摘 要:本文 主要介绍了HBaseRegionServer与Zookeeper间的交互过程,阐述RegionServer崩溃后的恢复机制,并在此基础上提出了几点优化的恢复措施。优化后的恢复措施大大缩短了RegionServer崩溃后的故障恢复时间和业务中断时间,从而提高了HBase集群的稳定性和可靠性。
0 引言
随着互联网和通信行业的迅猛发展,积聚的各种数据呈急剧增长态势。这些海量数据既蕴含着丰富的信息和资源,又面临着信息有效管理和提取的难题。云计算是分布式处理、并行处理和网格计算的发展,可以提供近乎***的廉价存储和计算能力,特别适合于日益暴增的海量数据的存储和处理。在云计算领域中,Hadoop体系独树一帜,其丰富的子系统可以满足多种领域和行业的应用需求,而其中的HBase作为一种非结构化数据库,特别适合于各种非结构化和半结构化的松散数据的存储和管理。
HBase是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式存储数据库系统[1-3]。HBase建立在HDFS分布式文件系统基础之上,其中的数据最终以HFile的格式存储在HDFS之上;HBase可以通过内嵌的MapReduce组件实现复杂任务的并行和分布处理,具有很高的性能。
1 HBase体系结构
HBase主要由HMaster和RegionServer两部分组成,辅以Zookeeper协调集群中各网元之间的数据共享和访问,其组成框图如图1所示[4]。
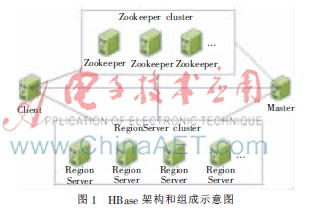
(1)Client:访问HBase的接口,维护着一些加快HBase访问的缓存,比如Region的位置信息等。
(2)Master:负责Region到RegionServer的分配以及映射关系维护;管理集群中的RegionServer及其负载均衡;维护数据表和其所在Region的元数据信息;处理表级的操作请求等。
(3)RegionServer:维护Master分配给它的Region,处理对这些Region的读写请求;负责运行过程中过大的Region的Split和Compact操作。
(4)Zookeeper:保证任何时候集群中只有一个激活的Master;存储RootRegion和Master的位置;存储所有RegionServer的位置并实时监控其状态;存储HBase的其他运行所需的信息[5]。
HBase中的数据单元通过主键、列簇、列名和版本号唯一确定,所有行按字典顺序排列。HBase中的表在行的方向上分割为多个Region,每个Region只存储表中某一范围的数据,并且每个Region只能被一个RegionServer管理。Region由一个或者多个Store组成,每个Store保存一个列簇;Store又由一个MemStore和0至多个storefile组成,storefile以HFile的格式存储于HDFS上。
由此可见,HBase中的表通常被划分为多个Region,而各个Region可能被不同的RegionServer所管理。客户端通过Master和相关操作获取目标Region的位置后,最终通过RegionServer完成对用户表的读写请求。因此,如果某个RegionServer异常,客户端对其所管理的Region的访问就会失败,造成了业务中断,这在在线系统中是不可接受的。虽然HBase中实现了RegionServer异常后的自动恢复机制,但是这种机制的时延很大,不能满足实际应用需求。因此,本文针对这部分进行了研究,并提出了一种可以快速、高效恢复业务的方法。
2 HBase集群与Zookeeper交互机制分析
在HBase的使用过程中,Zookeeper起着至关重要的作用。正是Zookeeper的存在,使得HBase的运行更加稳定和高效。
在配置环境中,Zookeeper集群中的HBase的目录如图2所示。
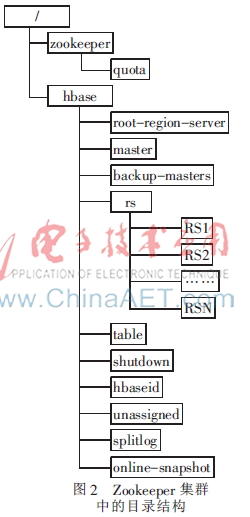
HBase集群的相关信息存储在Zookeeper集群中的hbase目录(这个目录是可以配置的)下,其中master目录存储HMaster的位置等相关信息,rs目录存储所有的RegionServer的位置等相关信息。
在HMaster启动时,会在Zookeeper集群中创建自己的ZNode临时节点并获得该节点的独占锁,该节点位于Zookeeper集群中的/hbase/master目录下。同时会在所有的其他目录上创建监听,这样当其他节点的状态发生变化时,HMaster就可以立即感知从而进行相应的处理。
在RegionServer启动时,会在Zookeeper集群中创建自己的ZNode临时节点并获得该节点的独占锁,这个节点位于Zookeeper集群中的/hbase/rs目录下。
RegionServer会通过Socket连接向Zookeeper集群发起Session会话,会话建立后在Zookeeper集群中创建属于自己的临时节点ZNode。这个节点的状态是由Zookeeper集群依据Session的状态来维护的。
RegionServer作为客户端,向Zookeeper集群的Server端发起Session会话请求。Session建立后,会以唯一的SessionID作为标示。Client会定期向Server端发送Ping消息来表达该Session的存活状态;而Server端收到Ping消息时会更新当前Session的超时时间。如此,对于Client而言,只要Ping信息可达则表明该Session激活;对于Server而言,只要Session未超时则表明该Session激活。
在Server端,Zookeeper会启动专门的SessionTrackerImpl线程来处理Session的相关状态迁移问题,该线程每隔tickTime(Zookeeper配置文件中指定,默认为2 s)时间遍历一次Session列表,如果超时则立即关闭此Session,同时删除与该Session关联的临时节点,并将该事件通知给注册了该节点事件的组件。在HBase集群中,这就意味着如果RegionServer崩溃,则Zookeeper需要在Session超时后才能通知Master,后者才能启动故障恢复。
而Session的超时时间是这样确定的:HBase默认的Timeout为180 s,在创建Session时会将该参数传递给Server端。最终协商确定的Session的超时时间由Zookeeper的配置参数决定,处于Zookeeper集群minSessionTimeout和maxSessionTimeout之间。默认的minSessionTimeout=2×tickTime(默认2 s)=4 s,maxSessionTimeout=20×tickTime=40 s。不管Client传递的Timeout多大,最终协商确定的Session的Timeout时间都在4~40 s之间,实现代码如下。如果一切按照默认配置,则Session的Timeout为40 s。
- int sessionTimeout=connReq.getTimeOut;
- int minSessionTimeout=getMinSessionTimeout;
- if(sessionTimeout
- sessionTimeout=minSessionTimeout;
- }
- int maxSessionTimeout=getMaxSessionTimeout;
- if(sessionTimeout>maxSessionTimeout){
- sessionTimeout=maxSessionTimeout;
- }
- cnxn.setSessionTimeout(sessionTimeout);
经以上分析,可以得出以下结论:Session存活意味着RegionServer存活;Session超时意味着RegionServer启动时创建的ZNode节点被删除,也就表明该RegionServer异常。
#p#
3 HBase中RegionServer异常后的恢复机制分析
通过以上的分析可以看出,当HBase集群中的一个RegionServer崩溃(如RegionServer进程挂掉)后,此时该RegionServer和Zookeeper集群的Server间的Socket连接会断开,但是二者之间的Session由于有超时时间的存在而不会立即被删除,需要等到Session超时之后才会被Zookeeper集群删除,只有Session超时了Zookeeper集群才会删除该RegionServer启动时创建的临时节点。只有Zookeeper集群中代表此RegionServer的节点删除后,HMaster才可以得知该RegionServer发生故障,才能启动故障恢复流程。HMaster恢复故障时,将故障RegionServer所管理的Region一个一个重新分配到集群中。
由此可得出以下结论:Session Timeout的存在使得HMaster无法立即发现故障RegionServer,从而延迟了故障的恢复时间,间接增加了业务中断的时间。同时,HMaster重新分配Region的处理过程效率太低,尤其是Region数目很大时。
4 改进的RegionServer异常后的恢复措施
针对以上场景,本文进行了如下改进:
(1)在RegionServer的启动脚本中加入特殊处理的代码,在该RegionServer的进程结束前自动删除其在Zookeeper集群中创建的ZNode节点,这样HMaster就能立即感知到RegionServer的状态异常事件,尽早地启动异常恢复,代码如下。
- cleanZNode
- {
- if[-f $HBASE_ZNODE_FILE];then
- #call ZK to delete the node
- ZNODE=`cat $HBASE_ZNODE_FILE`
- $bin/hbase zkcli delete $ZNODE>/dev/null 2>&1
- rm $HBASE_ZNODE_FILE
- fi
- }
(2)在HMaster的恢复过程中加入特殊处理的代码,通过批量处理,将故障RegionServer所管理的Region一次性地分配到集群中,如同HBase集群启动时批量分配Region的过程,提高Region分配的速度。所谓批量分配,就是先获取故障RegionServer所管理的Region数目rn和存活的RegionServer的数目rs,按照平均负载的原则,在每个存活的RegionServer上分配rn/rs个Region。这样就可以将多个Region一次分配给一个RegionServer;而原来的分配过程则是一次分配一个Region到一个RegionServer上,显然改进后的处理效率更高,尤其是Region数目较多时尤为明显。
采用以上的处理方式后,HBase集群中当一个或几个RegionServer发生故障后,业务的恢复速度提升了几十倍,从最初的故障恢复时间40 s左右到现在的几秒,实测数据如表1所示。

5 结论
本文在论述HBase集群与Zookeeper集群的交互机制以及RegionServer发生故障后的异常处理恢复机制的基础上,提出了提高恢复效率、降低业务中断时间的改进方案。该方案对于RegionServer进程的异常终止和崩溃有很好的处理效果,但是对于RegionServer断电等物理事件导致的异常则无效,这种情况只能依靠Session Timeout后的处理流程。批量恢复的处理对所有的恢复过程都是有效的,虽然其提供的改进空间较小。总体说来,本文提出的RegionServer崩溃后的改进措施在通常情况下能够较好地改进现有HBase集群的性能,缩短故障恢复时间,提高故障恢复效率,从而能有效缩短业务中断时间。
参考文献
[1] Apache. HBase-0.96.2 release notes[EB/OL]. [2013-07-21].http://qnalist.com/q/hbase-user.
[2] Cloudera. HBase-0.94.2-cdh4.2.0 reference guidep[EB/OL].[2013-07-28].http://newitfarmer.com/category/big_data/cloudera-big_data.
[3] 陆嘉恒. Hadoop实战(第二版)[M]. 北京:机械工业出版社,2012.
[4] GEORGE L. HBase: the definitive guide[M]. Sebastopol: O′Reilly Media, 2011.
[5] Apache. ZooKeeper-3.4.5 release notes[EB/OL]. [2012-11-19].http://zookeeper.apache.org/doc/r.3.4.5.