HDFS数据管理
1、设置元数据与数据的存储路径,通过
dfs.name.dir,dfs.data.dir,fs.checkpoint.dir(hadoop1.x)、
hadoop.tmp.dir,dfs.namenode.name.dir,dfs.namenode.edits.dir,dfs.datanode.data.dir(hadoop2.x)等属性来设置;
2、经常执行HDFS文件系统检查工具FSCK,eg:hdfs fsck /liguodong -files -blocks;
- [root@slave1 mapreduce]# hdfs fsck /input
- Connecting to namenode via http://slave1:50070
- FSCK started by root (auth:SIMPLE) from /172.23.253.22 for path /input at Tue Jun 16 21:29:21 CST 2015
- .Status: HEALTHY
- Total size: 80 B
- Total dirs: 0
- Total files: 1
- Total symlinks: 0
- Total blocks (validated): 1 (avg. block size 80 B)
- Minimally replicated blocks: 1 (100.0 %)
- Over-replicated blocks: 0 (0.0 %)
- Under-replicated blocks: 0 (0.0 %)
- Mis-replicated blocks: 0 (0.0 %)
- Default replication factor: 1
- Average block replication: 1.0
- Corrupt blocks: 0
- Missing replicas: 0 (0.0 %)
- Number of data-nodes: 1
- Number of racks: 1
- FSCK ended at Tue Jun 16 21:29:21 CST 2015 in 1 milliseconds
- The filesystem under path '/input' is HEALTHY
3、一旦数据发生异常,可以设置NameNode为安全模式,这时NameNode为只读模式;
操作命令:hdfs dfsadmin -safemode enter | leave | get | wait
- [root@slave1 mapreduce]# hdfs dfsadmin -report
- Configured Capacity: 52844687360 (49.22 GB)
- Present Capacity: 45767090176 (42.62 GB)
- DFS Remaining: 45766246400 (42.62 GB)
- DFS Used: 843776 (824 KB)
- DFS Used%: 0.00%
- Under replicated blocks: 0
- Blocks with corrupt replicas: 0
- Missing blocks: 0
- -------------------------------------------------
- Datanodes available: 1 (1 total, 0 dead)
- Live datanodes:
- Name: 172.23.253.22:50010 (slave1)
- Hostname: slave1
- Decommission Status : Normal
- Configured Capacity: 52844687360 (49.22 GB)
- DFS Used: 843776 (824 KB)
- Non DFS Used: 7077597184 (6.59 GB)
- DFS Remaining: 45766246400 (42.62 GB)
- DFS Used%: 0.00%
- DFS Remaining%: 86.61%
- Last contact: Tue Jun 16 21:27:17 CST 2015
- [root@slave1 mapreduce]# hdfs dfsadmin -safemode get
- Safe mode is OFF
4、每一个DataNode都会运行一个数据扫描线程,它可以检测并通过修复命令来修复坏块或丢失的数据块,通过属性设置扫描周期;
dfs.datanode.scan.period.hourses, 默认是504小时。
MapReduce作业管理
查看Job信息:mapred job -list;
杀死Job:mapred job -kill;
查看指定路径下的历史日志汇总:mapred job -history output-dir;
打印map和reduce完成的百分比和所有计数器:mapred job -status job_id;
- [root@slave1 mapreduce]# mapred job
- Usage: CLI <command> <args>
- [-submit <job-file>]
- [-status <job-id>]
- [-counter <job-id> <group-name> <counter-name>]
- [-kill <job-id>]
- [-set-priority <job-id> <priority>]. Valid values for priorities are: VERY_HIGH HIGH NORMAL LOW VERY_LOW
- [-events <job-id> <from-event-#> <#-of-events>]
- [-history <jobHistoryFile>]
- [-list [all]]
- [-list-active-trackers]
- [-list-blacklisted-trackers]
- [-list-attempt-ids <job-id> <task-type> <task-state>]. Valid values for <task-type> are REDUCE MAP. Valid values for <task-state> are running, completed
- [-kill-task <task-attempt-id>]
- [-fail-task <task-attempt-id>]
- [-logs <job-id> <task-attempt-id>]
- Generic options supported are
- -conf <configuration file> specify an application configuration file
- -D <property=value> use value for given property
- -fs <local|namenode:port> specify a namenode
- -jt <local|jobtracker:port> specify a job tracker
- -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
- -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
- -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
- [root@slave1 mapreduce]# mapred job -list
- 15/06/16 21:33:25 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
- Total jobs:0
- JobId State StartTime UserName Queue Priority UsedContainers RsvdContainers UsedMem RsvdMem NeededMem AM info
#p#
Hadoop集群安全
Hadoop自带两种安全机制:Simple机制、Kerberos机制
1、Simple机制:
Simple机制是JAAS协议与delegation token结合的一种机制,JAAS(Java Authentication and Authorization Service)java认证与授权服务;
(1)用户提交作业时,JobTracker端要进行身份核实,先是验证到底是不是这个人,即通过检查执行当前代码的人与JobConf中的user.name中的用户是否一致;
(2)然后检查ACL(Access Control List)配置文件(由管理员配置)看你是否有提交作业的权限。一旦你通过验证,会获取HDFS或者mapreduce授予的delegation token(访问不同模块有不同的delegation token),之后的任何操作,比如访问文件,均要检查该token是否存在,且使用者跟之前注册使用该token的人是否一致。
2、Kerberos机制:
Kerberos机制是基于认证服务器的一种方式;
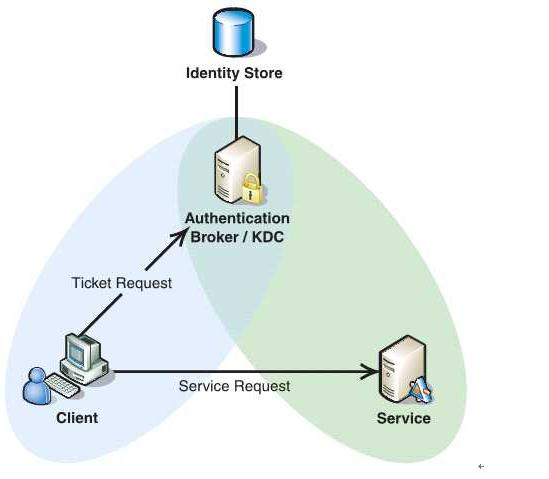
Princal(安全个体):被认证的个体,有一个名字和口令;
KDC(key distribution center):是一个网络服务,提供ticket和临时会话密钥;
Ticket:一个记录,客户用它来向服务器证明自己的身份,包括客户标识、会话密钥、时间戳;
AS(Authentication Server):认证服务器;
TSG(Ticket Granting Server):许可认证服务器;
(1)Client将之前获得TGT和要请求的服务信息(服务名等)发送给KDC,
KDC中的Ticket Granting Service将为Client和Service之间生成一个Session Key用于Service对Client的身份鉴别。
然后KDC将这个Session Key和用户名,用户地址(IP),服务名,有效期, 时间戳一起包装成一个Ticket(这些信息最终用于Service对Client的身份鉴别)发送给Service,
不过Kerberos协议并没有直接将Ticket发送给Service,而是通过Client转发给Service,所以有了第二步。
(2)此时KDC将刚才的Ticket转发给Client。
由于这个Ticket是要给Service的,不能让Client看到,所以KDC用协议开始前KDC与Service之间的密钥将Ticket加密后再发送给Client。
同时为了让Client和Service之间共享那个密钥(KDC在***步为它们创建的Session Key),
KDC用Client与它之间的密钥将Session Key加密随加密的Ticket一起返回给Client。
(3)为了完成Ticket的传递,Client将刚才收到的Ticket转发到Service。
由于Client不知道KDC与Service之间的密钥,所以它无法算改Ticket中的信息。
同时Client将收到的Session Key解密出来,然后将自己的用户名,用户地址(IP)打包成Authenticator用Session Key加密也发送给Service。
(4)Service 收到Ticket后利用它与KDC之间的密钥将Ticket中的信息解密出来,从而获得Session Key和用户名,用户地址(IP),服务名,有效期。
然后再用Session Key将Authenticator解密从而获得用户名,用户地址(IP)将其与之前Ticket中解密出来的用户名,用户地址(IP)做比较从而验证Client的身份。
(5)如果Service有返回结果,将其返回给Client。
#p#
Hadoop集群内部使用Kerberos进行认证
好处:
可靠:Hadoop本身并没有认证功能和创建用户组功能,使用依靠外围的认证系统;
高效:Kerberos使用对称钥匙操作,比SSL的公共密钥快;
操作简单:用户可以方便进行操作,不需要很复杂的指令。比如废除一个用户只需要从Kerbores的KDC数据库中删除即可。
HDFS安全
1、Client获取namenode初始访问认证(使用kerberos)后,会获取一个delegation token,这个token可以作为接下来访问HDFS或提交作业的凭证;
2、同样为了读取某个文件,Client首先要与namenode交互,获取对应block的block access token,
然后到相应的datanode上读取各个block ,
而datanode在初始启动向namenode注册时候,已经提前获取了这些token,
当client要从TaskTracker上读取block时,首先验证token,通过才允许读取。
MapReduce安全
1、所有关于作业的提交或者作业运行状态的追踪均是采用带有Kerberos认证的RPC实现的。
授权用户提交作业时,JobTracker会为之生成一个delegation token,该token将被作为job的一部分存储到HDFS上并通过RPC分发给各个TaskTracker,一旦job运行结束,该token失效。
2、用户提交作业的每个task均是以用户身份启动的,这样一个用户的task便不可以向TaskTracker或者其他用户的task发送操作系统信号,给其他用户造成干扰。这要求为每个用户在所有的TaskTracker上建一个账号;
3、当一个map task运行结束时,它要将计算结果告诉管理它的TaskTracker,之后每个reduce task会通过HTTP向该TaskTracker请求自己要处理的那块数据,Hadoop应该确保其他用户不可以获取map task的中间结果,
其执行过程是:reduce task对“请求URL”和“当前时间”计算HMAC-SHA1值,并将该值作为请求的一部分发动给TaskTracker,TaskTracker收到后会验证该值的正确性。
博文出处:http://blog.csdn.net/scgaliguodong123_/article/details/46523569