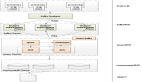
通过分析HBase的特点,提出了一种基于HBase的海量微博数据高效存储方案。该方案通过建立合适的数据存储模型、预建Region,提出行关键字生成规则和跳过坏记录的方法,使得数据能够利用MapReduce模型高效且不间断地导入HBase数据库。实验结果表明,该方法能够提高海量数据导入HBase的效率。
随着网络技术的快速发展,互联网用户激增,同时产生了海量的互联网数据。微博的使用人群数量基数大,状态信息更新频繁,信息传播迅速,这为研究网络用户行为与心理提供了充足的资源,也带来了挑战。
面对如此海量的微博数据,如何将其高效的存储与管理,已经成为一个迫切需要解决的问题。云计算技术的出现,为解决这一问题提供了新的途径和思路。目前谷歌、亚马逊、微软、IBM等知名企业纷纷推出云计算解决方案。Apache的Hadoop[1]是一个开源的云计算平台,其核心是HDFS、 MapReduce和Hbase。Hbase是一个开源的、面向列的分布式数据库,它是基于HDFS的,可以利用集群处理大数据。
目前已有105万个新浪微博用户以JSON[2]格式保存的文本数据,数据容量为8.9 TB。如此大量的数据使用单台计算机进行结构化存储和处理是极其耗费时间的。本文主要研究基于MapReduce模型解析JSON格式的微博数据,并将其高效地导入Hbase数据库,为海量数据的高效存储提供一种解决方案。
1 HBase概述和MapReduce模型
HBase[3]是一个基于HDFS的、开源的、面向列的分布式数据库。HBase是基于列簇存储的,不同的列簇对应HDFS上的不同的目录文件,此目录文件中存储的是HBase底层存储文件(HFile文件),当目录中HFile文件数量过多时,HBase会进行compact操作,合并HFile文件。HBase的每个表都有一个或几个列簇,每个列簇可以包含任意数量的列,且每行的列不必相同。HBase表中的每一行由行关键字、时间戳和列簇组成。
HBase有多种数据导入方式,最直接的方法是在MapReduce任务中用TableOutputFormat导入或者直接使用正常的客户端API导入。但是这些都不是***效的方法。BulkLoad可以通过MapReduce任务直接生成HFile文件,然后导入HBase的表中,适合大数据的快速导入。因此在本文中主要针对BulkLoad方法进行改进。
MapReduce[4]是一个处理数据的编程模型。它有两个重要的函数:Map和Reduce。这两个函数是顺序执行的,Map执行完毕后,开始执行reduce。Map负责分解任务,Reduce负责把各Map任务的结果汇总。
2 微博数据高效存储方案
2.1 微博数据的存储模型
HBase数据库存储微博用户的信息以及微博内容信息,数据库表设计如表1和表2所示。HBase有多种数据导入方式,最直接的方法是在 MapReduce任务中用TableQutputFormat导入或者直接使用正常的客户端API导入。但这些都不是***效的方法。 basic_info列簇存储微博用户的基本信息,statuses_id列簇存储微博的id,即表2中的行关键字,列名“statuses_id”指的是微博的id,用列名存储用户发布的所有微博信息,”user_id”也是如此。sina_relationship列簇用于存储微博用户关系。在表2 中,basic_info列簇用于存储常用的微博内容的基本信息,other_info列簇用于存储不常用的微博内容的信息,这样划分是考虑到HBase 是按列簇存储的,避免造成I/O浪费。text_info列簇存储的是微博的文本内容。

微博内容信息表中的basic_info:user_id和微博用户信息表中的statuses_id:“statuses_id”形成二级索引,用于关联两个表。
2.2 微博数据存储的优化
2.2.1 预创建Region
HBase在建表时,默认只有一个Region。当使用BulkLoad[5]导入数据时,当数据达到一定的规模(默认是256 MB,设置为200 GB)时,Region会被分割,这将严重影响导入性能。
因此可以预创建一定数量的空Region,至于Region的数量可以参考数据量、Region设定的容量和RegionServer的数量来决定。 Region的数量***是RegionServer的整数倍,这有利于HBase使用MapReduce进行数据处理。数据量除以预创建Region的数量应当小于Region的设定容量,这可以避免在数据导入时,Region进行split操作。
运行MapReduce程序生成的每个 HFile文件中的行关键字不属于独立的Region时,导入时会发生文件分割。通过实验得知,将总大小为115 GB的HFile文件导入到有32个Region的表中,耗时130 min,而且由于分割HFile文件的过程中会生成较多的临时文件,需要较大的额外存储空间。
为了解决这一问题,需要使得生成的每个HFile文件属于单个Region,因此需要制定行关键字生成规则。
2.2.2 行关键字生成规则
HBase按照行关键字的字典序来存储数据。Hbase提供了多种数据查询方式:根据行关键字调用get接口查询,调用scan查询,全表扫描等。
为了提高数据导入效率和查询效率,提出了行关键字的生成规则。为了满足HFile文件所属Region的唯一性,需要行关键字有Region识别的功能,因此行关键字中需要包含Region识别字段。为了保证查询效率,对于微博内容信息表,需要将同一个微博用户的微博在HBase中连续存储,这就要求行关键字中包含用户信息字段,以保证将所需微博聚集在一起。为了保证行关键字的唯一性,行关键字需要包含微博内容的关键字。式(1)是微博内容信息表的行关键字生成规则。式(2)是微博用户信息表的行关键字生成规则。
行关键字=Region识别字段+微博用户ID+微博内容ID(1)
行关键字=Region识别字段+微博用户ID(2)
2.2.3 跳过坏记录
由于下载的微博数据是JSON格式的,因此首先需要对微博数据进行解析,然后导入HBase数据库。由于数据量大,因此需要使用MapReduce编程模型来解析数据。
MapReduce需要所有的Map任务都结束后,才能进行接下来的工作。如果有一个Map任务执行多次(默认是4次)均失败,则整个 MapReduce任务失败,从而造成了时间和资源的浪费。例如,下载的微博数据中有损坏的,也有JSON格式不完整的,还有文件过大导致内存溢出的等,这都会导致MapReduce任务失败。
MapReduce有Skipipng mode,设置开启后,可以跳过坏记录,但是这种模式会大大影响效率,而且对于内存溢出错误无法处理,也不能对跳过坏记录的文件进行标记。
为了能够跳过程序运行过程中的错误,并将坏记录所在文件保存到指定文件目录中,提出重写RecordReader的方法,称之为SK-bad。由于将整个文件作为数据分片,可以在RecordReader中获得数据分片的文件名。然后获得任务ID,分析任务ID得出任务的执行次数,当执行次数达到一定数值时(此数值需要自己指定,且要小于任务失败***重复执行次数,否则不会起作用),将此文件移动到指定文件目录,与此同时将此记录标记为已处理,从而能够保证跳过任何原因引起的坏记录。核心程序代码如下。
- public class WholdeFileRecordReader
- extends RecordReader{
- ……
- public void initialize{InputSplit split,TaskAttempt Context context)}
- ……
- String[]strtaskid=
- context.getTaskAttemptid().tostring().trim().split(“_”)
- String reindex=
- straskid[strtaskid.length-1];
- if(integer.parseitn(reidex)>4){|
- ……
- }
- ……
- }
- }
#p#
3 实验
3.1 实验环境
利用6台计算机作为宿主机,其中有4台Dell OptiPlex 990,配置均为:CPU为Intel酷睿i3 2120,内存12 GB,千兆以太网卡。一台Dell T3500,配置为:CPU为Xeon W3565,内存24 GB,千兆以太网卡。一台浪潮NP3060,配置为:CPU为Xeon E5506,内存16 GB,集成双千兆网卡。每台宿主机均安装Xen虚拟机,每台Dell OptiPlex 990虚拟出3台虚拟机。Dell T3500虚拟出6台虚拟机,浪潮NP3060虚拟出4台虚拟机。总共有22台虚拟机,每台虚拟机的操作系统均为64 bit Centos 6.2。
每台虚拟机安装Hadoop 1.0.4和HBase 0.94.5,其中一台作为Master运行NameNode,JobTracker和Hmaster,一台运行SecondNamenode,其余20 台为Slaves运行DataNode,TaskTracker和RegionServer。
解析JSON数据使用的是第三方工具包Jackson[6]。
实验使用的数据是以文本文件保存的JSON格式的微博数据,每个文件大小在100 MB~180 MB之间,含有105万用户的信息。总的数据容量为8.9 TB。
3.2 实验结果及分析
使用10 000个微博数据文件,每2 000个文件作为一次测试中MapReduce任务的输入,共5次测试。用于测试MapReduce任务在使用SK-bad方法时任务失败次数,同时测试 MapReduce任务在未使用SK-bad方法时的失败次数和开启Skipping mode时的失败次数来进行比较。引起的原因有数据过大导致内存溢出、文件不完整、错误的JSON格式和文件校验码错误等。实验结果如表3所示,对于读取文件的过程中发生的错误,Skipping mode无法处理,5次测试的结果表明SK-bad方法能够保证MapReduce任务的顺利执行。
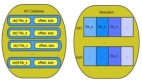
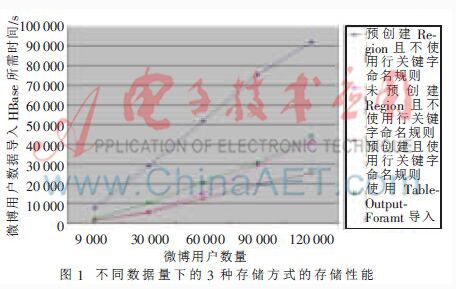
接下来的测试均使用SK-bad方法,Region***容量设置为200 GB,预创建Region数量为120个。分别测试在未预创建Region且不使用行关键字生成规则的情况下(情况一),预创建Region且不使用行关键字生成规则的情况下(情况二)和预创建Region且使用行关键字生成规则情况下(情况三)的存储性能。
实验结果如图1所示,存储9 000个用户的数据时,在情况一下,由于数据量较小,Region不会split,所以存储性能与情况三下的存储性能相近。在情况二下,MapReduce任务所生成的HFile文件不属于单个Region,且Region数量较多,因此HFile会进行多次split操作,这严重影响了存储性能。在存储30 000个用户的数据时影响性能的因素与存储9 000个用户的数据时相似;在存储60 000个用户的数据时,对于情况一,由于数据量较大会使Region做split操作,这严重影响存储性能;在存储90 000个用户的数据时影响性能的因素与存储60 000个用户的数据时相似;在存储120 000个用户的数据时,在情况一下,由于数据量较大会使Region再次做split操作,使得Region数量增多,这更加影响存储性能,并且随着用户数据的增多,Region数量也会增加,存储性能会随之降低。在情况三下,由于Region不需要做split操作,且生成的每个HFile属于唯一的 Region,因此随着数据量的增长,存储时间接近线性增长。
在预创建Region且使用行关键字生成规则的情况下,存储所有8.9 TB共1 068 090个微博用户的数据,耗时65 h 34 min。
本文通过分析HBase和MapReduce模型,提出了一种通过预创建Region、行关键字生成规则,利用MapReduce模型将微博数据高效导入HBase数据库的方案,并提出了能够处理各种运行错误的SK-bad方法。
未来要做的工作是优化MapReduce对HBase的访问效率,利用HBase数据库中的数据进行网络用户行为分析方面的研究。
参考文献
[1] Hadoop[EB/OL]. [2013-07-01]. http://hadoop.apa-che.org/.
[2] Introducing JSON[EB/OL]. [2005]. http://www.j-son.org/.
[3] HBase:Bigtable-like structured storage for Hadoop HDFS[EB/OL].[2012-08-24].http://wiki.apache.o-rg /hadoop/Hbase/.
[4] 李建江,崔健,王聃.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[5] GEORGE L. HBase: the definitive guide[M]. USA: O′Reilly Media, 2011.
[6] Jackson: High-performance JSON processor[EB/OL].[2013-04-30]. http://jackson.codehaus.org.