












有时我们需要查询大文本而不是数据库,这时就需要流式读入文件并实现查询算法,还要进行并行处理以提高性能。但JAVA本身缺少相应的类库,需要硬编码才能实现结构化文件计算,代码复杂且可读性差,难以实现高效的并行处理。
使用免费的集算器可以弥补这一不足。集算器封装了丰富的结构化文件读写和游标计算函数,书写简单代码就能实现并行计算,并提供了易用的JDBC接口。JAVA应用程序可以将集算器脚本文件当做数据库存储过程执行,传入参数并用JDBC获得返回结果。
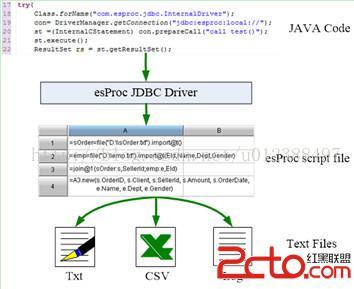
集算器与Java应用程序的集成结构如下:
下面举例说明集算器协助JAVA查询大文本的基本过程。源数据sOrder.txt如下:
要查询起止时间是startDate、endDate之间,金额大于argAmount的订单,只需使用如下代码:
A1:以游标方式打开文件。@t表示将第1行读为列名。
A2:进行结构化查询,结果为游标。
A3:执行游标,将结果读入内存,如下:
JAVA主程序可以JDBC的方式调用集算器脚本,代码如下:
Class.forName("com.esproc.jdbc.InternalDriver");
con=DriverManager.getConnection("jdbc:esproc:local://");
//调用集算器脚本(类似存储过程),其中searchbig是dfx的文件名
st=(com. esproc.jdbc.InternalCStatement)con.prepareCall("call searchbig");
//设置参数
st.setObject(1,"2010-01-01");
st.setObject(2,"2010-12-31");
st.setObject(3,2000);
//执行脚本
st.execute;
//获取结果集
ResultSetrs = st.getResultSet;
……
返回值是符合JDBC标准的ResultSet对象,调用集算器脚本和访问数据库的方法完全一样,熟悉JDBC的程序员可以很快掌握。
对于上面这类较简单的代码,还可以直接将脚本写在JDBC调用中,多行语句之间用\n分隔即可,类似执行一句较复杂的SQL,这样可以不必再保存一个脚本文件。
st = (com.esproc.jdbc.InternalCStatement)con.createStatement;
ResultSet rs1 =st.executeQuery("=file(\"D:\\sOrder.txt\").import@t\n" +"=A1.select(OrderDate>=date(\"2010-01-01\") &&OrderDate<=date(\"2010-12-31\") && Amount>2000)\n"+
"=A2.fetch");
集算器会返回***一个表达式的值。
如果查询结果内存装不下,可以在集算器中直接返回游标(即去掉A3代码),在JAVA中只需设置每批次读取的记录数即可正常读取,具体代码如下:
st.setFetchSize(1000)
关于集算器JDBC的部署和调用的更详细信息可参考集算器集成应用之被JAVA调用。
集算器还可以实现多线程并行计算,最简单方法就是在上述代码的cursor函数中使用@m,这表示多线程读取文件。
也可以手工分段,在读取和计算部分都使用多线程并行计算,代码如下:
A1:用8个游标打开文件,每次读取文件的指定部分。~表示循环变量,依次是1、2…8,@z表示将文件按字节数大致分为几部分,只读取其中一部分,集算器会自动去头补尾,以保证取出的数据是整行。
A2:针对每个游标执行查询。
A3:并行执行游标,并合并结果。@x表示合并的对象是游标,@m表示并行计算。需要注意的是,函数conj无法保证结果顺序和源数据一致。
上述代码使用了集算器内置的并行计算函数,如果计算过程较复杂,或内存可以装下计算结果,则适合用显式并行计算语句。代码如下:
A1:设定并行数。
A2:并行执行代码,作用范围是缩进的B2-B3。to(A1)=[1,2…8]表示每个线程的入口参数。线程内部可用A2来获取入口参数,线程外部可用A2获取所有线程的计算结果。
B3:查询游标,将结果读入内存,并返回给主线程。
A4:按顺序合并各线程的计算结果。
对于有序数据,可以用二分法来提高查询性能。比如数据已按Client和OrderID排序,现在要根据参数argClient和argOrder找出相应的记录,可以使用下面的代码:
begin,end是二分法的起止位置,m是中间位置。
B4:按字节数定位到中间位置,打开游标读入一条记录,集算器会自动实现去头补尾,取出完整记录。@x表示取出记录后立即关闭游标。
B5-C6:如果定位成功,则将当前记录存储在C5。
B7-C8:如果定位不成功,则继续比较集合大小并重新设置begin,end。
A9:将C5中的计算结果显式地返回给JDBC。













