1. HDFS 简介
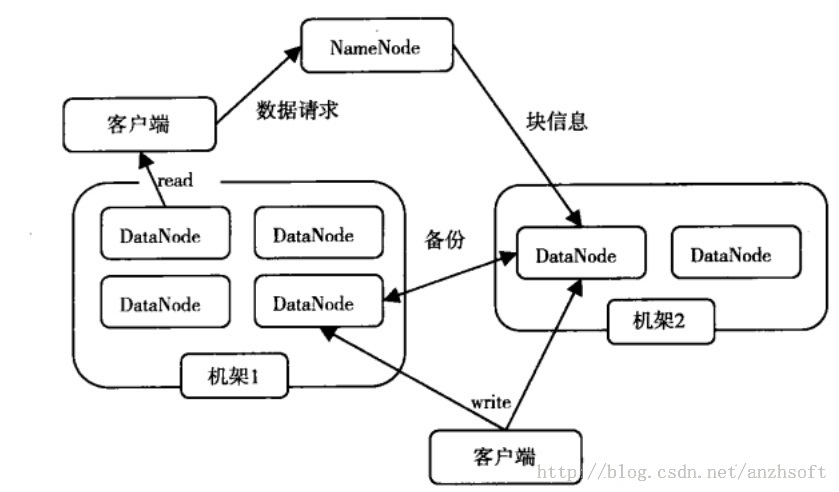
HDFS,为Hadoop这个分布式计算框架提供高性能、高可靠、高可扩展的存储服务。HDFS的系统架构是典型的主/从架构,早期的架构包括一个主节点NameNode和多个从节点DataNode。NameNode是整个文件系统的管理节点,也是HDFS中最复杂的一个实体,它维护着HDFS文件系统中最重要的两个关系:
HDFS文件系统中的文件目录树,以及文件的数据块索引,即每个文件对应的数据块列表。
数据块和数据节点的对应关系,即某一块数据块保存在哪些数据节点的信息。
其中,第一个关系即目录树、元数据和数据块的索引信息会持久化到物理存储中,实现是保存在命名空间的镜像fsimage和编辑日志edits中。而第二个关系是在NameNode启动后,有DataNode主动上报它所存储的数据块,动态建立对应关系。
在上述关系的基础上,NameNode管理着DataNode,通过接收DataNode的注册、心跳、数据块提交等信息的上报,并且在心跳中发送数据块复制、删除、恢复等指令;同时,NameNode还为客户端对文件系统目录树的操作和对文件数据读写、对HDFS系统进行管理提供支持。
DataNode提供真实文件数据的存储服务。它以数据块的方式在本地的Linux文件系统上保存了HDFS文件的内容,并且对外提供文件数据的访问功能。客户端在读写文件时,必须通过NameNode提供的信息,进一步和DataNode进行交互;同时,DataNode还必须接NameNode的管理,执行NameNode的指令,并且上报NameNode感兴趣的事件,以保证文件系统稳定,可靠,高效的运行。架构图如下:
在HDFS集群中NameNode存在单点故障(SPOF)。对于只有一个NameNode的集群,如果NameNode机器出现故障,那么整个集群将无法使用,直到NameNode重新启动。
NameNode主要在以下两个方面影响HDFS集群:
NameNode机器发生意外,比如宕机,集群将无法使用,直到管理员重启NameNode
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS的HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
2. HA基础
HDFS HA的解决方案可谓百花齐放,Linux HA, VMware FT, shared NAS+NFS, BookKeeper, QJM/Quorum Journal Manager, BackupNode等等。目前普遍采用的是shared NAS+NFS,因为简单易用,但是需要提供一个HA的共享存储设备。而社区已经把基于QJM/Quorum Journal Manager的方案merge到trunk了,clouderea提供的发行版中也包含了这个feature,这种方案也是社区在未来发行版中默认的 HA方案。
在HA具体实现方法不同的情况下,HA框架的流程是一致的。不一致的就是如何存储和管理日志。在Active NN和Standby NN之间要有个共享的存储日志的地方,Active NN把EditLog写到这个共享的存储日志的地方,Standby NN去读取日志然后执行,这样Active和Standby NN内存中的HDFS元数据保持着同步。一旦发生主从切换Standby NN可以尽快接管Active NN的工作(虽然要经历一小段时间让原来Standby追上原来的Active,但是时间很短)。
说到这个共享的存储日志的地方,目前采用最多的就是用共享存储NAS+NFS。缺点有:1)这个存储设备要求是HA的,不能down;2)主从切换时需要 fencing方法让原来的Active不再写EditLog,否则的话会发生brain-split,因为如果不阻止原来的Active停止向共享存储写EditLog,那么就有两个Active NN了,这样就会破坏HDFS的元数据了。对于防止brain-split问题,在QJM出现之前,常见的方法就是在发生主从切换的时候,把共享存储上存放EditLog的文件夹对原来的Active的写权限拿掉,那么就可以保证同时至多只有一个Active NN,防止了破坏HDFS元数据。
在Hadoop 2.0之前,也有若干技术试图解决单点故障的问题,我们在这里做个简短的总结
Secondary NameNode。它不是HA,它只是阶段性的合并edits和fsimage,以缩短集群启动的时间。当NameNode(以下简称NN)失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失。
Backup NameNode (HADOOP-4539)。它在内存中复制了NN的当前状态,算是Warm Standby,可也就仅限于此,并没有failover等。它同样是阶段性的做checkpoint,也无法保证数据完整性。
手动把name.dir指向NFS。这是安全的Cold Standby,可以保证元数据不丢失,但集群的恢复则完全靠手动。
Facebook AvatarNode。 Facebook有强大的运维做后盾,所以Avatarnode只是Hot Standby,并没有自动切换,当主NN失效的时候,需要管理员确认,然后手动把对外提供服务的虚拟IP映射到Standby NN,这样做的好处是确保不会发生脑裂的场景。其某些设计思想和Hadoop 2.0里的HA非常相似,从时间上来看,Hadoop 2.0应该是借鉴了Facebook的做法。
还有若干解决方案,基本都是依赖外部的HA机制,譬如DRBD,Linux HA,VMware的FT等等。
#p#
3. 具体实现
3.1 借助DRBD、HeartbeatHA实现主备切换。
使用DRBD实现两台物理机器之间块设备的同步,即通过网络实现Raid1,辅以Heartbeat HA实现两台机器动态角色切换,对外(DataNode、DFSClient)使用虚IP来统一配置。这种策略,可以很好地规避因为物理机器损坏造成的 hdfs元数据丢失,(这里的元数据简单地说,就是目录树,以及每个文件有哪些block组成以及它们之间的顺序),但block与机器位置的对应关系仅会存储在NameNode的内存中,需要DataNode定期向NameNode做block report来构建。因此,在数据量较大的情况下,blockMap的重建过程也需要等待一段时间,对服务会有一定的影响。

接着看一下什么是DRBD:Distributed Replicated Block Device是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。可以理解成一个基于网络的RAID-1。

在上述的示意图中有两个Server。每个Server含有一个Linux的内核,包含文件系统,buffer cache,硬盘管理和物理硬盘,TCP/IP的调用栈,NIC(network interface card)的驱动。
黑色的箭头代表在这些模块中的数据流动。橘色的箭头表示了从集群的active node到standby node的数据流动。
3.2 Facebook AvatarNode
DataNode同时向主备NN汇报block信息。这种方案以Facebook AvatarNode为代表。
PrimaryNN与StandbyNN之间通过NFS来共享FsEdits、FsImage文件,这样主备NN之间就拥有了一致的目录树和block信息;而block的位置信息,可以根据DN向两个NN上报的信息过程中构建起来。这样再辅以虚IP,可以较好达到主备NN快速热切的目的。但是显然,这里的NFS又引入了新的SPOF。
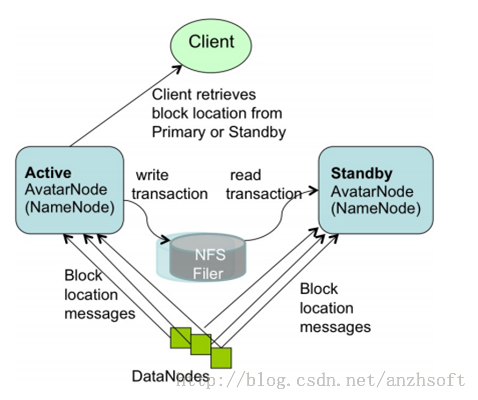
在主备NN共享元数据的过程中,也有方案通过主NN将FsEdits的内容通过与备NN建立的网络IO流,实时写入备NN,并且保证整个过程的原子性。这种方案,解决了NFS共享元数据引入的SPOF,但是主备NN之间的网络连接又会成为新的问题。
总结:在开源技术的推动下,针对HDFS NameNode的单点问题,技术发展经历以上阶段,虽然,在一定程度上缓解了hdfs的安全性和稳定性的问题,但仍然存在一定的问题。直到 hadoop2.0.*之后,Quorum Journal Manager给出了一种更好的解决思路和方案。
3.3 QJM/Qurom Journal Manager
Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案。QJM的结构图如下所示:

QJM的基本原理就是用2N+1台JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法的,可以参考http://en.wikipedia.org/wiki/Paxos_(computer_science)。
用QJM的方式来实现HA的主要好处有:1)不需要配置额外的高共享存储,这样对于基于commodityhardware的云计算数据中心来说,降低了复杂度和维护成本;2)不在需要单独配置fencing实现,因为QJM本身内置了fencing的功能;3)不存在Single Point Of Failure;4)系统鲁棒性的程度是可配置的(QJM基于Paxos算法,所以如果配置2N+1台JournalNode组成的集群,能容忍最多N台机器挂掉);5)QJM中存储日志的JournalNode不会因为其中一台的延迟而影响整体的延迟,而且也不会因为JournalNode的数量增多而影响性能(因为NN向JournalNode发送日志是并行的)。
#p#
4. HDFS Federation
单NN的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NN进程使用的内存可能会达到上百G,常用的估算公式为1G对应1 百万个块,按缺省块大小计算的话,大概是64T (这个估算比例是有比较大的富裕的,其实,即使是每个文件只有一个块,所有元数据信息也不会有1KB/block)。同时,所有的元数据信息的读取和操作都需要与NN进行通信,譬如客户端的addBlock、getBlockLocations,还有DataNode的blockRecieved、 sendHeartbeat、blockReport,在集群规模变大后,NN成为了性能的瓶颈。Hadoop 2.0里的HDFS Federation就是为了解决这两个问题而开发的。

(图片来源: HDFS-1052 设计文档
图片作者: Sanjay Radia, Suresh Srinivas)
这个图过于简明,许多设计上的考虑并不那么直观,我们稍微总结一下:
- 多个NN共用一个集群里DN上的存储资源,每个NN都可以单独对外提供服务
- 每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储
- DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况
- 如果需要在客户端方便的访问若干个NN上的资源,可以使用客户端挂载表,把不同的目录映射到不同的NN,但NN上必须存在相应的目录
这样设计的好处大致有:
- 改动最小,向前兼容
- 现有的NN无需任何配置改动.
- 如果现有的客户端只连某台NN的话,代码和配置也无需改动。
- 分离命名空间管理和块存储管理
- 提供良好扩展性的同时允许其他文件系统或应用直接使用块存储池
- 统一的块存储管理保证了资源利用率
- 可以只通过防火墙配置达到一定的文件访问隔离,而无需使用复杂的Kerberos认证
- 客户端挂载表
- 通过路径自动对应NN
- 使Federation的配置改动对应用透明
参考资料:
1. http://www.binospace.com/index.php/hdfs-ha-quorum-journal-manager/
2. http://www.binospace.com/index.php/hadoop0-23-0_3_hdfs_nn_snn_bn_ha/
3. http://www.sizeofvoid.net/hadoop-2-0-namenode-ha-federation-practice-zh/
4. http://www.blogjava.net/shenh062326/archive/2012/03/24/yuling111.html
5. http://blog.csdn.net/dangyifei/article/details/8920164
6. http://www.drbd.org/