最近看到亚马逊***次单独公布AWS财报,一年营收57亿美元,市场份额占比***。混合云市场,2014年,IBM以综合的IT能力,收入70亿夺魁。云计算喊了这么多年,不知不觉已经变成了几十亿美元的大生意。云计算时代真的来了!
今天不是来说AWS的,说说大数据怎么上云的一些思考:
1、首先说说,大数据和云的关系,云是一种网络形态的概念,是继1980年代大型计算机到客户端-服务器的大转变之后的又一种巨变。云计算(Cloud Computing)是分布式计算(Distributed Computing)、并行计算(Parallel Computing)、效用计算(Utility Computing)、网络存储(Network Storage Technologies)、虚拟化(Virtualization)、负载均衡(Load Balance)、热备份冗余(High Available)等传统计算机和网络技术发展融合的产物。除了技术上的融合形态,更重要的体现了一种服务模式的一种融合和改变,对于云来说,大数据只是上面的一种服务,和其他的web服务,数据库服务没有区别。
2、I层(云的基础设施)现在业界最火的方案是OpenStack,OpenStack是一个由NASA(美国国家航空航天局)和Rackspace合作研发并发起的,以Apache许可证授权的自由软件和开放源代码项目。
OpenStack是一个开源的云计算管理平台项目,由几个主要的组件组合起来完成具体工作。OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。OpenStack通过各种互补的服务提供了基础设施即服务(IaaS)的解决方案,每个服务提供API以进行集成。
OpenStack云计算平台,帮助服务商和企业内部实现类似于 Amazon EC2 和 S3 的云基础架构服务(Infrastructure as a Service, IaaS)。OpenStack 包含两个主要模块:Nova 和 Swift,前者是 NASA 开发的虚拟服务器部署和业务计算模块;后者是 Rackspace开发的分布式云存储模块,两者可以一起用,也可以分开单独用。OpenStack除了有 Rackspace 和 NASA 的大力支持外,还有包括 Dell、Citrix、 Cisco、 Canonical等重量级公司的贡献和支持,发展速度非常快。
在云环境中,Openstack解决了I层的问题,所有物理资源的管理和分配由I层来负责。
3、正是因为I层将资源和存储进行了虚拟化然后对上提供,大数据上云***的两个问题是资源管理和数据存储。同时大数据又是重载的业务,对资源的需求非常高,因此需要大数据和openstack充分配合,大数据上云才能运行的好。
4、传统数据中心,大数据集群的资源管理和分配目前主要的方案是mesos/YARN.
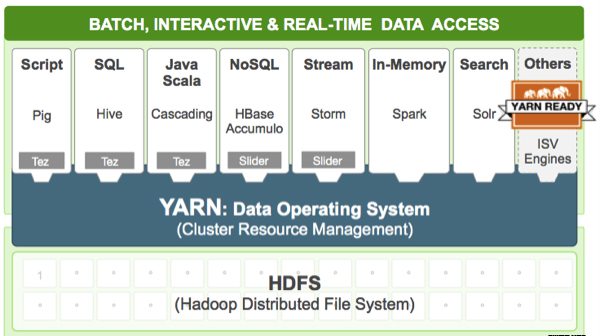
从上图大家可以看出,Mesos/YARN来对物理资源直接进行管理,然后分配给上层的组件使用。 资源隔离方面,docker方案发展很快,所以又有YARN和kubernets结合的方案。PaaS作为一个服务直接架在YARN上。在没有直接I层能力的情况下,应该是非常合适的一种的过渡方案,但是如果YARN管理的不是直接的物理资源,而是I层虚拟出来的VM/docker之类,mesos/YARN和I层的能力就出现了一定的重合和冲突,这个时候mesos/YARN应该把VM/Docker级资源管理和分配的能力释放给I层,聚焦于job级资源的分配和调度。此时PaaS在架构在YARN/MESOS上就非常多余。
5、对于存储存在同样的问题,HDFS是对物理硬盘的直接抽象成对象存储,并提供3份冗余来保障数据的可靠性。云上的I层对存储通常也会抽象,并且进行一定的冗余,来动态分配给上层应用。HDFS直接架在I层上,就存在反复冗余的问题。同时大数据的核心是对数据的处理,数据存储的位置对性能起到非常关键的作用,多层反复虚拟化之后,数据存储的不确定性,性能损耗非常大。因此I层***将物理硬盘直接提供出来给大数据服务可见,让用数据的人直接管理数据效率***。