最近一直在忙着搞Ceph存储的优化和测试,看了各种资料,但是好像没有一篇文章把其中的方法论交代清楚,所以呢想在这里进行一下总结,很多内容并不是我原创,只是做一个总结。如果其中有任何的问题,欢迎各位喷我,以便我提高。
优化方法论
做任何事情还是要有个方法论的,“授人以鱼不如授人以渔”的道理吧,方法通了,所有的问题就有了解决的途径。通过对公开资料的分析进行总结,对分布式存储系统的优化离不开以下几点:
1. 硬件层面
- 硬件规划
- SSD选择
- BIOS设置
2. 软件层面
- Linux OS
- Ceph Configurations
- PG Number调整
- CRUSH Map
- 其他因素
硬件优化
1. 硬件规划
- Processor
ceph-osd进程在运行过程中会消耗CPU资源,所以一般会为每一个ceph-osd进程绑定一个CPU核上。当然如果你使用EC方式,可能需要更多的CPU资源。
ceph-mon进程并不十分消耗CPU资源,所以不必为ceph-mon进程预留过多的CPU资源。
ceph-msd也是非常消耗CPU资源的,所以需要提供更多的CPU资源。
- 内存
ceph-mon和ceph-mds需要2G内存,每个ceph-osd进程需要1G内存,当然2G更好。
- 网络规划
万兆网络现在基本上是跑Ceph必备的,网络规划上,也尽量考虑分离cilent和cluster网络。
2. SSD选择
硬件的选择也直接决定了Ceph集群的性能,从成本考虑,一般选择SATA SSD作为Journal,Intel® SSD DC S3500 Series基本是目前看到的方案中的***。400G的规格4K随机写可以达到11000 IOPS。如果在预算足够的情况下,推荐使用PCIE SSD,性能会得到进一步提升,但是由于Journal在向数据盘写入数据时Block后续请求,所以Journal的加入并未呈现出想象中的性能提升,但是的确会对Latency有很大的改善。
如何确定你的SSD是否适合作为SSD Journal,可以参考SÉBASTIEN HAN的Ceph: How to Test if Your SSD Is Suitable as a Journal Device?,这里面他也列出了常见的SSD的测试结果,从结果来看SATA SSD中,Intel S3500性能表现***。
3. BIOS设置
- Hyper-Threading(HT)
基本做云平台的,VT和HT打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。
- 关闭节能
关闭节能后,对性能还是有所提升的,所以坚决调整成性能型(Performance)。当然也可以在操作系统级别进行调整,详细的调整过程请参考链接,但是不知道是不是由于BIOS已经调整的缘故,所以在CentOS 6.6上并没有发现相关的设置。
for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done
- 1.
- NUMA
简单来说,NUMA思路就是将内存和CPU分割为多个区域,每个区域叫做NODE,然后将NODE高速互联。 node内cpu与内存访问速度快于访问其他node的内存,NUMA可能会在某些情况下影响ceph-osd。解决的方案,一种是通过BIOS关闭NUMA,另外一种就是通过cgroup将ceph-osd进程与某一个CPU Core以及同一NODE下的内存进行绑定。但是第二种看起来更麻烦,所以一般部署的时候可以在系统层面关闭NUMA。CentOS系统下,通过修改 /etc/grub.conf文件,添加numa=off来关闭NUMA。
kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
- 1.
#p#
软件优化
1. Linux OS
- Kernel pid max
echo 4194303 > /proc/sys/kernel/pid_max
- 1.
- Jumbo frames, 交换机端需要支持该功能,系统网卡设置才有效果
ifconfig eth0 mtu 9000
- 1.
***设置
echo "MTU=9000" | tee -a /etc/sysconfig/network-script/ifcfg-eth0
/etc/init.d/networking restart
- 1.
- 2.
read_ahead, 通过数据预读并且记载到随机访问内存方式提高磁盘读操作,查看默认值
cat /sys/block/sda/queue/read_ahead_kb
- 1.
根据一些Ceph的公开分享,8192是比较理想的值
echo "8192" > /sys/block/sda/queue/read_ahead_kb
- 1.
- swappiness, 主要控制系统对swap的使用,这个参数的调整***见于UnitedStack公开的文档中,猜测调整的原因主要是使用swap会影响系统的性能。
echo "vm.swappiness = 0" | tee -a /etc/sysctl.conf
- 1.
- I/O Scheduler,关于I/O Scheculder的调整网上已经有很多资料,这里不再赘述,简单说SSD要用noop,SATA/SAS使用deadline。
echo "deadline" > /sys/block/sd[x]/queue/scheduler
echo "noop" > /sys/block/sd[x]/queue/scheduler
- 1.
- 2.
- cgroup
这方面的文章好像比较少,昨天在和Ceph社区交流过程中,Jan Schermer说准备把生产环境中的一些脚本贡献出来,但是暂时还没有,他同时也列举了一些使用cgroup进行隔离的原因。
- 不在process和thread在不同的core上移动(更好的缓存利用)
- 减少NUMA的影响
- 网络和存储控制器影响 - 较小
- 通过限制cpuset来限制Linux调度域(不确定是不是重要但是是***实践)
- 如果开启了HT,可能会造成OSD在thread1上,KVM在thread2上,并且是同一个core。Core的延迟和性能取决于其他一个线程做什么。
这一点具体实现待补充!!!
2. Ceph Configurations
[global]

- 查看系统***文件打开数可以使用命令
cat /proc/sys/fs/file-max
- 1.
[osd] - filestore

- 调整omap的原因主要是EXT4文件系统默认仅有4K
- filestore queue相关的参数对于性能影响很小,参数调整不会对性能优化有本质上提升
[osd] - journal

- Ceph OSD Daemon stops writes and synchronizes the journal with the filesystem, allowing Ceph OSD Daemons to trim operations from the journal and reuse the space.
- 上面这段话的意思就是,Ceph OSD进程在往数据盘上刷数据的过程中,是停止写操作的。
[osd] - osd config tuning
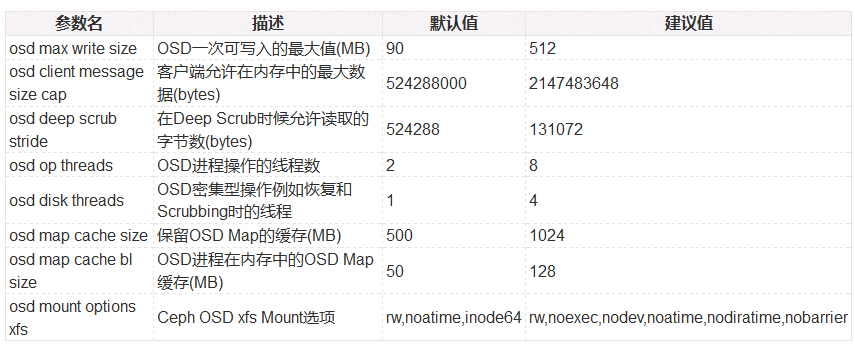
- 增加osd op threads和disk threads会带来额外的CPU开销
[osd] - recovery tuning

[osd] - client tuning

关闭Debug
#p#
3. PG Number
PG和PGP数量一定要根据OSD的数量进行调整,计算公式如下,但是***算出的结果一定要接近或者等于一个2的指数。
Total PGs = (Total_number_of_OSD * 100) / max_replication_count
- 1.
例如15个OSD,副本数为3的情况下,根据公式计算的结果应该为500,最接近512,所以需要设定该pool(volumes)的pg_num和pgp_num都为512.
ceph osd pool set volumes pg_num 512
ceph osd pool set volumes pgp_num 512
- 1.
- 2.
4. CRUSH Map
CRUSH是一个非常灵活的方式,CRUSH MAP的调整取决于部署的具体环境,这个可能需要根据具体情况进行分析,这里面就不再赘述了。
5. 其他因素的影响
在今年的(2015年)的Ceph Day上,海云捷迅在调优过程中分享过一个由于在集群中存在一个性能不好的磁盘,导致整个集群性能下降的case。通过osd perf可以提供磁盘latency的状况,同时在运维过程中也可以作为监控的一个重要指标,很明显在下面的例子中,OSD 8的磁盘延时较长,所以需要考虑将该OSD剔除出集群:
ceph osd perf
- 1.
osd fs_commit_latency(ms) fs_apply_latency(ms)
osd fs_commit_latency(ms) fs_apply_latency(ms)
0 14 17
1 14 16
2 10 11
3 4 5
4 13 15
5 17 20
6 15 18
7 14 16
8 299 329
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
ceph.conf
[global]
fsid = 059f27e8-a23f-4587-9033-3e3679d03b31
mon_host = 10.10.20.102, 10.10.20.101, 10.10.20.100
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd pool default size = 3
osd pool default min size = 1
public network = 10.10.20.0/24
cluster network = 10.10.20.0/24
max open files = 131072
[mon]
mon data = /var/lib/ceph/mon/ceph-$id
[osd]
osd data = /var/lib/ceph/osd/ceph-$id
osd journal size = 20000
osd mkfs type = xfs
osd mkfs options xfs = -f
filestore xattr use omap = true
filestore min sync interval = 10
filestore max sync interval = 15
filestore queue max ops = 25000
filestore queue max bytes = 10485760
filestore queue committing max ops = 5000
filestore queue committing max bytes = 10485760000
journal max write bytes = 1073714824
journal max write entries = 10000
journal queue max ops = 50000
journal queue max bytes = 10485760000
osd max write size = 512
osd client message size cap = 2147483648
osd deep scrub stride = 131072
osd op threads = 8
osd disk threads = 4
osd map cache size = 1024
osd map cache bl size = 128
osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier"
osd recovery op priority = 4
osd recovery max active = 10
osd max backfills = 4
[client]
rbd cache = true
rbd cache size = 268435456
rbd cache max dirty = 134217728
rbd cache max dirty age = 5
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
总结
优化是一个长期迭代的过程,所有的方法都是别人的,只有在实践过程中才能发现自己的,本篇文章仅仅是一个开始,欢迎各位积极补充,共同完成一篇具有指导性的文章。
原文链接:http://xiaoquqi.github.io/blog/2015/06/28/ceph-performance-optimization-summary/