流畅地使用命令行是一个常被忽略的技能,或被认为是神秘的奥义。但是,它会以明显而微妙的方式改善你作为工程师的灵活度和生产力。这是我在 Linux 上工作时发现的有用的命令行使用小窍门和笔记的精粹。有些小窍门是很基础的,而有些是相当地特别、复杂、或者晦涩难懂。这篇文章不长,但是如果你可以使用 并记得这里的所有内容,那么你就懂得很多了。
其中大部分最初出现在Quora上,但是考虑到兴趣所在,似乎更应该放到 Github 上,这里的人比我更能提出改进建议。如果你看到一个错误,或者更好的某种东西,请提交问题或 PR!(当然,提交前请看看必读小节和已有的 PR/Issue。)
必读
范围:
-
本文是针对初学者和专业人员的,选题目标是覆盖面广(全都很重要)、有针对性(大多数情况下都给出具体实例)而简洁(避免不必要内容以及你能在其它地方轻松找到的离题的内容)。每个小窍门在某种情形下都很必需的,或者能比替代品大大节省时间。
-
这是为 Linux 写的。绝大部分条目都可以同样应用到 MacOS(或者甚至 Cygwin)。
-
主要针对交互式 Bash,尽管大多数小窍门也可以应用到其它 shell,以及常规 Bash 脚本。
-
包括了“标准的”UNIX 命令以及那些需要安装的软件包(它们很重要,值得安装)。
注意:
-
为了能在一篇文章内展示尽量多的东西,一些具体的信息会被放到引用页里。你可以使用 Google 来获得进一步的内容。(如果需要的话,)你可以使用 apt-get/yum/dnf/pacman/pip/brew 来安装这些新的程序。
-
使用 Explainshell 来获取命令、参数、管道等内容的解释。
基础
-
学习基本 Bash 技能。实际上,键入man bash,然后至少浏览一遍所有内容;它很容易理解,没那么长。其它 shell 也不错,但是 Bash 很强大,而且到处都可以找到(如果在你自己的笔记本上只学习 zsh、fish 之类,会在很多情形下受到限制,比如使用现存的服务器时)。
-
至少学好一种基于文本的编辑器。理想的一个是 Vim(vi),因为在终端中编辑时随时都能找到它(即使大多数时候你在使用 Emacs、一个大型的 IDE、或一个现代的时髦编辑器)。
-
学习怎样使用 man 来阅读文档(好奇的话,用 man man 来列出分区号,比如 1 是常规命令,5 是文件描述,8 用于管理员)。用 apropos 找到帮助页。了解哪些命令不是可执行程序,而是 Bash 内置的,你可以用 help 和 help -d 得到帮助。
-
学习使用 > 和 < 来进行输出和输入重定向,以及使用 | 来管道重定向,学习关于 stdout 和 stderr 的东西。
-
学习 *(也许还有 ? 和 {…} )文件通配扩展和应用,以及双引号 ” 和单引号 ‘ 之间的区别。(更多内容请参看下面关于变量扩展部分)。
-
熟悉 Bash 作业管理:&, ctrl-z, ctrl-c, jobs, fg, bg, kill 等等。
-
掌握ssh,以及通过 ssh-agent,ssh-add 等进行无密码验证的基础技能。
-
基本的文件管理:ls 和 ls -l(特别是,知道ls -l各个列的意义),less, head, tail 和 tail -f(或者更好的less +F),ln 和 ln -s(知道硬链接和软链接的区别,以及硬链接相对于软链接的优势),chown,chmod,du(用于查看磁盘使用率的快速摘要:du -sk *)。文件系统管理:df, mount,fdisk,mkfs,lsblk。
-
基本的网络管理: ip 或 ifconfig,dig。
-
熟知正则表达式,以及各种使用grep/egrep的选项。-i,-o,-A 和 -B 选项值得掌握。
-
学会使用 apt-get,yum ,dnf 或 pacman(这取决于你的发行版)来查找并安装软件包。确保你可以用 pip 来安装基于 Python 的命令行工具(下面的一些东西可以很容易地通过 pip 安装)。
日常使用
-
在Bash中,使用 tab 补完参数,使用 ctrl-r 来搜索命令历史。
-
在Bash中,使用 ctrl-w 来删除最后的单词,使用 ctrl-u 来删除整行,返回行首。使用 alt-b 和 alt-f 来逐词移动,使用 ctrl-k 来清除到行尾的内容,以及使用 ctrl-l 清屏。参见 man readline 来查看 Bash 中所有默认的键盘绑定,有很多。例如,alt-. 可以循环显示先前的参数,而alt- 扩展通配。
-
另外,如果你喜欢 vi 风格的键盘绑定,可以使用 set -o vi。
-
要查看最近用过的命令,请使用 history 。 有许多缩写形式,比如 !$(上次的参数)和!!(上次的命令),虽然使用 ctrl-r 和 alt-. 更容易些。
-
返回先前的工作目录: cd -
-
如果你命令输入到一半,但是改变主意了,可以敲 alt-# 来添加一个 # 到开头,然后将该命令作为注释输入(或者使用快捷键 ctrl-a, #,enter 输入)。然后,你可以在后面通过命令历史来回到该命令。
-
使用 xargs(或 parallel),它很强大。注意,你可以控制每行(-L)执行多少个项目,以及并行执行(-P)。如果你不确定它是否会做正确的事情,可以首先使用 xargs echo。同时,使用 -I{} 也很方便。样例:
find . -name '*.py' | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname -
pstree -p 对于显示进程树很有帮助。
-
使用 pgrep 和 pkill 来按名称查找进程或给指定名称的进程发送信号(-f 很有帮助)。
-
掌握各种可以发送给进程的信号。例如,要挂起进程,可以使用 kill -STOP [pid]。完整的列表可以查阅 man 7 signal。
-
如果你想要一个后台进程一直保持运行,使用 nohup 或 disown。
-
通过 netstat -lntp 或 ss -plat 检查哪些进程在监听(用于 TCP,对 UDP 使用 -u 替代 -t)。
-
lsof来查看打开的套接字和文件。
-
在 Bash 脚本中,使用 set -x 调试脚本输出。尽可能使用严格模式。使用 set -e 在遇到错误时退出。也可以使用 set -o pipefail,对错误进行严格处理(虽然该话题有点微妙)。对于更复杂的脚本,也可以使用 trap。
-
在 Bash 脚本中,子 shell(写在括号中的)是组合命令的便利的方式。一个常见的例子是临时移动到一个不同的工作目录,如:
# 在当前目录做些事
(cd /some/other/dir; other-command)
# 继续回到原目录 -
注意,在 Bash 中有大量的各种各样的变量扩展。检查一个变量是否存在:${name:?error message}。例如,如果一个Bash脚本要求一个单一参数,只需写 input_file=${1:?usage: $0 input_file}。算术扩展:i=$(( (i + 1) % 5 ))。序列: {1..10}。修剪字符串:${var%suffix} 和 ${var#prefix}。例如,if var=foo.pdf ,那么 echo ${var%.pdf}.txt 会输出 foo.txt。
-
命令的输出可以通过 <(some command) 作为一个文件来处理。例如,将本地的 /etc/hosts 和远程的比较:
diff /etc/hosts <(ssh somehost cat /etc/hosts)
-
了解 Bash 中的“嵌入文档”,就像在 cat <<EOF … 中。
-
在 Bash 中,通过:some-command >logfile 2>&1 同时重定向标准输出和标准错误。通常,要确保某个命令不再为标准输入打开文件句柄,而是将它捆绑到你所在的终端,添加 </dev/null 是个不错的做法。
-
man ascii 可以得到一个不错的ASCII表,带有十六进制和十进制值两种格式。对于常规编码信息,man unicode,man utf-8 和 man latin1 将很有帮助。
-
使用 screen 或 tmux 来复用屏幕,这对于远程 ssh 会话尤为有用,使用它们来分离并重连到会话。另一个只用于保持会话的最小可选方案是 dtach。
-
在 ssh 中,知道如何使用 -L 或 -D(偶尔也用-R)来打开端口通道是很有用的,如从一台远程服务器访问网站时。
-
为你的 ssh 配置进行优化很有用;例如,这个 ~/.ssh/config 包含了可以避免在特定网络环境中连接被断掉的情况的设置、使用压缩(这对于通过低带宽连接使用 scp 很有用),以及使用一个本地控制文件来开启到同一台服务器的多通道:
TCPKeepAlive=yes
ServerAliveInterval=15
ServerAliveCountMax=6
Compression=yes
ControlMaster auto
ControlPath /tmp/%r@%h:%p
ControlPersist yes -
其它一些与 ssh 相关的选项对会影响到安全,请小心开启,如各个子网或主机,或者在信任的网络中:StrictHostKeyChecking=no, ForwardAgent=yes
-
要获得八进制格式的文件的权限,这对于系统配置很有用而用 ls 又没法查看,而且也很容易搞得一团糟,可以使用像这样的东西:
stat -c '%A %a %n' /etc/timezone
-
对于从另一个命令的输出结果中交互选择值,可以使用percol。
-
对于基于另一个命令(如git)输出的文件交互,可以使用fpp (路径选择器)。
-
要为当前目录(及子目录)中的所有文件构建一个简单的 Web 服务器,让网络中的任何人都可以获取,可以使用: python -m SimpleHTTPServer 7777 (使用端口 7777 和 Python 2)。
#p#
处理文件和数据
-
要在当前目录中按名称定位文件,find . -iname ‘*something*’(或者相类似的)。要按名称查找任何地方的文件,使用 locate something(但请记住,updatedb 可能还没有索引最近创建的文件)。
-
对于源代码或数据文件进行的常规搜索(要比 grep -r 更高级),使用 ag。
-
要将 HTML 转成文本:lynx -dump -stdin。
-
对于 Markdown、HTML,以及各种类型的文档转换,可以试试 pandoc。
-
如果你必须处理 XML,xmlstarlet 虽然有点老旧,但是很好用。
-
对于 JSON,使用jq。
-
对于 Excel 或 CSV 文件,csvkit 提供了 in2csv,csvcut,csvjoin,csvgrep 等工具。
-
对于亚马逊 S3 ,s3cmd 会很方便,而 s4cmd 则更快速。亚马逊的 aws 则是其它 AWS 相关任务的必备。
-
掌握 sort 和 uniq,包括 uniq 的 -u 和 -d 选项——参见下面的单行程序。
-
掌握 cut,paste 和 join,它们用于处理文本文件。很多人会使用 cut,但常常忘了 join。
-
了解 tee,它会将 stdin 同时复制到一个文件和 stdout,如 ls -al | tee file.txt。
-
知道 locale 会以微妙的方式对命令行工具产生大量的影响,包括排序的顺序(整理)以及性能。大多数安装好的 Linux 会设置 LANG 或其它 locale 环境变量为本地设置,比如像 US English。但是,你要明白,如果改变了本地环境,那么排序也将改变。而且 i18n 过程会让排序或其它命令的运行慢好多倍。在某些情形中(如像下面那样的设置操作或唯一性操作),你可以安全地整个忽略缓慢的 i18n 过程,然后使用传统的基于字节的排序顺序 export LC_ALL=C。
-
了解基本的改动数据的 awk 和 sed 技能。例如,计算某个文本文件第三列所有数字的和:awk ‘{ x += $3 } END { print x }’。这可能比 Python 的同等操作要快3倍,而且要短3倍。
-
在一个或多个文件中,替换所有出现在特定地方的某个字符串:
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
-
要立即根据某个模式对大量文件重命名,使用 rename。对于复杂的重命名,repren 可以帮助你达成。
# 恢复备份文件 foo.bak -> foo:
rename 's//.bak$//' *.bak
# 完整的文件名、目录名 foo -> bar:
repren --full --preserve-case --from foo --to bar . -
使用 shuf 来从某个文件中打乱或随机选择行。
-
了解 sort 的选项。知道这些键是怎么工作的(-t和-k)。特别是,注意你需要写-k1,1来只通过第一个字段排序;-k1意味着根据整行排序。
-
稳定排序(sort -s)会很有用。例如,要首先按字段2排序,然后再按字段1排序,你可以使用 sort -k1,1 | sort -s -k2,2
-
如果你曾经需要在 Bash 命令行中写一个水平制表符(如,用于 -t 参数的排序),按ctrl-v [Tab],或者写$’/t’(后面的更好,因为你可以复制/粘贴)。
-
对源代码进行补丁的标准工具是 diff 和 patch。 用 diffstat 来统计 diff 情况。注意 diff -r 可以用于整个目录,所以可以用 diff -r tree1 tree2 | diffstat 来统计(两个目录的)差异。
-
对于二进制文件,使用 hd 进行简单十六进制转储,以及 bvi 用于二进制编辑。
-
还是用于二进制文件,strings(加上 grep 等)可以让你找出一点文本。
-
对于二进制文件的差异(delta 压缩),可以使用 xdelta3。
-
要转换文本编码,试试 iconv 吧,或者对于更高级的用途使用 uconv;它支持一些高级的 Unicode 的东西。例如,这个命令可以转换为小写并移除所有重音符号(通过扩展和丢弃):
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
-
要将文件分割成几个部分,来看看 split(按大小分割)和 csplit(按格式分割)吧。
-
使用 zless,zmore,zcat 和 zgrep 来操作压缩文件。
系统调试
-
对于 Web 调试,curl 和 curl -I 很方便灵活,或者也可以使用它们的同行 wget,或者更现代的 httpie。
-
要了解磁盘、CPU、网络的状态,使用 iostat,netstat,top(或更好的 htop)和(特别是)dstat。它们对于快速获知系统中发生的状况很好用。
-
对于更深层次的系统总览,可以使用 glances。它会在一个终端窗口中为你呈现几个系统层次的统计数据,对于快速检查各个子系统很有帮助。
-
要了解内存状态,可以运行 free 和 vmstat,看懂它们的输出结果吧。特别是,要知道“cached”值是Linux内核为文件缓存所占有的内存,因此,要有效地统计“free”值。
-
Java 系统调试是一件截然不同的事,但是对于 Oracle 系统以及其它一些 JVM 而言,不过是一个简单的小把戏,你可以运行 kill -3 <pid>,然后一个完整的堆栈追踪和内存堆的摘要(包括常规的垃圾收集细节,这很有用)将被转储到stderr/logs。
-
使用 mtr 作路由追踪更好,可以识别网络问题。
-
对于查看磁盘满载的原因,ncdu 会比常规命令如 du -sh * 更节省时间。
-
要查找占用带宽的套接字和进程,试试 iftop 或 nethogs 吧。
-
(Apache附带的)ab工具对于临时应急检查网络服务器性能很有帮助。对于更复杂的负载测试,可以试试 siege。
-
对于更仔细的网络调试,可以用 wireshark,tshark 或 ngrep。
-
掌握 strace 和 ltrace。如果某个程序失败、挂起或崩溃,而你又不知道原因,或者如果你想要获得性能的大概信息,这些工具会很有帮助。注意,分析选项(-c)和使用 -p 关联运行进程。
-
掌握 ldd 来查看共享库等。
-
知道如何使用 gdb 来连接到一个运行着的进程并获取其堆栈追踪信息。
-
使用 /proc。当调试当前的问题时,它有时候出奇地有帮助。样例:/proc/cpuinfo,/proc/xxx/cwd,/proc/xxx/exe,/proc/xxx/fd/,/proc/xxx/smaps。
-
当调试过去某个东西为何出错时,sar 会非常有帮助。它显示了 CPU、内存、网络等的历史统计数据。
-
对于更深层的系统和性能分析,看看 stap (SystemTap),perf) 和 sysdig 吧。
-
确认是正在使用的 Linux 发行版版本(支持大多数发行版):lsb_release -a。
-
每当某个东西的行为异常时(可能是硬件或者驱动器问题),使用dmesg。
#p#
单行程序
这是将命令连成一行的一些样例:
-
有时候通过 sort/uniq 对文本文件做交集、并集和差集运算时,这个例子会相当有帮助。假定 a 和 b 是已经进行了唯一性处理的文本文件。这会很快,而且可以处理任意大小的文件,总计可达数千兆字节。(Sort不受内存限制,不过如果 /tmp 放在一个很小的根分区的话,你可能需要使用 -T 选项。)也可参见上面关于LC_ALL的注解和 -u 选项(参见下面例子更清晰)。
sh cat a b | sort | uniq > c # c 是 a 和 b 的并集
cat a b | sort | uniq -d > c # c 是 a 和 b 的交集
cat a b b | sort | uniq -u > c # c 是 a 减去 b 的差集 -
使用 grep . * 来可视化查看一个目录中的所有文件的所有内容,例如,对于放满配置文件的目录: /sys, /proc, /etc。
-
对某个文本文件的第三列中所有数据进行求和(该例子可能比同等功能的Python要快3倍,而且代码也少于其3倍):
awk '{ x += $3 } END { print x }' myfile
-
如果想要查看某个文件树的大小/日期,该例子就像一个递归ls -l,但是比ls -lR要更容易读懂:
find . -type f -ls
-
只要可以,请使用 xargs 或 parallel。注意,你可以控制每行(-L)执行多少个项目,以及并行执行(-P)。如果你不确定它是否会做正确的事情,可以首先使用 xargs echo。同时,使用 -I{} 也很方便。样例:
find . -name '*.py' | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname -
比如说,你有一个文本文件,如 Web 服务器的日志,在某些行中出现了某个特定的值,如 URL 中出现的 acct_id 参数。如果你想要统计有多少个 acct_id 的请求:
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
-
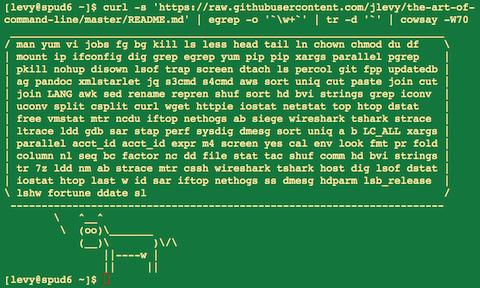
运行该函数来获得来自本文的随机提示(解析Markdown并从中提取某个项目):
function taocl() {
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
pandoc -f markdown -t html |
xmlstarlet fo --html --dropdtd |
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
xmlstarlet unesc | fmt -80
}
晦涩难懂,但却有用
-
expr:实施算术或布林操作,或者求正则表达式的值
-
m4:简单的宏处理器
-
yes:大量打印一个字符串
-
cal:漂亮的日历
-
env:(以特定的环境变量设置)运行一个命令(脚本中很有用)
-
look:查找以某个字符串开头的英文单词(或文件中的行)
-
cut 和 paste 以及 join:数据处理
-
fmt:格式化文本段落
-
pr:格式化文本为页/列
-
fold:文本折行
-
column:格式化文本为列或表
-
expand 和 unexpand:在制表符和空格间转换
-
nl:添加行号
-
seq:打印数字
-
bc:计算器
-
factor:分解质因子
-
gpg:加密并为文件签名
-
toe:terminfo 条目表
-
nc:网络调试和数据传输
-
socat:套接字中继和 tcp 端口转发(类似 netcat)
-
slurm:网络流量可视化
-
dd:在文件或设备间移动数据
-
file:识别文件类型
-
tree:以树形显示目录及子目录;类似 ls,但是是递归的。
-
stat:文件信息
-
tac:逆序打印文件
-
shuf:从文件中随机选择行
-
comm:逐行对比分类排序的文件
-
hd和bvi:转储或编辑二进制文件
-
strings:从二进制文件提取文本
-
tr:字符转译或处理
-
iconv或uconv:文本编码转换
-
split和csplit:分割文件
-
units:单位转换和计算;将每双周(fortnigh)一浪(浪,furlong,长度单位,约201米)转换为每瞬(blink)一缇 (缇,twip,一种和屏幕无关的长度单位)(参见: /usr/share/units/definitions.units)(LCTT 译注:这都是神马单位啊!)
-
7z:高比率文件压缩
-
ldd:动态库信息
-
nm:目标文件的符号
-
ab:Web 服务器基准测试
-
strace:系统调用调试
-
mtr:用于网络调试的更好的路由追踪软件
-
cssh:可视化并发 shell
-
rsync:通过 SSH 同步文件和文件夹
-
wireshark 和 tshark:抓包和网络调试
-
ngrep:从网络层摘取信息
-
host 和 dig:DNS查询
-
lsof:处理文件描述符和套接字信息
-
dstat:有用的系统统计数据
-
glances:高级,多个子系统概览
-
iostat:CPU和磁盘使用率统计
-
htop:top的改进版
-
last:登录历史
-
w:谁登录进来了
-
id:用户/组身份信息
-
sar:历史系统统计数据
-
iftop或nethogs:按套接口或进程的网络使用率
-
ss:套接口统计数据
-
dmesg:启动和系统错误信息
-
hdparm:SATA/ATA 磁盘操作/改善性能
-
lsb_release:Linux 发行版信息
-
lsblk:列出块设备,以树形展示你的磁盘和分区
-
lshw:硬件信息
-
fortune,ddate 和 sl:嗯,好吧,它取决于你是否认为蒸汽机车和 Zippy 引用“有用”
更多资源
-
超棒的shell: 一个shell工具和资源一览表。
-
严格模式 用于写出更佳的shell脚本。
免责声明
除了非常小的任务外,其它都写出了代码供大家阅读。伴随力量而来的是责任。事实是,你能在Bash中做的,并不意味着是你所应该做的!;)