文|叶蓬 【按:此文是与我的《基于大数据分析的安全管理平台技术研究及应用》同期发表在内刊上的我的同事们的作品,转载于此。这些基础性的研究和测试对比分析,对于我们的BDSA技术路线选定大有帮助。】
引言
大数据查询分析是云计算中核心问题之一,自从Google在2006年之前的几篇论文奠定云计算领域基础,尤其是GFS、Map-Reduce、 Bigtable被称为云计算底层技术三大基石。GFS、Map-Reduce技术直接支持了Apache Hadoop项目的诞生。Bigtable和Amazon Dynamo直接催生了NoSQL这个崭新的数据库领域,撼动了RDBMS在商用数据库和数据仓库方面几十年的统治性地位。FaceBook的Hive项 目是建立在Hadoop上的数据仓库基础构架,提供了一系列用于存储、查询和分析大规模数据的工具。当我们还浸淫在GFS、Map-Reduce、 Bigtable等Google技术中,并进行理解、掌握、模仿时,Google在2009年之后,连续推出多项新技术,包括:Dremel、 Pregel、Percolator、Spanner和F1。其中,Dremel促使了实时计算系统的兴起,Pregel开辟了图数据计算这个新方 向,Percolator使分布式增量索引更新成为文本检索领域的新标准,Spanner和F1向我们展现了跨数据中心数据库的可能。在Google的第 二波技术浪潮中,基于Hive和Dremel,新兴的大数据公司Cloudera开源了大数据查询分析引擎Impala,Hortonworks开源了 Stinger,Fackbook开源了Presto。类似Pregel,UC Berkeley AMPLAB实验室开发了Spark图计算框架,并以Spark为核心开源了大数据查询分析引擎Shark。由于某电信运营商项目中大数据查询引擎选型需 求,本文将会对Hive、Impala、Shark、Stinger和Presto这五类主流的开源大数据查询分析引擎进行简要介绍以及性能比较,***进 行总结与展望。Hive、Impala、Shark、Stinger和Presto的进化图谱如图1所示。
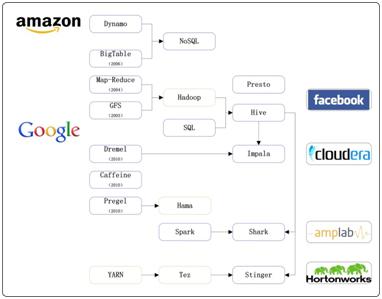
图1. Impala、Shark、Stinger和Presto的进化图谱
当前主流引擎简介
基于Map-Reduce模式的Hadoop擅长数据批处理,不是特别符合即时查询的场景。实时查询一般使用MPP (Massively Parallel Processing)的架构,因此用户需要在Hadoop和MPP两种技术中选择。在Google的第二波技术浪潮中,一些基于Hadoop架构的快速 SQL访问技术逐步获得人们关注。现在有一种新的趋势是MPP和Hadoop相结合提供快速SQL访问框架。最近有四个很热门的开源工具出 来:Impala、Shark、Stinger和Presto。这也显示了大数据领域对于Hadoop生态系统中支持实时查询的期望。总体来 说,Impala、Shark、Stinger和Presto四个系统都是类SQL实时大数据查询分析引擎,但是它们的技术侧重点完全不同。而且它们也不 是为了替换Hive而生,Hive在做数据仓库时是非常有价值的。这四个系统与Hive都是构建在Hadoop之上的数据查询工具,各有不同的侧重适应 面,但从客户端使用来看它们与Hive有很多的共同之处,如数据表元数据、Thrift接口、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储 资源池等。Hive与Impala、Shark、Stinger、Presto在Hadoop中的关系如图2所示。Hive适用于长时间的批处理查询分 析,而Impala、Shark、Stinger和Presto适用于实时交互式SQL查询,它们给数据分析人员提供了快速实验、验证想法的大数据分析工 具。可以先使用Hive进行数据转换处理,之后使用这四个系统中的一个在Hive处理后的结果数据集上进行快速的数据分析。下面,从问题域出发简单介绍 Hive、Impala、Shark、Stinger和Presto:
1) Hive,披着SQL外衣的Map-Reduce。Hive是为方便用户使用Map-Reduce而在外 面封装了一层SQL,由于Hive采 用了SQL,它的问题域比Map-Reduce更窄,因为很多问题,SQL表达不出来,比如一些数据挖掘算法,推荐算法、图像识别算法等,这些仍只能通过 编写Map-Reduce完成。
2) Impala:Google Dremel的开源实现(Apache Drill类似),因为交互式实时计算需求,Cloudera推出了Impala系统,该系统适用于交互式实时处理场景,要求***产生的数据量一定要少。
3) Shark/Spark:为了提高Map-Reduce的计算效率,Berkeley的AMPLab实验室开发了Spark,Spark可看 做基于内存的Map-Reduce实现,此外,伯克利还在Spark基础上封装了一层SQL,产生了一个新的类似Hive的系统Shark。
4) Stinger Initiative(Tez optimized Hive):Hortonworks 开源了一个DAG计算框架Tez,Tez可以理解为Google Pregel的开源实现,该框架可以像Map-Reduce一样,可以用来设计DAG应用程序,但需要注意的是,Tez只能运行在YARN上。Tez的一 个重要应用是优化Hive和PIG这种典型的DAG应用场景,它通过减少数据读写IO,优化DAG流程使得Hive速度提供了很多倍。
5) Presto:FaceBook于2013年11月份开源了Presto,一个分布式SQL查询引擎,它 被设计为用来专门进行高速、实时的数 据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。Presto设计了一个简单的数据存储的抽象层,来满足在不同数据存储系统(包括HBase、HDFS、Scribe等)之上都可 以使用SQL进行查询。
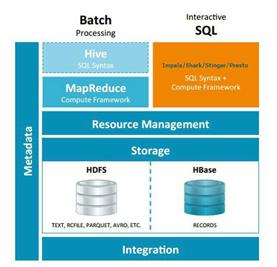
图2. Hive与Impala、Shark、Stinger、Presto在Hadoop中的关系
#p#
当前主流引擎架构
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为 Map-Reduce任务进行运行,十分适合数据仓库的统计分析。其架构如图3所示,Hadoop和Map-Reduce是Hive架构的根基。Hive 架构包括如下组件:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、Meta Store和Driver(Complier、Optimizer和Executor)。
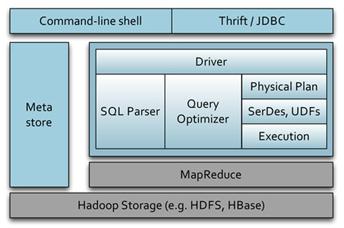
图3. Hive架构
Impala架构
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,它可以看成是Google Dremel架构和MPP (Massively Parallel Processing)结构的结合体。Impala没有再使用缓慢的Hive&Map-Reduce批处理,而是通过使用与商用并行关系数据库中 类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟,其架构如图4所 示,Impala主要由Impalad,State Store和CLI组成。Impalad与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的 Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计 划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由 Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。Impala State Store跟踪集群中的Impalad的健康状态及位置信息,由state-stored进程表示,它通过创建多个线程来处理Impalad的注册订阅和 与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后,因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。 CLI提供给用户查询使用的命令行工具,同时Impala还提供了Hue,JDBC,ODBC,Thrift使用接口。
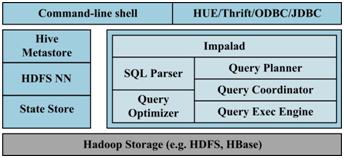
图4. Impala架构
Shark架构
Shark是UC Berkeley AMPLAB开源的一款数据仓库产品,它完全兼容Hive的HQL语法,但与Hive不同的是,Hive的计算框架采用Map-Reduce,而 Shark采用Spark。所以,Hive是SQL on Map-Reduce,而Shark是Hive on Spark。其架构如图4所示,为了***程度的保持和Hive的兼容性,Shark复用了Hive的大部分组件,如下所示:
1) SQL Parser&Plan generation: Shark完全兼容Hive的HQL语法,而且Shark使用了Hive的API来实现query Parsing和 query Plan generation,仅仅***的Physical Plan execution阶段用Spark代替Hadoop Map-Reduce;
2) metastore:Shark采用和Hive一样的meta信息,Hive里创建的表用Shark可无缝访问;
3) SerDe: Shark的序列化机制以及数据类型与Hive完全一致;
4) UDF: Shark可重用Hive里的所有UDF。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD(Resilient Distributed Dataset),实现数据重用,进而加快特定数据集的检索。同时,Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询 和运算分析能结合在一起,***化RDD的重复使用;
5) Driver:Shark在Hive的CliDriver基础上进行了一个封装,生成一个SharkCliDriver,这是shark命令的入口;
6) ThriftServer:Shark在Hive的ThriftServer(支持JDBC/ODBC)基础上,做了一个封装,生成了一个SharkServer,也提供JDBC/ODBC服务。
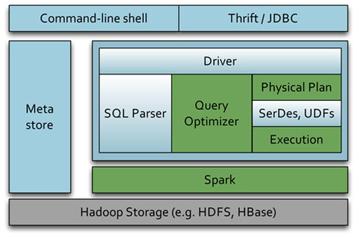
图5. Shark架构
Spark是UC Berkeley AMP lab所开源的类Hadoop Map-Reduce的通用的并行计算框架,Spark基于Map-Reduce算法实现的分布式计算,拥有Hadoop Map-Reduce所具有的优点;但不同于Map-Reduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark 能更好地适用于数据挖掘与机器学习等需要迭代的Map-Reduce的算法。其架构如图6所示:
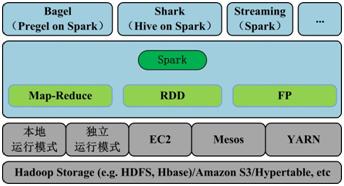
图6. Spark架构
与Hadoop的对比,Spark的中间数据放到内存中,对于迭代运算效率更高,因此Spark适用于需要多次操作特定数据集的应用场合。需要反复 操作的 次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。Spark比Hadoop更通用,Spark提供的数据 集操作类型有很多种(map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等),而Hadoop只提供了Map和Reduce两种操作。Spark可以直接对HDFS进行数据的读写,同样支持 Spark on YARN。Spark可以与Map-Reduce运行于同集群中,共享存储资源与计算,数据仓库Shark实现上借用Hive,几乎与Hive完全兼容。
Stinger架构
Stinger是Hortonworks开源的一个实时类SQL即时查询系统,声称可以提升较Hive 100倍的速度。与Hive不同的是,Stinger采用Tez。所以,Hive是SQL on Map-Reduce,而Stinger是Hive on Tez。Tez的一个重要作用是优化Hive和PIG这种典型的DAG应用场景,它通过减少数据读写IO,优化DAG流程使得Hive速度提供了很多倍。 其架构如图7所示, Stinger是在Hive的现有基础上加了一个优化层Tez(此框架是基于Yarn),所有的查询和统计都要经过它的优化层来处理,以减少不必要的工作 以及资源开销。虽然Stinger也对Hive进行了较多的优化与加强,Stinger总体性能还是依赖其子系统Tez的表现。而Tez是 Hortonworks开源的一个DAG计算框架,Tez可以理解为Google Pregel的开源实现,该框架可以像Map-Reduce一样,用来设计DAG应用程序,但需要注意的是,Tez只能运行在YARN上。
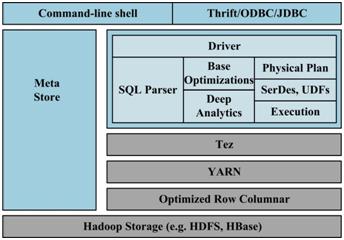
图7. Stinger架构
Presto架构
2013年11月Facebook开源了一个分布式SQL查询引擎Presto,它被设计为用来专门进行高速、实时的数据分析。它支持标准的 ANSI SQL子集,包括复杂查询、聚合、连接和窗口函数。其简化的架构如图8所示,客户端将SQL查询发送到Presto的协调器。协调器会进行语法检查、分析 和规划查询计划。调度器将执行的管道组合在一起,将任务分配给那些里数据最近的节点,然后监控执行过程。客户端从输出段中将数据取出,这些数据是从更底层 的处理段中依次取出的。Presto的运行模型与Hive有着本质的区别。Hive将查询翻译成多阶段的Map-Reduce任务,一个接着一个地运行。 每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然而Presto引擎没有使用Map-Reduce。它使用了一个定制的查询执行引擎和响应 操作符来支持SQL的语法。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘 读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的时候就会将数据从一个处理段传入到下一个处理段。 这样的方式会大大的减少各种查询的端到端响应时间。同时,Presto设计了一个简单的数据存储抽象层,来满足在不同数据存储系统之上都可以使用SQL进 行查询。存储连接器目前支持除Hive/HDFS外,还支持HBase、Scribe和定制开发的系统。
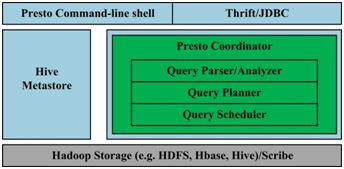
图8. Presto架构
#p#
性能评测总结
通过对Hive、Impala、Shark、Stinger和Presto的评测和分析,总结如下:
1) 列存储一般对查询性能提升明显,尤其是大表是一个包含很多列的表。例如,从Stinger(Hive 0.11 with ORCFile)VS Hive,以及Impala的Parquet VS Text file;
2) 绕开MR计算模型,省去中间结果的持久化和MR任务调度的延迟,会带来性能提升。例如,Impala,Shark,Presto要好于Hive和Stinger,但这种优势随着数据量增加和查询变复杂而减弱;
3) 使用MPP数据库技术对连接查询有帮助。例如,Impala在两表,多表连接查询中优势明显;
4) 充分利用缓存的系统在内存充足的情况下性能优势明显。例如,Shark,Impala在小数据量时性能优势明显;内存不足时性能下降严重,Shark会出现很多问题;
5) 数据倾斜会严重影响一些系统的性能。例如,Hive、Stinger、Shark对数据倾斜比较敏感,容易造成倾斜;Impala受这方面的影响似乎不大;
对于Hive、Impala、Shark、Stinger和Presto这五类开源的分析引擎,在大多数情况下,Imapla的综合性能是最稳定 的,时间 性能也是***的,而且其安装配置过程也相对容易。其他分别为Presto、Shark、Stinger和Hive。在内存足够和非Join操作情况 下,Shark的性能是***的。
总结与展望
对大数据分析的项目来说,技术往往不是最关键的,关键在于谁的生态系统更强,技术上一时的领先并不足以保证项目的最终成功。对于Hive、 Impala、Shark、Stinger和Presto来讲,***哪一款产品会成为事实上的标准还很难说,但我们唯一可以确定并坚信的一点是,大数据分 析将随着新技术的不断推陈出新而不断普及开来,这对用户永远都是一件幸事。举个例子,如果读者注意过下一代Hadoop(YARN)的发展的话就会发现, 其实YARN已经支持Map-Reduce之外的计算范式(例如Shark,Impala等),因此将来Hadoop将可能作为一个兼容并包的大平台存 在,在其上提供各种各样的数据处理技术,有应对秒量级查询的,有应对大数据批处理的,各种功能应有尽有,满足用户各方面的需求。
除了Hive、Impala、Shark、Stinger和Presto这样的开源方案外,像Oracle,EMC等传统厂商也没在坐以待毙等着自 己的市 场被开源软件侵吞。像EMC就推出了HAWQ系统,并号称其性能比之Impala快上十几倍,而Amazon的Redshift也提供了比Impala更 好的性能。虽然说开源软件因为其强大的成本优势而拥有极其强大的力量,但是传统数据库厂商仍会尝试推出性能、稳定性、维护服务等指标上更加强大的产品与之 进行差异化竞争,并同时参与开源社区、借力开源软件来丰富自己的产品线、提升自己的竞争力,并通过更多的高附加值服务来满足某些消费者需求。毕竟,这些厂 商往往已在并行数据库等传统领域积累了大量的技术和经验,这些底蕴还是非常深厚的。总的来看,未来的大数据分析技术将会变得越来越成熟、越来越便宜、越来 越易用;相应的,用户将会更容易更方便地从自己的大数据中挖掘出有价值的商业信息。