在任何系统中,日志都是非常重要的组成部分,它是反映系统运行情况的重要依据,也是排查问题时的必要线索。绝大多数人都认可日志的重要性,但是又有多少人仔细想过该怎么打日志,日志对性能的影响究竟有多大呢?今天就让我们来聊聊Java日志性能那些事。
DEBUG级别的日志在生产环境中不会输出到文件中,也可能带来不小的开销。我们撇开判断和方法调用的开销,在Log4J 2.x的性能文档中 有这样一组对比:logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i])); logger.debug("Entry number: {} is {}", i, entry[i]);
上面两条语句在日志输出上的效果是一样的,但是在关闭DEBUG日志时,它们的开销就不一样了,主要的影响在于字符串转换和字符串拼接上,无论是否生效,前者都会将变量转换为字符串并进行拼接,而后者则只会在需要时执行这些操作。Log4J官方的测试结论是两者在性能上能相差两个数量级。试想一下,如果某个对象的toString方法里用了ToStringBuilder来反射输出几十个属性时,这时能省下多少资源。
因此,某些仍在使用Log4J 1.x或Apache Commons Logging(它们不支持{}模板的写法)的公司都会有相应的编码规范,要求在一定级别的日志(比如DEBUG和INFO)输出前增加判断:
if (logger.isDebugEnabled) { logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i])); }
除了日志级别和日志消息,通常在日志中还会包含一些其他信息,比如日期、线程名、类信息、MDC变量等等,根据Takipi的测试,如果在日志中加入class,性能会急剧下降,比起LogBack的默认配置,吞吐量的降幅在6成左右。如果一定要打印类信息,可以考虑用类名来命名Logger。
在分布式系统中,一个请求可能会经过多个不同的子系统,这时***生成一个UUID附在请求中,每个子系统在打印日志时都将该UUID放在MDC里,便于后续查询相关的日志。《The Ultimate Guide: 5 Methods For Debugging Production Servers At Scale》一文中就如何在生产环境中进行调试给出了不少建议,当中好几条是关于日志的,这就是其中之一。另一条建议是记录下所有未被捕获的日志,其实抛出异常有开销,记录异常同样会带来一定的开销,主要原因是Throwable类的fillInStackTrace方法默认是同步的:
public synchronized native Throwable fillInStackTrace;一般使用logger.error都会打出异常的堆栈,如果对吞吐量有一定要求,在情况运行时可以考虑覆盖该方法,去掉synchronized native,直接返回实例本身。聊完日志内容,再来看看Appender。在Java中,说起IO操作大家都会想起NIO,到了JDK 7还有了AIO,至少都知道读写加个Buffer,日志也是如此,同步写的Appender在高并发大流量的系统里多少有些力不从心,这时就该使用在10线程并发下,输出200字符的日志,的吞吐量***能是FileAppender的3.7倍。在不丢失日志的情况下,同样使用AsyncAppender,队列长度对性能也会有一定影响。如果使用Log4J 2.x,那么除了有AsyncAppender,还可以考虑性能更高的异步Logger,由于底层用了Disruptor,没有锁的开销,性能更为惊人。根据Log4J 2.x的官方测试,同样使用Log4J 2.x:64线程下,异步Logger比异步Appender快12倍,比同步Logger快68倍。
同样是异步,不同的库之间也会有差异:
同等硬件环境下,Log4J 2.x全部使用异步Logger会比LogBack的AsyncAppender快12倍,比Log4J 1.x的异步Appender快19倍
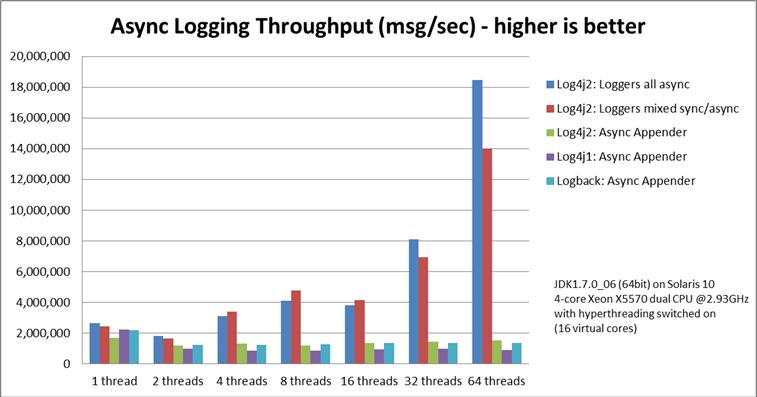
Logger性能强悍,但也有不同的声音,觉得这只是个看上去很优雅,只能当成一个玩具。关于这个问题,还是留给读者自己来思考吧。Appender,那么可以考虑使用STDOUT大部分生产系统都是集群部署,对于分布在不同服务器上的日志,用Logstash之类的工具收集就好了。很多时候还会在单机上部署多实例以便充分利用服务器资源,这时千万不要贪图日志监控或者日志查询方便,将多个实例的日志写到同一个日志文件中,虽然LogBack提供了prudent模式,能够让多个JVM往同一个文件里写日志,但此种方式对性能同样也有影响,大约会使性能降低10%。如果对同一个日志文件有大量的写需求,可以考虑拆分日志到不同的文件,做法之一是添加多个Appender,同时修改代码,不同的情况使用不同Logger;LogBack提供了SiftingAppender,可以直接根据MDC的内容拆分日志,Jetty的教程中就有根据host来拆分日志的范例,而根据Takipi的测试,SiftingAppender的性能会随着拆分文件数的增长一同提升,当拆分为4个文件时,10并发下SiftingAppenderFileAppender的3倍多。看了上面这么多的数据,不知您是否觉得自己的日志有不少改进的余地,您还没有把系统优化到***,亦或者您还有其他日志优化的方法,不妨分享给大家。