













本文主要从IaaS视角,分享SCE通过怎样的实践来支持上层产品线的容器化诉求。首先聊聊我们为什么做支持Docker技术这件事情,然后介绍下Docker支持实践的方方面面。***给出实践过程中总结出来的一些经验及踩过的一些坑,以及后续需要深耕的点。
先假定今晚的听众至少已经小范围使用过Docker技术,熟悉相关概念及原理。
前几期DockOne技术分享已经针对Docker的几个技术要点做了深入分析,所以我今晚主要从IaaS视角,分享SCE通过怎样的实践来支持上层产品线的容器化诉求。
----------
为何支持Docker技术
为何做这件事
先介绍下我浪SCE。SCE是新浪研发中心主推私有云产品,已经覆盖到公司内部所有产品线。基于OpenStack定制,整合了公司通道机、CMDB,为公司内部全产品线提供IaaS服务。公有云版本近期开始内测。
首先,OpenStack与Docker天生互补。
- OpenStack面向IaaS,以资源为中心,打包OS;能够提供成熟的资源限制与隔离能力;多OS系列支持;
- Docker则面向PaaS,以服务为中心,打包service;轻快好省;
目前IaaS业界主要以提供云主机服务为主,有着成熟的资源限制、资源隔离能力,但本质上是对OS的打包,无法满足在应对峰值访问、快速伸缩、快速部署等方面诉求。而docker与生俱来的特性”轻、快、好、省“,则恰恰可以弥补IaaS在此方面的不足。当然OpenStack社区为了能够更好的支持docker也尝试做了很多努力,这个后面会讲到。
其次,SCE运维过程发现,产品线对容器技术需求相当旺盛。
- 快速部署;
- 快速起停、创建与销毁;
- 一致的开发测试环境;
- 演示、试用环境;
- 解决设备成本,充分利用资源;
- 技术方案快速验证;
- 更多......
IaaS短板+需求驱动,让我们意识到:SCE很有必要也很适合做支持容器技术这件事。
IaaS厂商Docker支持概况
调研分析了几个IaaS圈子比较有代表性的巨头及新贵,从调研结果可以看出,目前IaaS厂商对Docker的支持还比较薄弱。
只有阿里云为Docker用户多做了一些事情,提供了阿里官方Registry。但没有提供较新的支持Docker的云主机,只有一个第三方提供了一个很老的镜像,几乎没有可用性。
UnitedStack和青云只提供了CoreOS。而实际上,CoreOS的用户接受度很低。我们SCE也尝试过提供CoreOS,但由于和公司CentOS系统使用方式差异太大,基本没有产品线愿意使用并迁移到CoreOS上面来。
----------
Docker支持实践的方方面面
基于以上需求及调研,SCE主要在Registry、Hub、支持Docker的虚拟机镜像、日志存储与检索、网络及存储驱动等方面做了一些实践,致力于让产品线用户更方便高效的使用Docker技术,推动Docker在公司内的使用。
Registry+Hub方案
Registry后端存储方案方面,其实大家已分享较多,大多是用dev及s3。SCE当然使用自家新浪 S3了,当时的***个方案就是Docker Registry sinastorage driver + sina s3。可靠性性自然不用多言,但由于依赖storage driver,追查问题过程中,调试及维护都比较麻烦,并且更新后还需要自动构建新镜像。
既然自家提供可靠云硬盘,为什么不为自己提供服务呢。果断将忍了老鼻子时间的方案一改为了localstorage + SCE云硬盘,不再依赖driver的日子舒服多了,另外还能享受到云硬盘的snapshot、resize等高级特性。
所以,对于正在Registry storage backend选型的朋友,给出一些建议以供参考:
- 对镜像存储可靠性无要求的使用场景,建议直接使用dev;
- 对镜像存储可靠性要求较高的使用场景,如果你是在IaaS上跑,强烈建议使用localstorage + 云硬盘方案;
- 对镜像存储可靠性要求较高的使用场景,如果你没在IaaS上跑,可以拿点大洋出来用S3等;
- 对镜像存储可靠性要求较高的使用场景,如果你没在IaaS上跑,又不想花钱,想用自家存储,就只能写个自家的driver了。我才不会告诉你,这种情况排查问题有多么糟心。
为了给产品线提供便捷的镜像查看及检索服务,SCE与微博平台合作,共同推出了SCE docker hub,基于docker-registry-frontend开发实现。与SCE现有服务打通,并支持repo、tag、详细信息、 Dockerfile的查看、检索与管理等。
为了产品线更方便使用Docker官方镜像,我们的自动同步工具会依据镜像注册表,周期性的自动同步Docker官方镜像到SCE分布式后端存储集群,使得产品线用户可以通过内网快速pull到Docker官方镜像。
由于SCE不保证也不可能保证Docker Hub官方镜像的安全性,所以建议产品线***使用SCE官方发布的image或构建自己的baseimage。
对于产品线私有Registry的需求,SCE也提供了相应的一键构建工具集。
#p#
CentOS 7 + Docker镜像
SCE在Docker支持方面主要做了如下一些工作:
1)集成Docker 1.5、Docker-Compose 1.2环境;
2)提供docker-ip、docker-pid、docker-enter等cli,简化用户使用;
3)与DIP合作,支持rsyslog-kafka,解决日志监控检索问题;
4)与微博平台合作,提供muti-if-adapter工具,解决同一主宿机相同服务端口冲突的问题;
5) 更多......
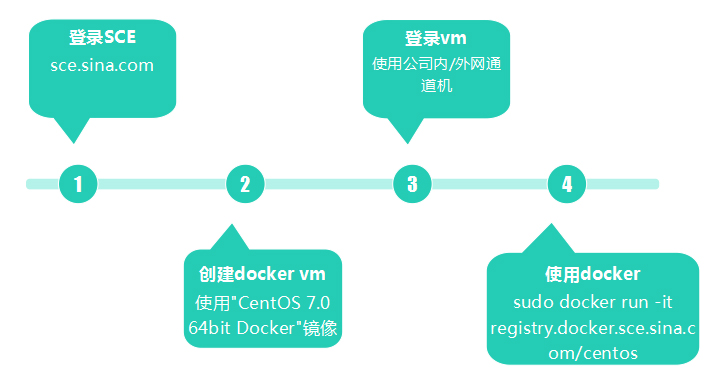
SCE上使用Docker
有了如上工作支撑,在SCE上使用docker就变得相当便捷。
日志方案
目前SCE主要支持3中日志方案:
app打container logfile;
app打stdout,stderr;
app+agent打远端;
前两种方案适用于对日志要求不高的使用场景,如开发测试。
第三种方案则适用于真实的业务场景、生产环境,这些场景对日志持久化、检索、监控、告警等方面都有较强需求;
Docker 1.6的syslog driver目前可用性、易用性都还不太理想,但值得关注。
app+rsyslog-kafka方案
上面提到的第三种日志方案,我们是通过ELK方案实现的。
架构图
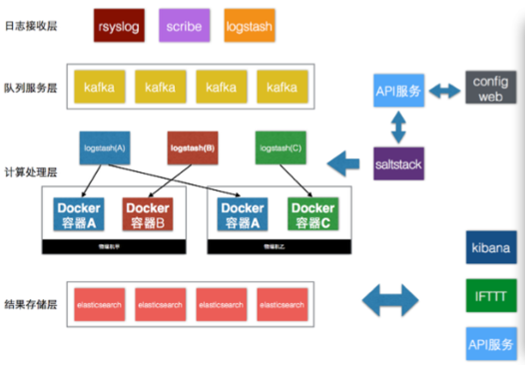
日志流
app >>> container rsyslog-kafka >>> kafka >>> logstash >>> elasticsearch >>> kibana
业务流
1.产品线走DIP实时日志分析服务接入;
- DIP审批;
- config_web基于Docker Swarm api动态扩展logstash集群;
2. 给出用户接入所需数据,如Kafka broker、topic;
产品线依据接入数据创建container;
1)
- docker run -d -e KAFKA_ADDR=... -e KAFKA_TOPIC=... -e LOG_FILE=... -v $(pwd)/kafka_config.sh:${SOME_DIR}/kafka_config.sh ...
2)遵守SCE log接入规范,container中的run.sh需要调用SCE提供给的日志配置工具docker/tools/rsyslog_config.sh;
3) rsyslog_config.sh会按需自动配置rsyslog,接入过程及细节对产品线透明;
#p#
网络模式
目前产品线大多使用的还是bridge和host,虽然这两种模式都存在一些问题。
两者虽存在一些问题,但还是能够满足中小规模集群网络需求的。
但规模上来后,上面两种模式就不适用了。对于大规模网络解决方案,我们后续将积极跟进,主要计划调研ovs/weave/Flannel等方案。
Libnetwork driver除了平移过来的bridge、host、null,还提供了remote,以支持分布式bridge;后续计划提供更多driver以解决目前的网络问题,值得重点关注。
另外,对于产品线提出的一些有意义的需求,如微博平台提出的“同一主宿机相同服务端口冲突的问题”,SCE会和产品线一道积极探索相应的解决方案;
存储驱动选型
这部分主要是开始时,存储驱动方案选型的一些考虑。
- aufs。Docker最初采用的文件系统,一直没能合入内核,因此兼容性差,仅有Ubuntu支持。需要用户自己编译,使用起来比较麻烦;
- btrfs。数据并没有直接被写入而是先是被写入到日志,在有连续地写入流的情况下,性能可能会折半;
- overlayfs。一种新的unionfs,但对内核版本要求太高,需要kernel 3.18+;
- devicemapper。默认driver。可以说是目前一般情况下的***方案了。SCE就是采用此driver。
devicemapper相关的一些实践及坑会在稍后提到。
集群管理
目前SCE主要推荐3个集群管理工具:Shipyard、Swarm、Kubernetes。
Shipyard
- 支持跨主机的container集群管理
- 轻量级,学习成本低
- 支持简单的资源调度
- 支持GUI图表展示
- 支持实例横向扩展
Swarm
- Docker官方主推的集群管理方案
- 相对轻量级,学习成本较低
- 支持多discovery backend
- 丰富的资源调度Filter
- Rest API,完全兼容Docker API
- 尚有一些坑
- 目前产品线最易接受,且使用率最多的方案
Kubernetes
- Google Borg/Omega开源实现
- 更新迭代太块,架构及实现相对复杂,学习成本、改造成本较高
- 资源调度
- 扩容缩容
- 故障自动恢复
- 多实例负载均衡
- 对OpenStack支持较好
- 跟进中
三者各有优劣,具体使用哪个工具还是需要依据具体的业务需要而定,而并不是说Kubernetes强大就一定是好的。
根据目前产品线使用及反馈来看,swarm还是更容易被接收一些。
与OpenStack集成进展
接下来,我们是IaaS,所以必须要说一下与OpenStack集成进展。如何与OpenStack更好的集成,充分发挥两者优势,是我们一直关注的一个点。
目前主要有三种方案:
- nova + docker driver;
- heat + docker driver;
- magnum;
Nova driver及heat driver两种方案,都存在一些硬伤。如nova driver方案把container当作VM处理,会牺牲掉Docker的所有高级特性,这显然是不能被接收的;又如heat driver方案,没有资源调度,创建时必须要指定host,这显然只能适用于小微规模。
OpenStack社区本年初终于开始发力CaaS新项目magnum。通过集成Heat,来支持使用Docker的高级功能;可以集成 Swarm、Gantt或Mesos,实现Docker集群资源调度(现计划是使用swarm做调度);Magnum还将与Kubernetes深度整合。
Magnum已找准此前两种解决方案的痛点,并正在用恰当的方式解决此问题。非常值得跟进。
另外,此次温哥华OpenStack Summit上,OpenStack基金会除了还表示将积极推进Magnum子项目,在技术上实现容器与OpenStack的深度整合。
----------
#p#
实践经验&踩过的坑
下面介绍的内容,大多是产品线问到的,以及SCE在Docker实践过程中总结出来的经验教训,都已文档化到SCE官方Docker wiki。从SCE Docker wiki里摘取了一些实践经验&踩过的坑,想必大家或多或少已经实践过或踩过。如果还没遇到这些问题,希望我们的这些经验总结能对你有所帮助。
镜像制作方面
- 建议用Dockerfile build镜像,镜像文档化;
- Dockerfile中,value千万别加""。因为docker会把你的""作为value的一部分;
- 最小化镜像大小,分层设计,尽量复用;
运行容器方面
- 一容器一进程,便于服务监控与资源隔离;
- 不建议用latest
- 对于提供服务的container,建议养成加--restart的习惯
数据存放方面
- 建议采用volume挂载方式
- 不依赖host目录,便于共享与迁移;
资源限制方面
- cgroup允许进程超限使用,即:在有空余资源的情况下,允许使用超出资源限制的更多资源。
- cgroup仅在必要时(资源不足时)限制资源使用,比如:当若干进程同时大量地使用CPU。
- cpu share enforcement仅会在多个进程运行在相同核上的情况下发生。也就是说,即使你机器上的两个container cpu限制不同,如果你把一个container绑定在core1,而把另外一个container绑定在core2,那么这两个container都能打满各自的核。
资源隔离方面
- user ns是通过将container的uid、gid映射为node上的uid、gid来实现user隔离的;
- 也就是说,你在node上只能看到container的uid,而看不到uname,除非这个uid在container和node上的uname相同;
- 也就是说,你在node上看到的container上的进程的所属用户的uname不一定是container上运行这个进程的uname,但uid一定是container上运行这个进程的uid;
swarm & compose使用方面
- 注意swarm strategies尚不成熟,binpack strategy实现存在一些问题,会导致***调度出来的node不是你预期的。
- 注意compose尚不成熟,可能会遇到单个启container没问题,放到compose启就失败的问题。如:部署启动时间依赖性强的容器很可能会导致失败;
container方面
- 注意dm默认pool及container存储空间大小问题。container默认10G,pool默认100G,你可能需要通过dm.basesize、dm.loopdatasize按需扩容;
- 注意nsenter进容器,看不到配置在container里的env变量;查看env建议用docker exec或docker inspect;
- 注意docker daemon、docker daemon的default-ulimit和docker run的ulimit三者间的继承关系;
由于篇幅所限,这里就不再过多列举。
----------
后续计划
下面给出SCE后续需要继续深耕的几个点。
- 提供CI & CD解决方案
- 探索大规模集群网络方案
- 持续跟进大规模集群管理方案
- 深入调研OpenStack与Docker整合方案
----------
Q&A
问:如何实现跨机部署?
答:shipyard和swarm都可,当然还有其它方案。shipyard有不错的web UI,支持container多机部署,调度基于tag,还可以scale。swarm调度策略比较灵活,可以依据你指定的filter、weighter进行调度部署。
问:Compose能否实现跨机编排?
答:不行。目前只支持单机编排。
问:container监控是如何实现的?
答:cadvisor做container监控。监控这部分也是有一定工作需要去想去做的,比如说可以考虑和EK结合提来,提供一个独立的docker集群监控解决方案出来。
问:如何对某一容器进行扩容?
答:目前没有比较好的解决办法,我们的建议的做法是删了再启个大的。
数据存放方案如何选择,以保证数据安全性和易扩展、易迁移?
对于保证数据安全性需求,建议使用local + 云硬盘方案;
对于易扩展、易迁移需求,建议使用数据写image或volume挂载方案;
如果有高性能需求,并且你的container是跑在物理机上的,建议使用local volume + host dev方案;
没有方案是***的,具体方案选型还是需要依据具体的使用场景而定。
问:SCE方案中,docker container大概是跑在那一层?
答:大概的栈是IaaS >>> CaaS,SCE docker container是跑在CaaS。
===========================
以上内容根据2015年6月2日晚微信群分享内容整理。分享人赵海川,新浪SCE工程师,主要负责虚拟化和Docker相关工作,致力于推动Docker在公司内的使用。微博:wangzi19870227。

















