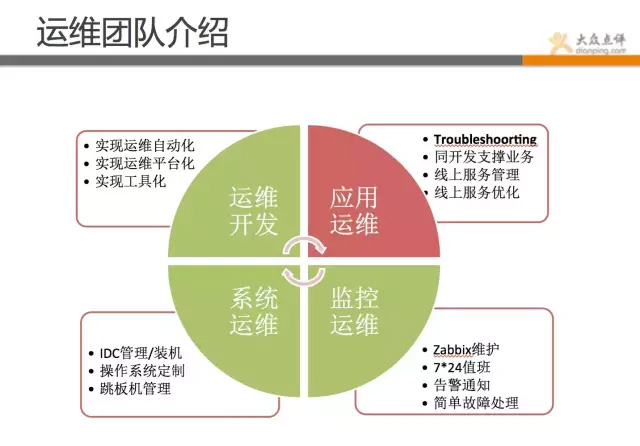
我们团队分工是这样的:
-
应用运维:负责支持线上业务,各自会负责对应的业务线,主要职能是保证线上业务稳定性和同开发共同支撑对应业务,以及线上服务管理和持续优化。
-
运维开发:帮助运维提升工作效率,开发方便快捷的工具,实现运维平台化自动化。
-
系统运维:负责操作系统定制和优化,IDC管理和机器交付,以及跳板机和账号信息管理。
-
监控运维:负责发现故障,并第一时间通知相关人员,及时处理简单故障和启动降级方案等。
2、点评的整体架构
先看下点评的机房情况。
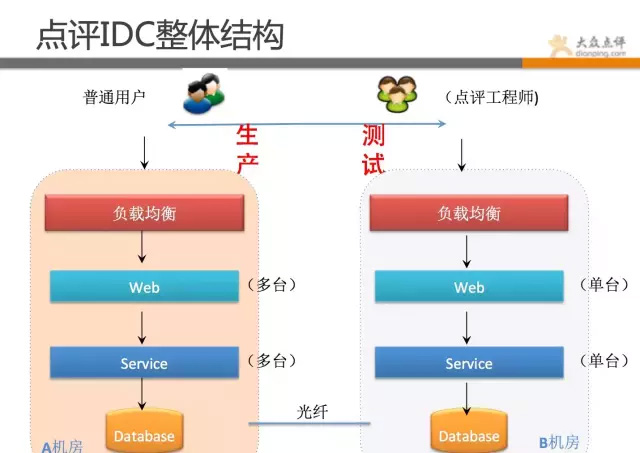
点评目前是双机房结构,A机房主跑线上业务,B机房跑测试环境和大数据处理作业,有hadoop集群、日志备份、灾备降级应用(在建)等。点评目前机房物理机+虚拟机有近万台机器。
#p#
点评的整体架构,还是跟多数换联网公司一样,采用多级分层模式,我们继续来详细看下点评整体架构。
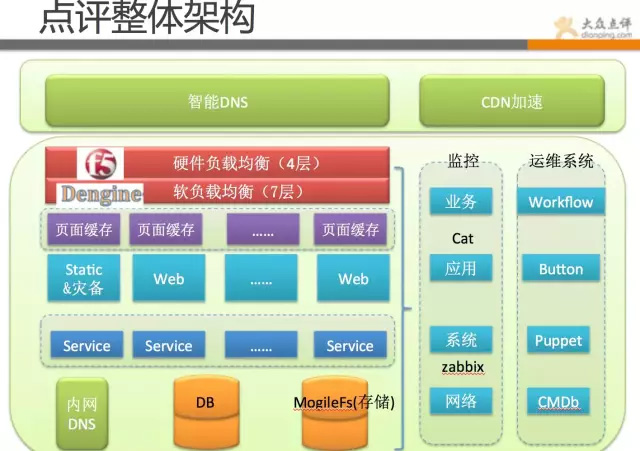
上面这幅图基本概括了点评的整体架构环境:
-
用户引导层用的是第三方的智能DNS+CDN。
-
负载均衡首先是F5做的4层负载均衡 之后是dengine做的7层负载均衡(Dengine是在tengine基础上做了二次开发)。再往后是varnish做的页面缓存 之后请求到web端 web端通过内部协议调用service(RPC)。
-
图片存储用的是mogileFS分布式存储 。
-
所有业务,全部有高可用方案,应用全部是至少2台以上。
-
当然,具体业务要复杂很多,这里只是抽象出简单层面,方便各位同学理解。
目前,点评运维监控是从4个维度来做的:
-
业务层面,如团购业务每秒访问数,团购券每秒验券数,每分钟支付、创建订单等(cat)。
-
应用层面,每个应用的错误数,调用过程,访问的平均耗时,最大耗时,95线等(cat)。
-
系统资源层面:如cpu、内存、swap、磁盘、load、主进程存活等 (zabbix)。
-
网络层面: 如丢包、ping存活、流量、tcp连接数等(zabbix cat)。
3、点评运维系统介绍
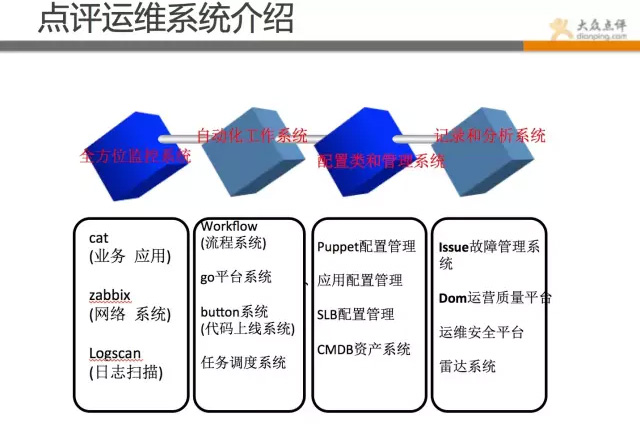
点评的运维和平台架构组做了很多实用的工具,这些工具组成了点评的整体运维体系。
目前自动化运维比较热,但自动化运维个人觉得是一种指导思想,没必要硬造概念和生搬硬套。自动化在很多公司百花齐放,各家有各家的玩法。但不管怎么定义,运维人员都必须从不同纬度去面对和解决企业所存在的问题。
点评在这方面,也是摸着石头过河,我们的思路是先造零件,再整合,通过零件的打造和之间的整合,慢慢勾勒出一条适合自己的运维自动化框架。
我们运维的理念是:
-
能用程序干活的,坚决程序化、平台化;
-
能用管理解决的问题,不用技术解决;
-
同一个错误不能犯三次;
-
每次故障,都是学习和提升的机会;
-
每个人都要有产品化思维,做平台产品让开发走自助路线;
-
小的,单一的功能,组合起来完成复杂的操作(任务分解);
所以,我们将自己的理念,融入到自己的作品中,做出了很多工具。
首先整体做个说明,点评运维工具系统汇总:
-
全方位监控系统:覆盖业务、应用、网络、系统等方面,做到任何问题,都可直观反馈。对不同应用等级,做到不同监控策略和报警策略。
-
自动化工具系统:对重复的、容易出错的、繁琐的工作尽可能工具化,通过小的策略组合,完成大的任务。
-
配置和管理系统:对于复杂的配置管理,尽可能web化、标准化、简单化,有模板定义,有规范遵循。
-
记录和分析系统:对发生的问题和数据做记录并分析,不断的总结、完善和提升。
#p#
下面就跟大家来一一介绍下:
3.1 全方位监控系统
Zabbix大家应该非常熟悉了,这里就不做介绍,主要介绍下cat监控。
-
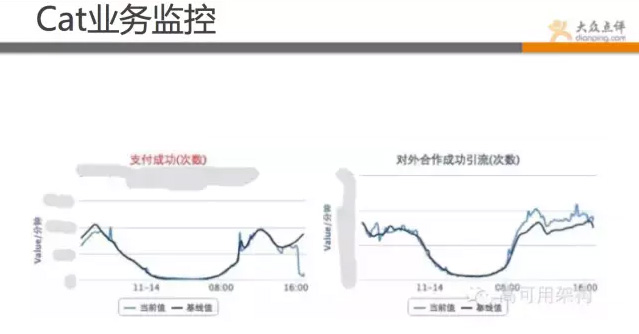
业务监控:
这张是cat的应用监控图表,可直观从业务角度看出问题,可跟基线的对比,发现问题所在。如图所示,此时支付远偏离基线,流量正常,可能后端出了问题。
除了这些,还有创建订单、支付、首页访问、手机访问等业务数据。
这张图是从业务角度来监控的。

这张也是从业务层面来监控的,该图展示的是手机的访问量趋势图,下面包括延迟、成功率、链接类型、运营商等都有明确数据,该监控可全方位覆盖业务。

-
应用监控:
从业务层面往下,就是应用层面。
应用状态大盘可清晰表示当前业务组件状态,如果某个业务不可用,其下面某个应用大量报错,说明可能是该应用导致。
该监控大盘十分清晰明的能展示业务下面的应用状态,可在某业务或者某域名打不开的时候,第一时间找出源头。
下图为应用报错大盘,出问题的应用会实时登榜(每秒都会刷新数据),当出现大故障时,运维人员可一眼看出问题;而当多个不同业务同时报错时,则可能是公共基础服务出了问题。

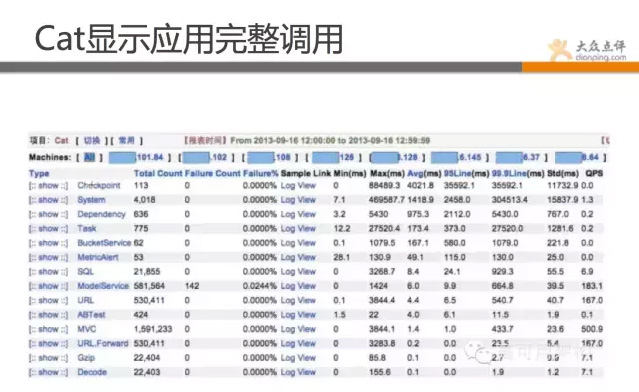
再看下图的这个功能,是Cat最强大的功能,能完整显示应用之间调用过程,做了什么事情,请求了那些,用了多长时间,成功率是多少,访问量是多大,尽收眼底。 Cat几乎无死角的覆盖到业务和应用层面的监控,当然还可做网络等层面监控,总之非常强大。这也是点评的鹰眼系统。
#p#
-
Logscan日志扫描工具:
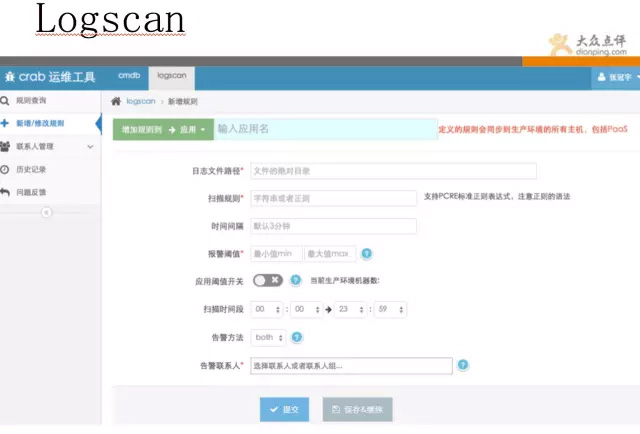
Logscan系统,是一套日志扫描工具,可根据你定义的策略,对日志内容进行定时扫描,该工具可覆盖到基于日志内容的检测,结合zabbix和cat,实现无死角覆盖。 比如有一些攻击的请求,一直遍历你的url,通过cat、zabbix等都无法灵活捕获,有了日志扫描,便可轻松发现。
3.2 自动化工作系统
首先介绍下点评的流程系统-workflow系统
顾名思义workflow是一套流程系统,其核心思想是把线上所有的变更以标准化流程的方式,梳理出来。
我们遵循一个理念,能用程序跑,就不去人操作。
流程有不同状态的转化,分别为发起、审计、执行、验证等环节。用户可自行发起自己的需求变更,通过运维审核,操作(大部分是自动的),验证。 如扩容、上线、dump内存、封IP等都为自动化流程。
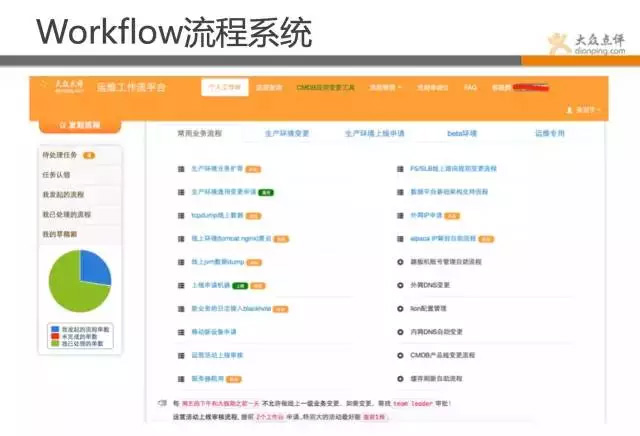
以我们线上自动化扩容流程为展示,用户使用时,需要填写对应信息,提交后,运维在后台审核过后,就完全自动化扩容,扩容完成会有邮件通知,全程运维不需要登录服务器操作。(自动化倒不是太复杂的技术难题,通过小的任务组合,设置好策略即可). 几十台机器的扩容,运维只需点个审核通过按钮,数分钟而已。
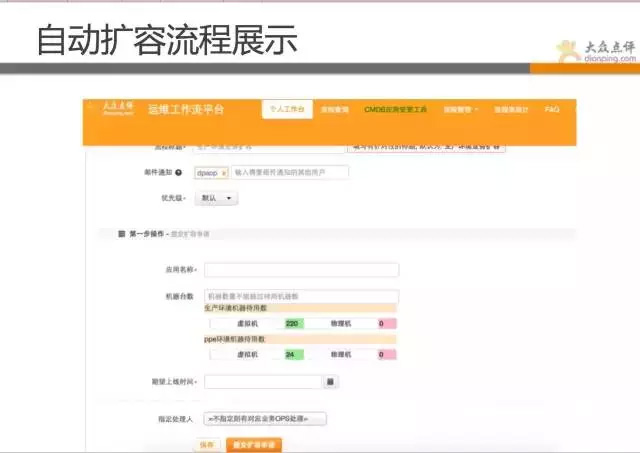
经过长时间的推广,点评现在98%以上变更都是通过工作流平台完成的,所有变更全部有记录,做到出问题时 有法可依,违法可纠。
而且通过流程单的使用频率,可做数据分析,了解哪些操作比较频繁,能否自动化掉,是否还有优化空间。 这才是做平台的意义,以用户为导向。
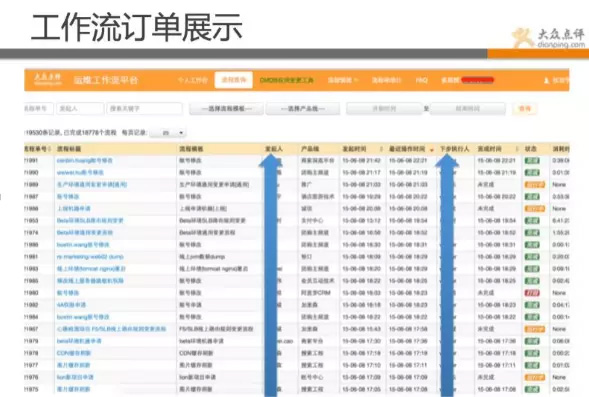
流程系统就介绍到这里,朋友们可关注下其中核心思想。
#p#
下面介绍另一套重量级核心系统:Button系统
Button是一套代码管理、打包、部署上线系统,开发可完全自主化进行上传代码,自动化测试,打包,预发,灰度上线,全部上线,问题回滚等操作。 全程运维不用干预,完全平台自主化。

点评的运维,除了有些没法自动化的手动配置下,其他基本都是开发自助。 这就是自动化的威力!
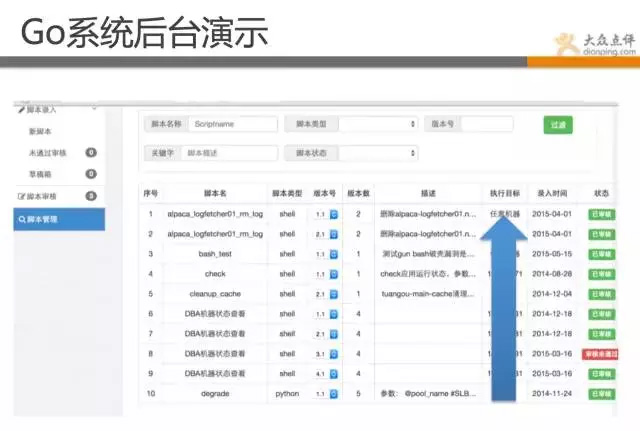
Go平台系统,是一套运维操作系统,其中包含了很多常规操作、如批量重启、降级、切换、上下线、状态检测等。
该系统主要是解决运维水平参差不齐,工具又各有各的用法,比如说批量重启操作,有用ssh、有用fabric、有自己写shell脚本的。 干脆直接统一,进行规范,定义出来操作,通过平台化进行标准化。 由于长时间不出问题,偶尔出一下,运维长时间不操作,找个批量重启脚本还要找半天。 哪些不能自动化的,我们基本都做到go里了,在这里基本都是一键式的傻瓜操作了。
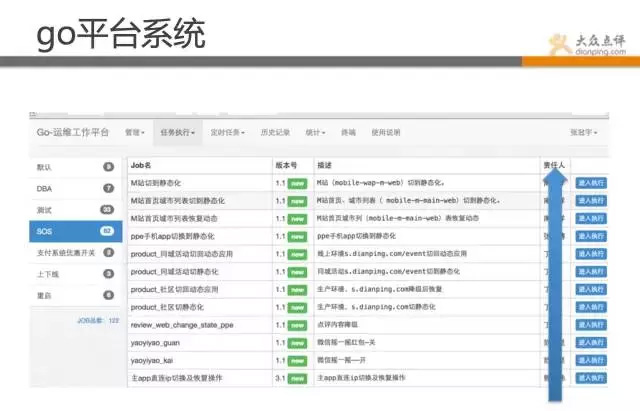
现在,我们监控团队就可以灵活操作,不需要有多高的技术含量,并且每次操作都有记录,做好审计和授权。
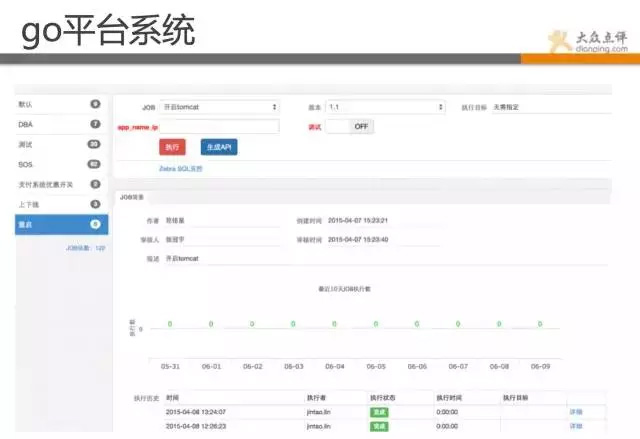
所有后台基本都是python、shell脚本实现,小的脚本组再整合成任务,这也是我们的重要理念之一。 对于比较复杂的任务,我们进行分解,然后用小的,单一的功能,组合起来完成复杂的操作(任务分解)。 其实我们实现自动化也是这个思路,先造零件,再拼装。
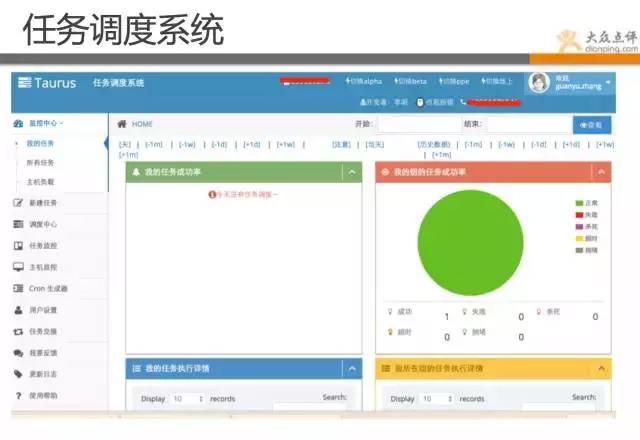
尽管有了puppet,go等工具,但对于一些job作业的管理,也显得非常吃力,我们架构组的同学做出一套任务调度系统。相当于分布式的crontab,并且有强大的管理端。 完全自主化管理,只需要定义你需要跑的job,你的策略,就完全不用管了。会自动去做,并且状态汇报、监控、等等全部都有记录,并实现完全自助化。

以上这些系统都非常注重体验,都有非常详细的数据统计和分析,每过一段时间,都有人去看,不断改进和优化,真正做到产品自运营。还有一些自动化系统就不一一介绍了。
#p#
3.3 配置和管理系统
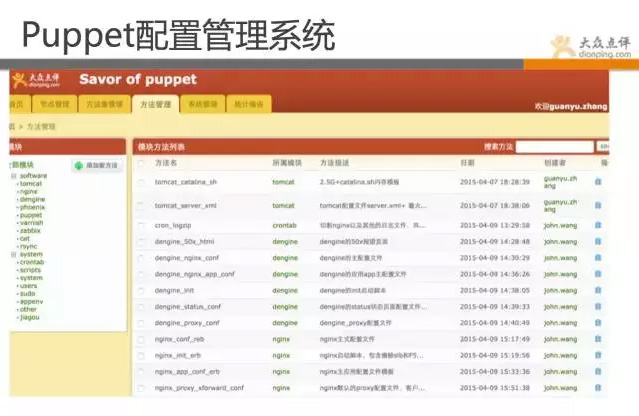
先介绍下puppet管理系统,相信不少同学对puppet语法格式深恶痛绝,并且也领教过一旦改错造成的故障严重性。
而且随着多人协同工作后,模板和文件命名千奇百怪,无法识别。
针对这些问题,点评就做了一套管理工具,主要是针对puppet语法进行解析,实现web化管理,并进行规范化约束。
跟go系统一样的想法,将puppet中模块进行组合,组合成模块集(方法集),可方便识别和灵活管理。
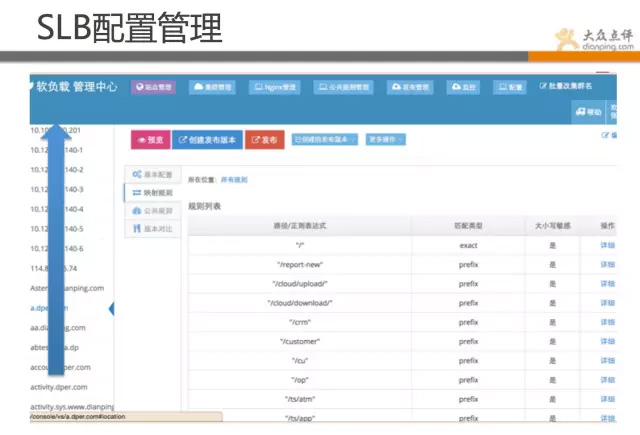
下面展示的是我们的软负载均衡管理页面,该系统是线上SLB的管理系统。 其核心在于把nginx语法通过xml进行解析,实现web化管理,傻瓜式配置,规范化配置,避免误操作,版本控制,故障回滚等。
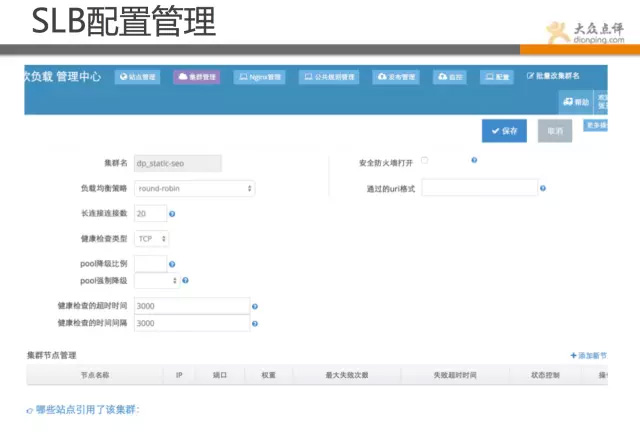
点评系统很多,基本上遇到个痛点,都会有人想办法把痛点解决。
下面就介绍下点评另一套强大配置系统,lion。
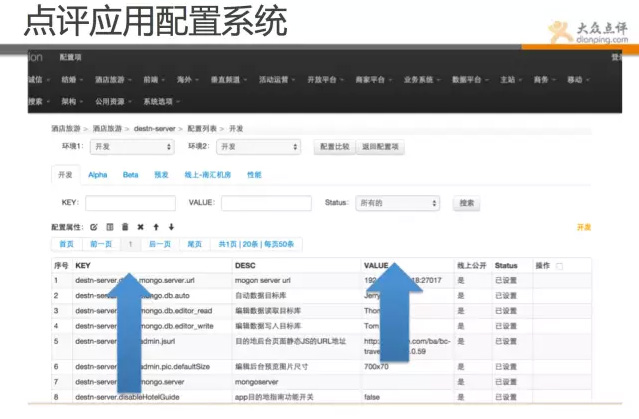
Lion是一套应用配置管理系统,点评的所有应用用到的配置,不在本地文本文件存储,都在一个单独系统存储,存储以key/value的方式存储。并且也是完全平台化,运维负责做好权限控制和审计。开发全部自助。
其核心是用了zookeeper的管理机制,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
是不是在点评做运维轻松很多?各种操作都工具化,自助化,自动化了。那运维还需要做什么。
#p#
3.4 记录和分析系统
此类系统虽然不怎么起眼,但对我们帮助也是特别大的,我们通过一些系统的数据记录和分析,发现了不少问题,也解决不少潜在问题,更重要的是,在这个不断完善总结的过程中,学习到了很多东西。
这个是我们故障分析系统,所有的故障都会做记录,故障结束后都会case by case的进行深入分析和总结。其实以上很多系统,都是从这些记录中总结出来的。

该系统为故障记录系统,每个故障都有发生的缘由和改进的方案,定期有人review。
运维起来很轻松吗?也不轻松,只是工作重点有了转移,避开了那些重复繁琐的工作,和开发同学深度结合,共同注重运营质量和持续优化。
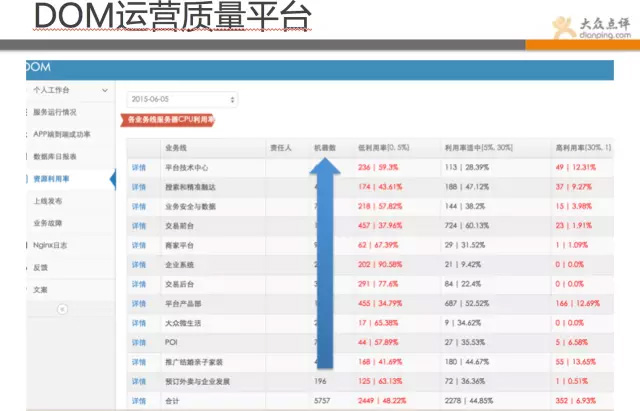
再来看下图所示是点评的DOM系统,即运营质量管理平台,该平台汇总了线上的服务器状态、应用响应质量、资源利用率、业务故障等全方位的数据汇总平台。
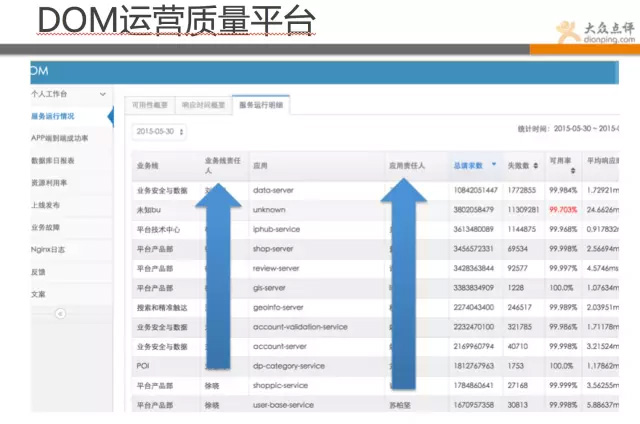
并通过同比和环比,以及平均指标等数据,让各开发团队进行平台化PK,性能差的运维会去推动改进。
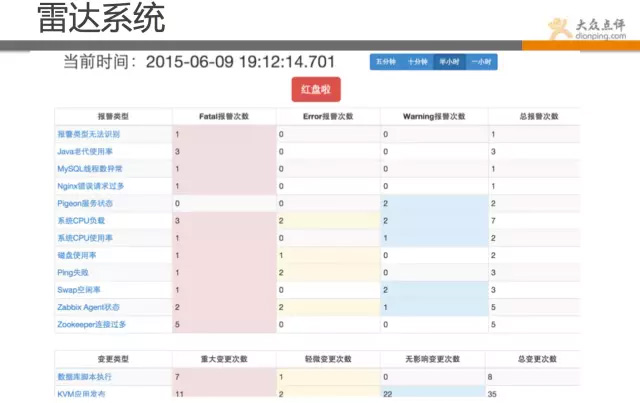
最后一个需要介绍的是雷达系统,该系统是我们最近在做的,一个比较高大上的项目。
朋友们也感受到了,我们系统之多,出问题查起来也比较费时。 不少同学生产环节也遇到过类似问题,出了问题到底是什么鬼?到底哪一块引起的呢? 结合这个问题,我们把线上的问题做了个分类,并给了一些策略层面的算法,能快速显示。 可让故障有个上下文的联系,如:上线时间、请求数下降、错误数增多等,哪个先出现,哪个后出现? 当然,这块功能还在做,目标是实现 出问题的时候,一眼就能从雷达系统定位问题类型和范围。
以上向大家演示的就是点评的运维系统,相信我们点评的运维思想都在里面体现了。
运维点评这几年的发展,主要目标是实现平台规范化、运维高效化、开发自主化 。
之前也是通过运维root登录,然后写脚本批量跑命令的低效运维。也经历过CMDB系统信息不准确,上线信息错乱的尴尬局面。也遇到过出了很大问题,运维忙来忙去,找不到rootcase。
好在,通过努力,这些问题现在都有了很大改观,相信朋友们通过展示的系统,能感觉出点评运维的进步。
#p#
4、运维踩过的坑和改进的地方
我就这些年,点评运维出的一些case案例,跟大家聊一聊我们做了哪些具体工作:
-
变更不知道谁做的,无法恢复,变更完也找不到根据,造成重大故障。//之前线上puppet通过vim的管理方式,由于运维同学失误推了一个错误配置,导致全部业务不可用1个小时,我们后面通过规范puppet配置修改并做成工具,进行权限控制,还加了流程系统,进行避免。
-
出了问题,开发说代码没问题,运维说环境没问题,该找谁?//我们后面做了工具,通过DOM和cat系统,可进行深度诊断,基本很容易定位问题所属。
-
执行了个错误命令,全线都变更了,导致服务不可用。//我们通过go系统,进行日常操作梳理,并做成工具,运维90%操作都可通过自动化流程和go平台完成。大大缩减故障产生率,并且之后进行权限回收。
-
出问题了,各种系统翻来查去,无法快速定位,找不到rootcase。//点评正在做雷达系统,就是将历史存在的问题,进行复盘,将一些故障类型,进行分级,然后通过策略和算法,在雷达系统上进行扫描,出问题环节可快速第一时间优先显示。
-
运维天天忙成狗,还不出成绩,天天被开发吐槽。//点评这两年完全扭转了局势,现在是运维吊打开发,因为我们目前,大部分系统都实现了开发自助化,运维被解放出来,开始不断完善平台和关注业务运营质量,我们dom系统是可定制的,运维每天都把各业务的核心指标报表发到各位老大那里,哪些服务质量差,响应慢,开发都会立即去改。(当然,需要老大们支持)。
5、未来关注的领域和方向
点评也有些前沿的关注点,比如比较热的Paas技术。
PaaS和云很热,还有docker技术,点评也不能掉队,目前点评有数千个docker的实例在跑线上的业务。
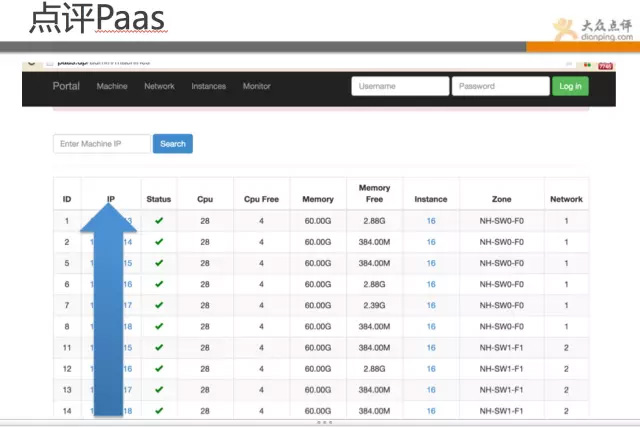
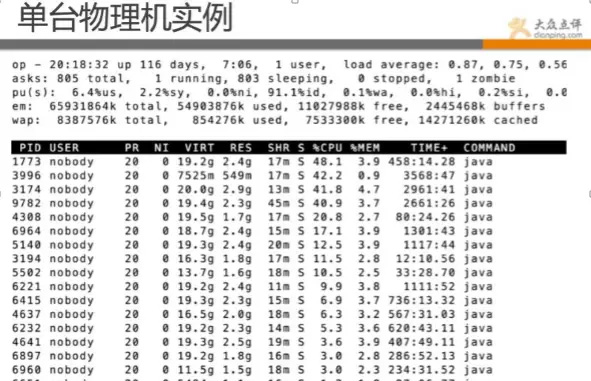
上图java都是跑的docker实例
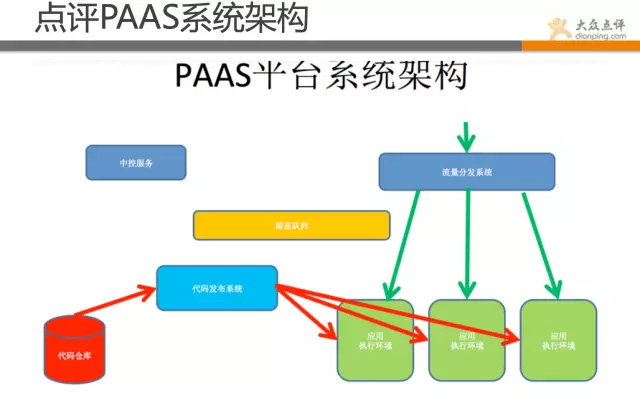
目前点评Docker这块可做到10秒内快速部署业务并可响应用户请求。30秒内可完成一次实例无缝迁移。 个人感觉docker技术不在于底层这块,在于上层管理系统的构造。底层一方面是持续优化,挖掘性能,但更重要的是在策略层和调度层。 如何快速部署、迁移、恢复、降级、扩容等,做好这些还有不少挑战。
点评这两年成长很多,但需要走的路也很多,未来关注的点会在多系统的有机整合和新技术的尝试以及发展,还会更多的关注智能策略层面。
结束语
在最后结束时,感谢各位到场朋友捧场,也感谢点评运维和平台架构的每一位同事,有了你们,点评运维才走到了今天,我们共同努力,来创造新时代的运维体系。
点评很多系统都是第一次拿出跟大家分享,大家可看一下设计理念和思想。
如何一起愉快地发展
这是一个新的时代!每个人都有自己的声音,值得被尊重,并且有机会被尊重。
高效运维系列微信群于2015年4月底创建,已然成为国内高端运维圈子,主力成员分布甚广,不仅来自互联网大厂,更有包括移动、银联、农业等各产业朋友。“高效运维”公众号值得您的关注。本公众号基本上每天一篇文章(90%为原创),来自高效运维系列群的讨论精华,“高效运维”也是InfoQ专栏《高效运维最佳实践》及运维2.0官方公众号。
来吧朋友,共襄盛举。
重要提示:如需转载本文,请必须全文转载,并包括本行及如下二维码。