总结、温习,这两点让人成长。而不是你走得有多快!这句话我写了半年了,这篇文章算是此话付诸实践的开端吧。
本文是我对自己这几年所接触的技术的总结,有些技术与工作直接相关,有些则纯属个人兴趣。具体说,本文分为两部分,***部分介绍佳缘用户推荐系统的 发展历史。这部分的介绍很好地反映我们对这个问题的思考和理解过程。这期间我们走了很多弯路,但也正是这些弯路让我们积累了很多婚恋交友推荐里独特的实战 经验。第二部分主要是罗列了一些我个人这几年接触的比较有代表性的技术,这些技术很多偏学术,只对实战感兴趣的同学可以忽略。
佳缘用户推荐系统
天真的算法年:2011-2013
2011年8月我加入世纪佳缘,开始时主要负责佳缘的交友推荐系统优化,后来我这个团队也负责其他的机器学习事情,比如佳缘的网警系统(抓恶意用 户)。刚来时团队加上我只有3个人,做的事基本集中在推荐系统,以及对业务部门新产品的接口支持。当时我自己并没有推荐系统应用于工业界的实际经验,所以 很想当然地就从自己了解的推荐算法开始工作了。
2011年到2013年中这段时间,我们在算法方面主要做了两个方向的尝试。***个是尝试item-based kNN算法。对这个算法的优化尝试体现在以下几个方面:
离线计算效率的优化:从开始的单机计算,到后来的Hadoop分布式计算。
离线计算效果的优化:尝试了不同的相似度计算方法,以及不同的预测产生方式,但效果并不明显。
离线计算改为线上实时计算:离线的工作方式是先在线下计算好推荐结果,然后把结果存入缓存;线上需要推荐结果时 直接从缓存中取即可。显然这种方式对于缓存中没有推荐结果的用户无法产生推荐,而活跃的用户又很容易把缓存中的所有结果都消费完。为了解决这些问题,后来 我们在Dubbo上构建了实时的Java推荐服务。
Item-based kNN算法的尝试最开始是基于***化佳缘用户发信量的业务理解,但后来我们发现这个理解跟业务部门的需求偏差很大。比如给男性展示美女,男性的发信就会暴 涨,但这样就会导致少量的女性收到大部分信,而大部分女性则没信可收。这是业务部门不愿意看到的。虽然我们尝试在item-based kNN基础上做调整来平衡其他的业务指标(如收信人数,看信人数等),但效果不理想。
第二个尝试是学术界的可逆(Reciprocal)推荐算法1,即在考虑用户体验的同时也兼顾item(对佳缘来说也是人)的体验。这个尝试基本是失败的,学术界发明的那些算法基本都有各种前提假设,真用起来都不太靠谱。
虽然到2013年我们团队人数上升到了六七人,但基本在推荐算法上做事的人还是只有两个左右。
#p#
工程年:2014
从2013年底开始我逐渐意识自己对算法的理解过于学术而无法满足业务部门的实际需求。所以从2013年底我开始从业务出发重新梳理推荐算法团队的工作方向。相对于给用户推荐物品的场景,佳缘的在线交友推荐有以下几个特点:
可逆性:佳缘的物品是异性的人,他们也会有感受。所以在推荐时要考虑到双方的感受。
资源独占性:通常一个人在一段时间内也就和一个人谈恋爱。这与电商卖东西是差别很大的,一本相同的书可以卖几十万册都可以,在佳缘这么干就不行。电商可以搞个畅销榜让用户购买最畅销的书,这其实也是很好的推荐。但对于佳缘这一招就很糟糕。
转化链很长,反馈延迟:从展示到发信,再到看信和回信,过程很长,而且看信和回信又会有很长的时间延迟。另外,收益在转化链的末端才能体现。公司的收益在看信后才能体现(佳缘的业务模式是收取用户的看信费用),而用户的收益在回信后才能真正体现。
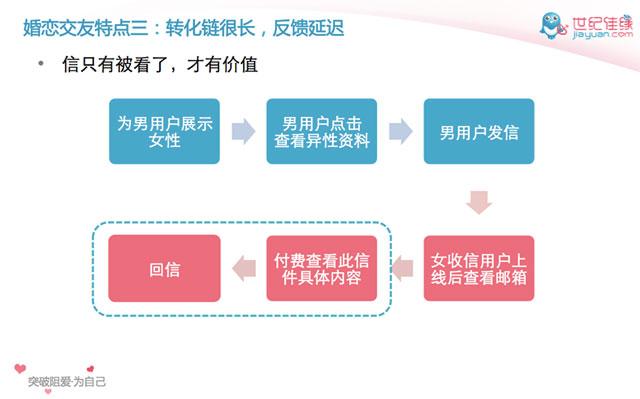
佳缘业务的高复杂性,加上团队在使用算法上经验不够,让我决定把接下来的算法优化方向放在特征工程上,而算法就限制在最简单的逻辑回归(Logistic Regression)。 团队在处理特征的过程中可以积累对数据的处理经验,以及对业务的理解。逻辑回归足够简单,解释性好,也有很好的开源实现。从它开始也可以让团队在算法使用 上积累心得。这是“战术”上的***个选择。我们把上图中每一步转化作为单独的问题分别进行优化,这样逻辑回归就适用于每一步。这是“战术”上的第二个选 择。
上面说的“战术”,其实针对的只是推荐系统里的排序系统。当时我对推荐系统整体的想法是把运营需求和用户需求分开,然后分别对他们进行独立优化。具 体说就是***步以满足运营需求为目标获得候选集,而第二步是根据用户(双方)的喜好对候选集进行排序,系统流程图见下图。这样,在优化用户需求时就不需要 考虑佳缘复杂的业务逻辑,可以极大地简化问题。同样,我们也可以比较独立地优化满足运营需求的候选系统。这可以认为是推荐系统的“战略”方向。
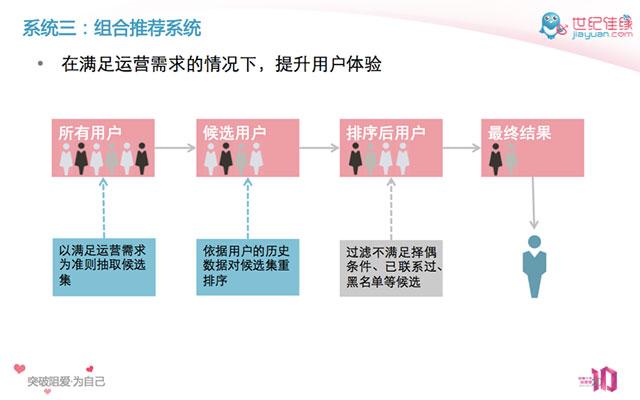
佳缘推荐系统流程图(2014)
2014年无疑是工程年。
#p#
产品年:2015
2014年工程年的效果还是不错的,多个转化模型的分别构建和组合使用,使得业务上的各个指标都有所提升,很多指标的提升幅度都超过了50%。
现在看来,2014年的战术是非常正确的。花了一年时间在特征工程上,团队确实对业务数据的理解更深入了很多,也积累了模型优化的一些经验。战略上 虽然大方向没错,却也存在一些问题。首先,运营需求与用户需求本来就是相关的,它们不可能完全独立,我们在优化一个指标的同时很容易对另一个指标产生副作 用。
例如,按照上面的流程图,***步的候选系统通过考虑运营需求来产生候选集,然后候选集由考虑用户需求的排序系统进行排序。如果产生的候选集很小,那 排序系统的优化空间就很小,作用自然也不会大;而如果候选集很大,那通过排序系统排序后获得最终推荐结果的做法就会降低运营需求的控制力度。
2014年底的时候我开始考虑2015年推荐系统团队的工作方向。那段时间我集中看了很多公司推荐相关的资料,其中几年前百度大推荐部门(现在已经 解散)公开的一些演讲资料对我启发***。很多公司讲推荐的资料都注重讲算法,或者数据和特征;而百度的这些资料主要偏向于从系统方向来讲。这启发我回到排 序系统的本质来看推荐系统。
搜索,广告和推荐系统,本质都是大规模排序系统。它们都遵循“候选产生 –> 排序 –> 后处理”的一般流程(见下图)。
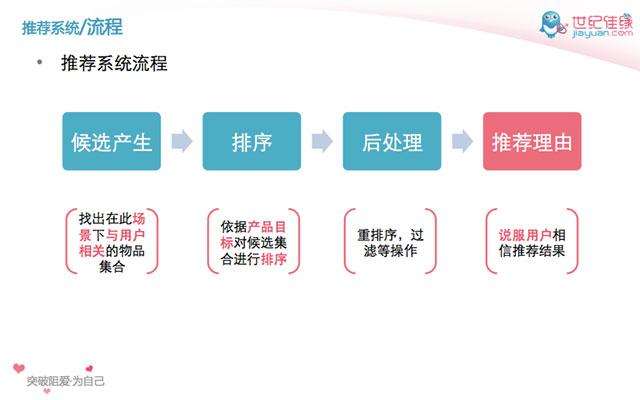
再仔细说明下上面这个流程中的前两步:
1)候选产生(检索)系统:找与用户相关的候选集合。对于佳缘来说,这里的相关候选集合可以通过(互相)满足择偶条件来获得,也可以通过算法如kNN,AR等来获得。不管用什么方式,最终目的就是把用户与候选集合联系起来。
2)排序系统:排序系统里的排序目的是***化产品目标。对佳缘来说,产品目标包括了运营目标和用户满意度。
相对于2014年运营需求与用户需求独立优化的“战略”,2015年的优化思路有所调整:
-
分离出运营需求中与用户需求耦合小的部分,使用规则控制。这样做的原因主要还是佳缘的业务逻辑太复杂,完全依靠算法达成产品目标很困难,所以加入了一些规则进行宏观控制。
-
统一优化无法分离的运营需求与用户需求。这种统一不仅体现在排序系统会同时考虑这两方面的指标,也会以较弱的形式体现在候选产生系统里,毕竟从候选产生系统产生的候选集不可能是所有与用户相关的物品(异性)。
那么,为什么把2015年叫做推荐系统的产品年?因为今年推荐系统的目标是优化产品目标!
推荐系统是为产品服务的,而不是直接为用户服务。
上面这句话听起来很简单,但其实很多时候我们会在不知不觉中认为推荐系统是直接在为用户服务的。我们在最早的时候就是犯了这个错误。
本节的***,汇总罗列下我这几年做推荐的感想:
-
技术为产品服务,而不是直接面向用户
-
数据质量是地基,保证好的质量很不容易
-
如何制定正确的优化指标真的很难
-
业务理解 > 工程实现
-
数据 > 系统 > 算法
-
快速试错
一些技术尝试
这节我只是简单罗列下最近几年自己接触的比较有代表性的一些技术,跟工作关系不大。
Dirichlet Process 和 Dirichlet Process Mixture模型
了解DP主要是因为当时在看Mahout源代码的时候发现有个算法以前竟然没接触过,觉得挺有意思就仔细学了下。DP不太好理解,它被称为分布的分 布。从DP抽取出的每个样本(一个函数)都可以被认为是一个离散随机变量的分布函数,这个随机变量以非零概率值在可数无穷个离散点上取值。DPM是非参数 贝叶斯聚类模型,聚类时可以让模型自动学习类数。虽然听着好像很不错,其实有很多槽点,具体可见参考文献2。
Latent Dirichlet Allocation (LDA)
LDA是文本处理里的利器,经常被用于对文本进行聚类,或者预处理。更详细的理论介绍可见参考文献3。当时我尝试把它用于佳缘的发信数据,看看能不 能找出一些有明显特征的发信群体。聚类结果整体上基本不可解释,但有一个类别意义很明显,这类人主要给离婚异性发信。大家可以想想这类人是什么人。尝试感 想是LDA直接用于聚类未必靠谱,但是可以把它用于数据的预处理,比如降维什么的。
Alternating Direction Method of Multipliers (ADMM)
ADMM是个优化算法框架,它把一个大问题分成可分布式同时求解的多个小问题。理论上,ADMM的框架可以解决大部分实际中的大尺度问题。槽点很多,谨慎使用!更详细的介绍可见参考文献4。
Deep Learning
前段时间,我利用佳缘的用户头像数据,尝试了DL里的一些常用算法。为了看算法的效果,我把用户的性别作为预测目标。这种预测对于佳缘的业务直接意义不大,因为用户在注册时就被要求填写其性别。
算法预测的效果还是不错的,准确度达到了87%。这还是在很小训练集上训练后获得的精度。DL麻烦是训练时需要调整的超参数实在是太多了,改一次超参数就要重跑一次,真的是很耗时。没有好的计算资源的话,建议别考虑DL。
利用GBDT模型构造新特征
实在想不出更多的有用特征?尝试下Facebook提出的利用GBDT来构造新特征的方法吧。我们的使用经验表明确实还是挺靠谱的,只要你效率能扛得住。具体介绍可见参考文献5。
特征哈希(Feature Hashing)
很多个性化特征?特征数量太多?试试特征哈希的方法吧。此方法我们目前也没使用过,欢迎有经验的人发表意见。具体介绍可见参考文献5。
不平衡数据的抽样方法
正负样本数量差异太大?训练样本太多机器跑不动?尝试下参考文献7中的抽样方法吧。我们之前的尝试表明还是有点作用的。不过如果你的数据不是大得跑不动,那尝试的必要性就不太大了