前言
拖了5天终于看完了两篇论文,对相关数据分析平台搭建技术也有了进一步的了解。对自己这几天的笔记做了一个整理,既是为了方便自己以后查看,也是为以后的实际平台搭建建立依据。其实感觉还是挺苦逼的,这大过年的亲戚都坐在旁边包饺子,而我……还在为自己的拖延症买单。
本笔记主要记录以下两个方面:
- Hadoop MapReduce与Hive技术研究
- 数据分析平台框架设计与环境配置
Google三大核心技术:GFS[1]、Mapreduce、Bigtable[2]
[1]. Google文件系统(Google File System,缩写为GFS或GoogleFS)是Google公司为了满足其需求而开发的基于Linux的专有分布式文件系统。
[2]. BigTable是一种压缩的、高性能的、高可扩展性的,基于Google文件系统(Google File System,GFS)的数据存储系统,不是传统的关系型数据库,用于存储大规模结构化数据,适用于云计算。
Hadoop MapReduce与Hive技术研究
一、Hadoop框架工作机制
Hadoop框架定义:Hadoop分布式文件系统(HDFS)和Mapreduce实现。并行程序设计方法中最重要的一种结构就是主从结构,而Hadoop则属于该架构。
HDFS架构:HDFS采用Master/Slave架构,也是主从模式的结构。一个HDFS集群由一个NameNode节点和一组DataNode节点(通常也作为计算节点,若干个)组成。
NameNode定义:NameNode是一个中心服务器,负责管理文件系统的名字空间(NameSpace)、数据节点和数据块之间的映射关系以及客户 端对文件的访问。它会将包含文件信息、文件相对应的文件块信息以及文件块在DataNode的信息等文件系统的缘数据存储在内存中,是整个集群的主节点。
DataNode定义:集群系统中,一个节点上通常只运行一个DataNode,负责管理他所在节点上的数据存储,并负责处理文件系统客户端的读写请求, 在NameNode的统一调度下进行数据块的创建、删除和复制。集群中的数掘节点管理存储的数据,会将块的元数据存储在本地,并且会将全部存在的块信息周 期性的发给NameNode。
在节点中操纵数据:
当要向集群中的某一节点写入数据:NameNode负责分配数据块,客户端把数据写入到对应节点中;
当要从集群中的某一节点读取数据:客户端在找到这一节点之前需要先获取到数据块的映射关系(关系由Namenode提供),之后从节点上读取数据。
为了应对HDFS大量节点构成的特殊分布式数据结构的特征,所以HDFS架构最重要的就是要有错误故障检测以及故陣的快速恢复机制,这是通过数据节点和名字节点之间的一种称为心跳的机制来实现的,他能够使HDFS系统任意增删节点。
同时,分布式系统的采用和MapReduce模型的实现使得Hadoop框架具有高容错性以及对数据读写的高吞吐率,能自动处理失败节点。
HDFS两大特性:
高容错系统:HDFS增加了数据的冗余性。即每一个文件的所有数掘块都将会有副本。HDFS釆用一种机架感知的策略,这种策略需在经验积累的基础上调优。 经过机架感知,NameNode可以知道DataNode所在位置的机架。这样的策略可使副本均匀分布在集群中的节点上,对于节点故障时的负载均衡有利。
高存取数据性能:通过客户端临时缓存在本地的数据减少对于网络带宽的依赖程度;读取副本时遵循就近原则;采用流水线复制技术提高性能(第一个接收数据的数 据节点在把数据写到本地后会依次接着把数据传到存有数据副本的节点,直到所有的存对副本的节点,在这个过程中每个节点都是一边接受一边传送,减少了备份的 时间);
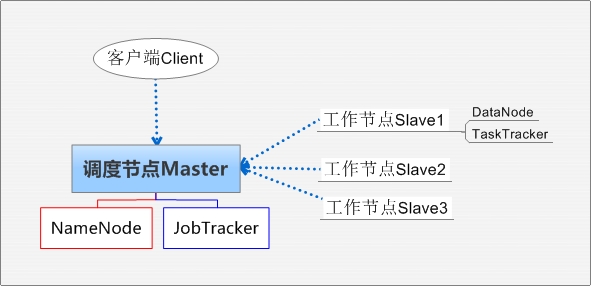
Hadoop集群系统架构示意图
Client:获取分布式文件系统文件的应用程序。
Master:负责NameNode和JobTracker的工作,其中JobTracker负责应用程序的启动、跟踪和调度各个Slave任务的执行,各个Tracker中TaskTracker管理本地数据处理与结果,并与JobTracker通信。
#p#
二、MapReduce(映射-归并算法)分布式并行计算编程模型
该主从框架结构可以把一个作业任务分解成若干个细粒度的子任务,根据节点空闲状况来调度和快速的处理子任务,最后通过一定的规则合并生成最终的结 果。有一个主节点和若干个从节点,其中主节点的作用是负责任务分配和资源的调度;而从节点则主要是负责作业的执行处理。基于此框架的程序能在通配置的机器 上实现并行化的处理。
MapReduce借用函数式编程的思想,通过把海量数据集的常见操作抽象为Map(映射过程)和Reduce(聚集过程)两种集合操作,而不用过多考虑分布式相关的操作。
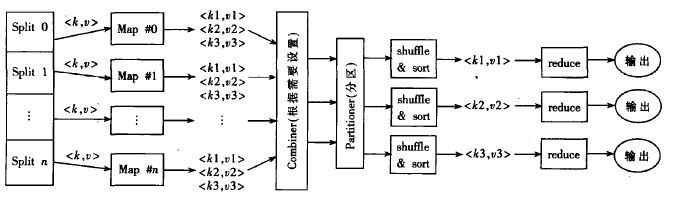
MapReduce任务计算流程示意图
MR任务的基本计算流程:
1、对输入数据进行数据块划分,便于每个map处理一个分片作业;
2、RecordReader对数据块进行生成键值;
3、Map操作:Partitioner类以指定的方式将数据区分的写入文件,此时集群中多个节点可以同时进行map作业操作处理;
4、Reduce过程:组合、排序、聚集数据,最后结果写入Hadoop的分布式文件系统HDFS管理的输出文件中。
对MapReduce模型使用的思考:
MapReduce是一个可扩展的架构,通过切分块数据实现集群上各个节点的并发计算。理论上随着集群节点节点数量的增加,它的运行速度会线性上 升,但在实际应用时要考虑到以下的一些限制因素。数据不可能无限的切分,如果每份数据太小,那么它的开销就会相对变大;集群节点数目增多,节点之间的通信 开销也会随之增大,而且网络也会有Oversubscribe的问题(也就是机架间的网络带宽远远小于每个机架内部的总带宽),所以通常情况下如果集群的 规模在百个节点以上,MapReduce的速度可以和节点的数目成正比;超过这个规模,虽然它的运行速度可以继续提高,但不再以线性增长。
三、并行随机数发生器算法的MapReduce实现
算法实现流程基本步骤如下:
1、由MapReduce框架为每个映射任务分配计算负载,即确定每个映射任务要生成的随机数个数(m),m=nRandom(总随机个数)/(nMaps(映射任务数));
2、集群中各计算节点执行Map任务,根据负载分配计算得出m个随机数并存入一个数组,产生一组中间结果;
3、MapReduce框架进行分区操作。Partitioner类使用Hash函数按key(或者一个key子集)进行分区操作,分区的数目等 同于一个作业的Reduce任务的数目。即由Partitioner控制将中间过程的key发送给m个Reduce任务中的哪一个来进行Reduce操 作。
4、各计算节点启动Reduce任务,将有相同key的随机数值进行聚集操作,并将最终结果写入文件进行输出。
四、Hive架构
什么是Hive?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换 为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和 分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。同时,这个语言也允 许熟悉 MapReduce 开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
Hive架构
用户接口(User Interface) Hive主要有三个用户接口,分别是命令行接(CLI),web用户接口(WUI)和客户端(Client)。其中CLI是最常用的,Client是用户 连接至Hive Server的客户端,要指出运行Hive服务器的节点,并在此节点之上动Hive服务器。对于WUI来说采用使用浏览器方式访问Hive。
元存储(MetaStore) Hive是把元数掘存储在hadoop文件系统HDFS中,元数据包括数据表的名字,数据表的列、分区及其属性,数掘表的属性,数据所在的目录等,大部分的的查询由MapReduce完成。
其他 HQL语句的语法和语法分析、编译和优化以及查询计划都是通过解释器、优化器和编译器共同完成的,生成的中间数据是存储在hadoop分布式文件系统中,并在某个时间调用MapReduce程序来执行。
Hive优点
针对海量数据的高性能查询和分析系统:除天生的高性能查询功能外,Hive针对HiveQL到MapReduce的翻译进行了大量的优化,从而保证了生成的MapReduce任务是高效的。实际应用中,Hive支持处理TB甚至PB级的数据。
类SQL的查询语言HiveQL:熟悉SQL的用户基本不需要培训就可以非常容易的使用Hive进行很复杂的查询。
HiveQL极大可扩展性:除了HiveQL自身提供的能力,用户还可以自定义其使用的数据类型、也可以用任何语言自定义mapper和reducer脚本,还可以自定义函数(普通函数、聚集函数)等,以此实现复杂查询的目的。
高扩展性(Scalability)和容错性Hive没有执行的机制,用户的查询执行过程都是由分布式计算框架MapReduce完成的,因此Hive相应具有MapReduce的高度可扩展和高容错特点。
与Hadoop其他产品完全兼容:Hive自身并不存储用户数据,而是通过接口访问用户数据。这就使得Hive支持各种数据源和数据格式。用户可以实现用 自己的驱动来增加新的数据源和数据格式。一种理想的应用模型是将数据存储在HBase中实现实时访问,而用Hive对HBase中的数据进行批量分析。
五、Hbase
Hbase是使用java的google bigtable的开源实现,它是建立在分布式文件系统之上的分布式数据系统,属于面向列的数据库。
HBase主要由三个部分组成,分别是Hmaster、HRegionServer和HbaseClient。
1、HMaster是HBase中的主服务器,主要负责对表和Region的管理,包括管理对表的操作、以及Region的负载均衡以及灾难处理等。
2、HRegions是由HBase中的数据表逐渐分裂而成的,因为在HBase中存在着一系列往往比较大的表,当一张表的记录数不断的增加达到 一定的容量上限时便会逐渐分裂成Regions,而这些Regions会比较均匀的分布在集群中的,并且—个Region下还会还会有一定数量的列族。
3、HBaseClient是指HBase客户端的API,通信都采用RPC机制,用户程序通过调用客户端的API来和HBase的后台中的 HMaster和HRegion进行交互的。Client主要进行两类的操作:管理操作(和HMaster之问进行通信)和数据读写类操作(和 HRegion进行通信)。
#p#
数据分析平台框架设计与环境配置
一、平台总体架构和模块设计
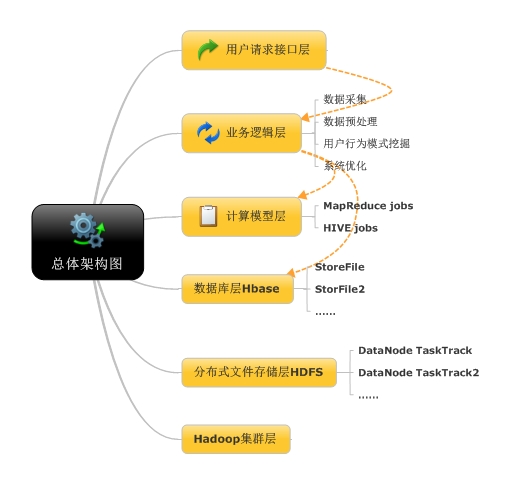
数据分析平台设计总计架构图
注:从上至下为数据流方向,,黄色虚线指向为软件流程方向。总共系统包括七个层面,除图中六个模块均处于监控管理模块下,其为分布式系统监控管理层。
二、平台数据采集预处理模块详细设计
数据采集模块:根据不同的信息来源,需要采取不同的技术。
数据预处理模块:清洗、规约等阶段。
三、存储模块详细设计
HBase调用文件系统接口来获取日志数据的物理存储位置,MapReduce程序调用文件接口来将处理后的海量数据存储在HDFS中。
1、外部调用:此部分由MapReduce程序、HBase和web接口三部分组成。这三部分都可以通过调用HDFS接口,在底层文件系统上存储数据。
2、HDFS接口:文件系统底层的接口是底层HDFS系统呈现的接口,所有对文件系统的操作都要通过此接口来完成。
3、底层文件系统:位于最底层的文件系统足整个系统我正的存储平台,所有的数掘倍总都足存储在文件系统中的,外部调用模块根据需要调用HDFS接口来对文件系统进行操作。
四、平台监控模块详细设计
集群管理器设计:
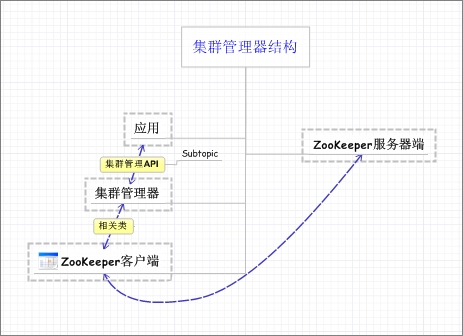
集群管理器设计
配置管理器设计:
功能实现:读取、修改、创建共享配置。
五、平台监控模块详细设计
Hadoop集群安装部署:
1、在集群的每个节点上安装hadoop并编辑每个节点的hosts文件,分别将主节点和各从节点的主机名称与IP地址的映射关系添加到hosts文件之中;
2、配置SSH服务,并在master上通过运行ssh-keygen-trsa命令用于生成一个无口令RSA密钥对,然后再将此公朗复制到每个slave节点的.ssh文件夹下的authorized_keys文件里;
3、修改Hadoop的一些重要的配置文件,在安装hadoop的目录下的conf目录下对其中的coresite.xml、mapredsite.xml和HDFS_site.xmI等几项配置信息进行修改。
Hive安装配置:由于Hive安装过于简单,故这里略去。
参考文献
《基于hadoop的海量搜索日志分析平台的设计和实现》,赵龙,大连,大连理工大学,2013.6
《基于HadoopMapReduce模型的应用研究》,谢桂兰,四川,《软件天地》杂志,2010.01
原文链接:http://hijiangtao.github.io/2014/01/30/hadoopmapreducedesign/