网络虚拟化(Network Virtualization)对于很多网络工程师尤其是刚入行的新手常常有一种懵懵懂懂,不甚了然的神秘感觉,虽然常常为之想入非非,最终还是似是而非。在这篇BLOG里面,除了举例,不涉及具体的技术和实现,尽量展现网络虚拟化背后的最基本的原理(Rationale)和思想(Idea)。可能很多人都发现,理解网络技术和协议背后的原理和思想比具体配置操作这些技术和协议更重要,这就是说,知其然当然很好,但更好的是知其所以然。毫无疑问,这一原则同样地适用于其他计算机科学领域。
虚拟网络也是网络
一般地,一个虚拟网络是在物理网络或在其他虚拟网络之上,用软件的方法构造出的逻辑网络(Logic Network),以实现用户定义的网络拓扑(Networking Topology)并满足用户特定的需求。主要应用的场景是多租户云计算数据中心,在下文中,我们还要展开讨论。上面的定义其实没有真正揭示虚拟网络的内涵,实际上,虚拟网络也是网络,如果从网络是什么这个简单得常常被忽略的问题出发,来探讨虚拟网络的具体内涵,似乎更容易抓住这一概念的本质。我们可以从静态和动态两个角度来审视网络:
从静态的角度来看,网络可表示为数据结构中的图(Graph),网络的节点(如交换机和路由器,一些文献把他们统称为Datapath)是为图的顶点(Vertex),而链接(Link)就是图的边(Edge),这就是网络的拓扑视图。对于每一个网络节点,其数据(Data Traffic)转发行为由一系列的查询表(Lookup Table)如二层MAC表(L2 MAC Table)、三层路由表(L3 FIB Table),ACL(Access Control Lists)表来定义。当从某个端口收到一个数据报文(Packet)或数据帧(Frame)时,转发引擎(Forwarding Engine)通过解析,查表,应用策略(如 QoS),最后,将报文或帧从另一个端口转出。这里只是给出非常粗略的描述,实际的情况要复杂很多,其实这也就是我们平常所说的网络的数据平面(Data Plane),对应于物理交换机的交换芯片的转发引擎的功能。当然,也可以看做SDN模式下,由Controller控制的数据转发设备(如OpenFlow交换机)。
从动态的角度来看,网络把数据流(Data Traffic)从一个和网络连接的主机(Host)送到另一个和网络连接的主机,这里,主机可以是物理服务器,也可以是虚拟计算机(Virtual Machine)。为此,事先要有一个定义好的地址空间,每个主机和网络节点都被分配(动态的或静态的)一个唯一标识自己的地址,如IP地址。这样,根据地址就能够识别出每个主机在网络中的位置,即接入网络的入口节点。两个主机要交换数据,首先要计算出他们之间的数据流的通路,上文把网络比作数据结构的图,这里的通路当然相当于图中的路径(Path)了,可表示为一个向量,其中的每个元素代表一个网络节点/顶点,两个相邻的网络节点/顶点之间有链路/边相连接,向量的头元素和尾元素分别与通信的主机相连。数据流透过这一通路,经过中间网络节点的中转,就从源主机到达目的主机。几乎所有的L3路由协议,无论是距离矢量(distance-vector)路由协议如BGP还是链路状态(link-state)路由协议如OSPF,顾名思义,都有一个简单的目标,就是计算并生成主机或子网之间的路由,即通路,并最终将具体的Route Entries安装到网络节点的FIB中。本质上,L2的网络也有自己的机制来计算通路,转发数据,如Ethernet交换机通过MAC地址学习(MAC Learning)来获取数据帧的Egress端口,从而将数据流转发到目的主机。上述的这一动态过程是由网络的控制平面(Control Plane)来管理的,网络操作员(Network Operator)通过控制平面配置L2/L3的路由和转发协议,达到数据在主机之间交换的目的。对应于交换机,控制平面就是运行在CPU之上的操作系统;而对于SDN的模式来说,控制平面是由Controller及上面的应用来实现的。更通俗地讲,在两个主机交换数据之前,网络的控制平面需要回答三个问题:第一,你是谁?(目的主机的地址是什么?);第二,你在哪里?(目的主机和网络的哪个节点连接?);第三,如何找到你?(到达目的主机的通路如何建立?)。
简单总结一下,网络有两部分构成:第一,由网络节点(datapath)作为顶点和网络链接作为边构成的静态的拓扑图;第二,由各种网络协议构成的动态的数据流路由转发机制。若是忘掉那些枯燥繁杂的各式各样的系统、设备、协议的配置细节,网络其实就是这点事儿,看起来并不复杂。虚拟网络作为逻辑意义上的网络,具备网络的所有组成要素,包括网络拓扑,如网络节点、链接、网络节点中的查询表等,相对于物理网络,这些只不过是虚拟的,逻辑的,软件实现的。同样地,虚拟网络也可以是L2网络或L3网络,分别使用不同的控制平面管理,因此也是可配置的。
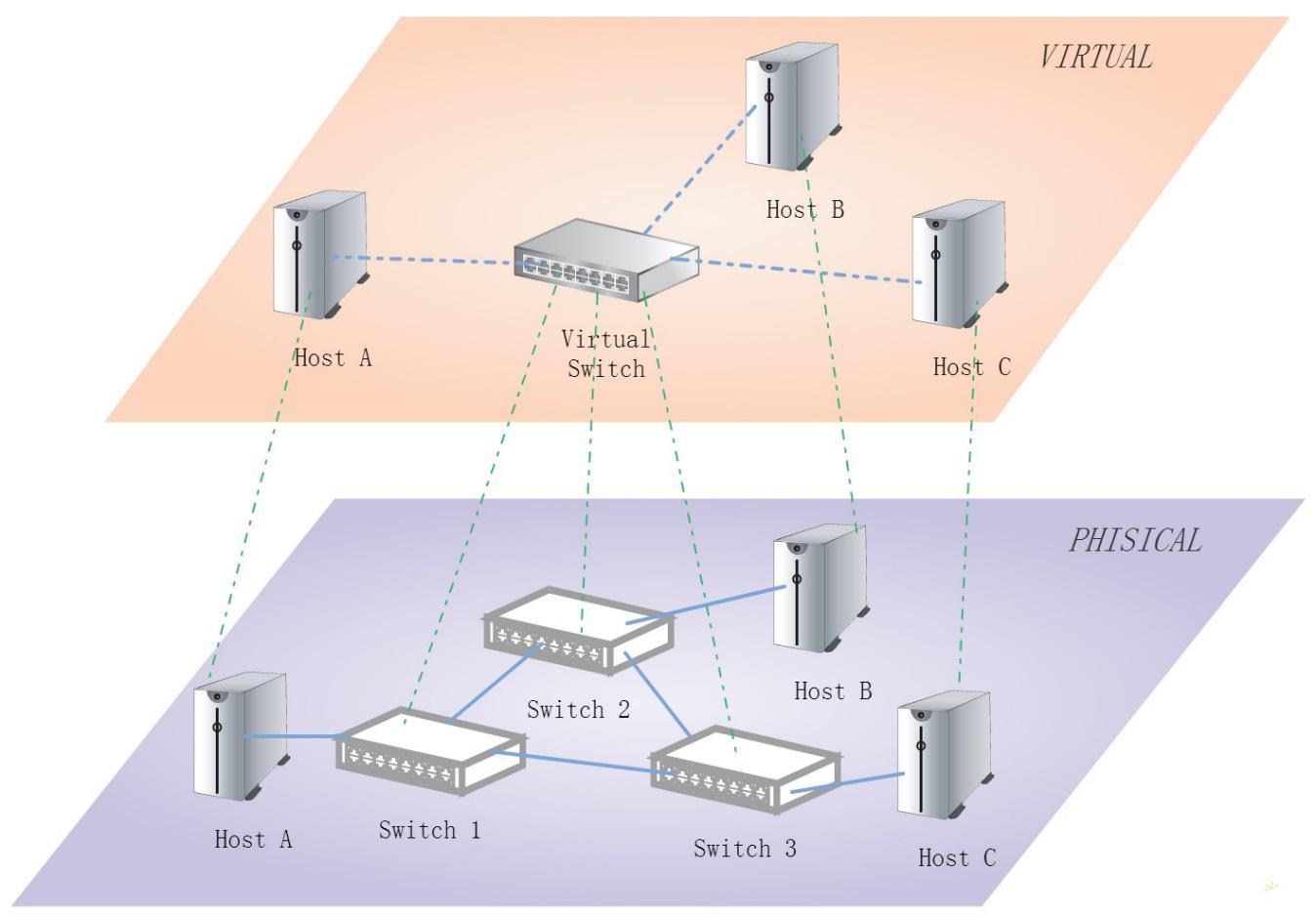
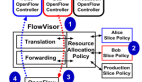
文献1在讨论SDN(Software Defined Networking)编程语言Pyretic的拓扑抽象(Topology Abstraction)时,使用了一种叫做Network Object的机制,实际上就是给编程用户提供了一个虚拟网络。上图是Network Object的一个多对一(many-to-one)的示例,对于用户而言,可见的(Visible)是上面的一个虚拟交换机连接三个主机的虚拟网络,而不是下面的由三个交换机组成的物理网络。这一虚拟网络对于实现某些应用提供了极大的方便,假设给定一个SDN的Controller,使用OpenFlow实现一个类似L2网络的MAC-Learning模块时,开发者就只需面对单独的一个虚拟交换机,而不必考虑物理网络的复杂的拓扑结构,也无须考虑如何用spanning tree来避免循环回路的细枝末节,从而只要把相关的Flow Entries安装在这一个假设支持OpenFlow的虚拟交换机上,何等简单快捷。而对于虚拟交换机到物理交换机的映射,则由Pyretic的runtime系统来完成,它还要把用户安装到虚拟交换机上面的Flow Entries转换成各个物理交换机的Flow Entries并安装到物理交换机上。具体的细节可阅读文献1。
实际上,虚拟网络也并不是什么新概念。目前广泛使用的VLAN技术就是把一个物理的L2网络变身为多个逻辑的虚拟L2网络,与此同时,也把一个广播域(broadcast domain)分隔成多个广播域。而VRF(VPN Routing/Forwarding)之于L3就如同VLAN之于L2,VRF可以使一个物理路由器(Router)拥有多个FIB,从而把单一的路由器分隔成多个“虚拟”的路由器,以支持不同的VPN实例(Instance)。这是两个一对多(one-to-many)的虚拟网络的例子。
虚拟网络所为何事
虚拟网络的兴起不是偶然的,这要从云计算说起。云应用模式下,存在着多个云资源的租赁者(Tenant),所有的租户共享云服务商的物理基础设施,包括服务器,存储,网络,这就形成了多租户模式(Muti-Tenancy)。这种方式特别地受到资金并不富裕的互联网创业公式的青睐。租户希望云服务商提供的网络作为自身企业网络自然的延伸和扩展,所谓“自然”就是不需要改变自身网络配置的情况下和云服务商提供的网络资源无缝的集成在一起。与此同时,也能够把自身企业网络承载的应用和服务自然地迁移部署到云服务商的网络上。对云服务商的数据中心来说,传统的L2/L3的网络技术很难适应这个难度很高的技术挑战,必须改变已有的网络管理的模式和向租户提供网络资源(provision)的方式。
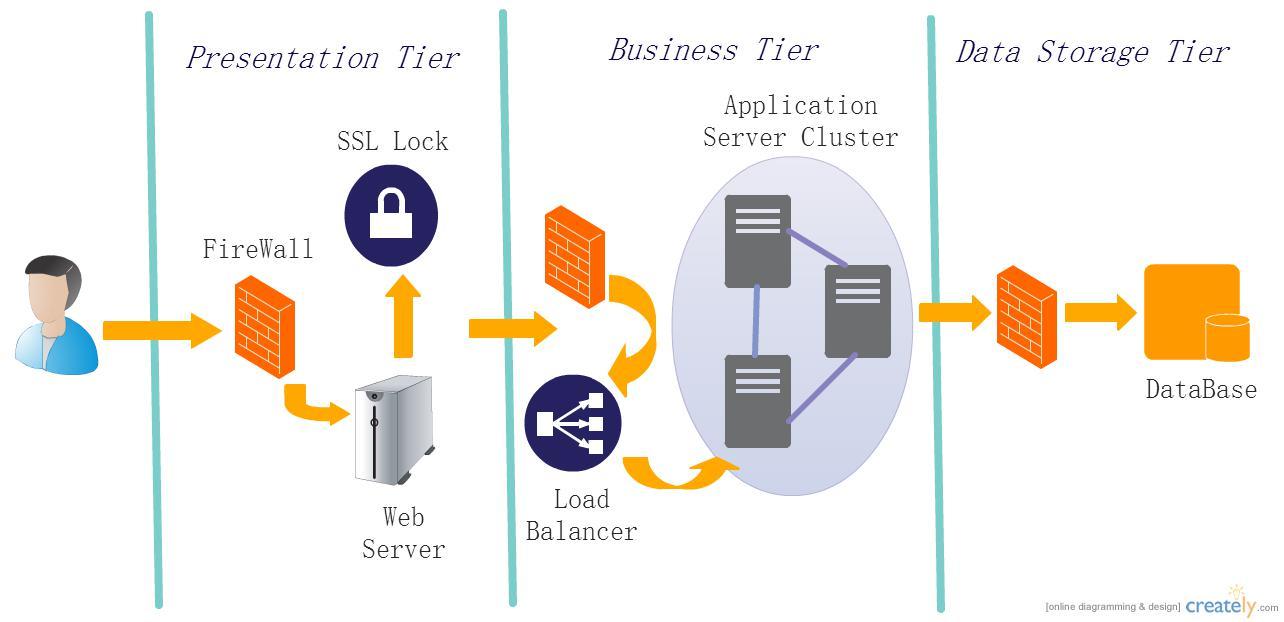
租户希望快速的把自己的应用部署到云服务商提供的网络、计算和存储的资源,而且这些资源要具有高度的可扩展性和可伸缩性。比如某租户在云端的数据中心部署一个典型的Web应用,一般地,Web应用有表示层(Presentation Tier)、业务层(Business Tier)和数据层(Data Storage Tier)构成,各层之间相互隔离,由复杂的网络连接完成数据交换,如下图所示。联通这些服务器或虚拟机,需要网络管理员一个设备一个设备的配置,这是极其琐碎且很容易出错的工作,需要耗费很长的时间反复调试。另外,这样的Web应用对计算和存储资源的需求是可扩展的和可伸缩的,意味着连接这些计算和存储资源的网络拓扑也要随之变大变小,无疑更加重了配置的工作。更加不幸的是,云服务提供商的数据中心要承载成千上万的倏兴倏灭的不同租户的应用,这些应用对部署的时间往往有苛刻的要求。并且,出于安全的考虑,不同应用之间的网络还要实施严格的隔离,不允许有数据交换。所以必须以更加高效的灵活的可靠的方式向租户的应用提供动态变化的网络服务。
一方面,租户能够快速的获取虚拟的计算和存储资源,另一方面,却需要较长时间等待网络资源配置的完成。面对云模式下新的应用需求,网络陷入了疲于奔命的尴尬的窘境,等待着虚拟化的救赎。计算存储资源的虚拟化通过hypervisor的技术已趋成熟,云计算虚拟化的最后一里路就是网络的虚拟化。这意味着,云服务商给租户的网络是虚拟网络,尽管使用相同的底层物理网络的基础设施,每个租户得到的虚拟网络(包括控制平面和数据平面)却是相互独立的,完全隔离的,通过云服务商提供的控制平面,租户可任意的配置管理自己的虚拟网络。更为重要的是,在软件的帮助下,虚拟网络可以很快地交付给租户。加上虚拟的计算和存储资源,每个租户的虚拟资源形成一个完整的VPC(Virtual Private Cloud)。虚拟网络隔离的特性使得每个虚拟网络可以使用重叠的甚至相同的地址空间,而不必担心相互干扰。如两个L3的虚拟网络都可以使用10.0.0.0/8作为自己的地址空间,一个L2的虚拟网络不可能看到或学到另外一个L2虚拟网络的设备的MAC地址,更不可能通过L2协议交换数据。对于混合云(Hybrid Cloud)的租户,这是极大的方便,因为云端的虚拟网络可以使用租户自身网络的地址空间,而不用考虑这一地址空间是如何定义的。
如果我们把这种计算、存储和网络资源的租赁模式看做云,那么,正是虚拟技术把计算的云装扮成云卷云舒的曼妙世界。
Overlay助力虚拟网络
从现有的产品和解决方案来看,虚拟网络大多是借助于Overlay的技术实现的,如VMware的NSX。Overlay网络也是一个网络,不过是建立在Unerlay网络之上的网络。Overlay网络的节点通过虚拟的或逻辑的链接进行通信,每一个虚拟的或逻辑的链接对应于Underlay网络的一条路径(Path),由多个前后衔接的链接组成。需要注意的是,Overlay网络和Underlay网络是相互独立的,Overlay网络使用Underlay网络点对点(peer-to-peer)的传递报文,而报文如何传递到Overlay网络的目的节点完全取决于Underlay网络的控制平面和数据平面,报文在Overlay网络Ingress和Egress节点的处理(如抛弃,转发)则完全由Overlay网络的封装协议来决定。Overlay/Underlay既不新鲜,也不神秘,比如在TCP/IP的Layer模型中,L3的IP网络可以看做L2的Ethernet网络的Overlay网络,而L2的Ehernet网络就是L3的IP网络的Underlay网络。
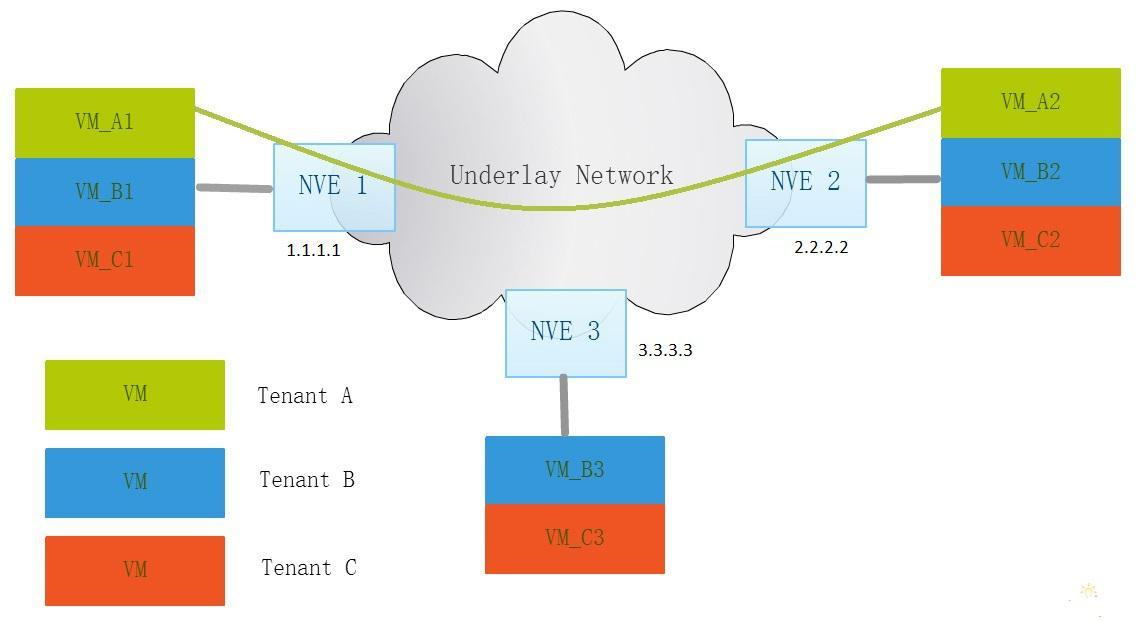
由此不难看出,在向租户提供虚拟资源租赁服务时,每个租户的虚拟网络就实现为以云服务商数据中心IP网络为Underlay网络的Overlay网络。上图给出了云服务数据中心虚拟网络功能模块的简单示意图,省略了许多细节。假设每个物理服务器中装有多个不同租户的虚拟机,如Tenant A,Tenant B和Tenant C,图中分别以不同的颜色来标识。租户的虚拟机通过物理的或逻辑的链接接入IP网络(即Underlay网络)的虚拟边缘设备(NVE, Network Virtualization Edge)。NVE是实现虚拟网络的关键模块,它可以实现为Hypevisor的虚拟交换机的功能,也可以在物理交换机或路由器中实现。对于一个给定租户的虚拟网络,NVE帮助建立终端节点到终端节点的逻辑链接,即隧道。要完成这一任务,在每个NVE中维护一个可达信息(Reachability Information)的MAP表,结合我们的例子,其内容如下。根据实现技术和隧道封装协议的不同,可达信息的内容和形式也会大相径庭,这里只是为了说明的方便,给出一个简化的版本。在表中,Address指的是NVE的地址,VNID(Virtual Network Identifier)是虚拟机VM所属的虚拟网络的全局唯一ID,每个租户可以有一个或多个虚拟网络,VAP(Virtual Access Point)是VM接入NVE的虚拟接口,NVE可用它来判断报文来之哪个VM。假设Tenant A的虚拟机VM_A1向VM_A2发送一个报文,NVE 1得到这个报文后,就可以进行隧道封装,具体如何封装由隧道的封装协议来定义,一般地,封装之后,外层的封装协议的协议头中必定包括如下信息:虚拟网络的ID,源IP地址和目的IP地址,外层的源IP地址就是NVE 1(Ingress)的IP地址,外层的目的IP地址就是NVE 2(Egress)的IP地址。这些封装信息都可以从关键的可达信息MAP表中获取。封装后的报文就可以作为普通的IP报文在Underlay的IP网络中从一个NVE传递到另一个NVE。NVE 2收到报文后,解封装,根据VNID及报文本身的地址信息,将报文转给VM_A2。
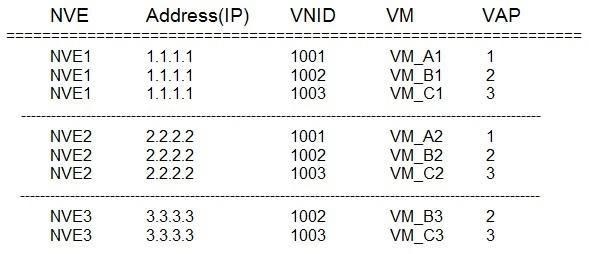
NVE是如何获取可达信息MAP表的呢?这由虚拟网络或Overlay网络的控制平面完成,有两种方法:第一种方式可称为分布式的方法,NVE首先得到和其直接相关的可达信息,即直连的VM和VM的VNID,然后NVE之间直接对话,相互交换可达信息,VM和NVE之间以及NVE和NVE之间要有定义好的标准的对话协议,这和传统的路由协议的原理完全一样,其缺点是需要就这些对话协议单独配置每个NVE;第二种方式是集中式的方法,也就是SDN的方法,SDN的三个显著特征就是数据平面与管理平面隔离,集中式管理和可编程,因此,可达信息可通过类似于OpenStack的Orchestration系统配置计算和存储资源时自动生成,再由控制器(Controller)中转到每个参与的NVE,这是一个自动配置的过程(Automatic Configuration),可快速向租户交互云端的网络虚拟资源。SDN的方法的最大优点就是一个字,快!因此,这会是云计算数据中心部署SDN解决方案的最大动力。可达信息MAP表还是支持VM动态迁移的秘密所在,一个VM无论迁移到哪个物理服务器上,只要通过上述两种方式使得每个NVE的可达信息MAP表及时更新,就能够保持该VM与外界的正常通信。
VXLAN:看个例子吧
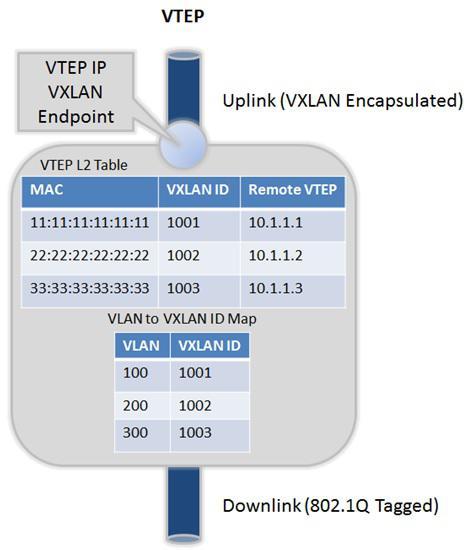
目前,数据中心实现虚拟网络最为看好的封装协议就是VXLAN,背后有Cisco和VMware的支持。VXLAN是以IP网络作为Underlay网络,向租户提供L2的虚拟网络,当然也是Overlay网络。VXLAN把租户的Ethernet数据帧(Frame)封装到UDP报文中,如下图(来自文献6)。然后,在Underlay的IP网络中通过隧道从一个VTEP(VXLAN Tunnel End Point)传递到另一个VTEP,不难理解,VTEP相当于上文中的NVE,而VXLAN ID就相当于上文的VNID,VXLAN ID有24位的编码空间,大大超过VLAN的12位编码空间。

VXLAN的可达信息MAP表有两个表:VTEP L2 Table和VLAN to VXLAN ID MAP, 如下图所示(来自文献6)。Ingress VTEP封装时,从VLAN ID查询到VXLAN ID,然后根据MAC和VXLAN ID得到远端的Egress VTEP的IP地址;Egress VTEP解封装时,其过程与之相反。
文献6和文献7是非常好的有关VXLAN的技术文档,有兴趣了解VXLAN更多细节的朋友可参考这两篇文档。其他类似的协议还有STT(Stateless Transport Tunneling)和NVGRE,请参考文献8。
参考文献
1. Composing Software-Defined Networks.
2. Network Virtualization in Multi-tenant Datacenters.
3. Cloud computing.
4. Framework for Data Center (DC) Network Virtualization.
5. Problem Statement: Overlays for Network Virtualization.
6. VXLAN Deep Dive.
7. VXLAN Deep Dive – Part II.
8. Tunneling for Network Virtualization.