CoreOS和自动化运维
CoreOS是一个基于Docker的轻量级容器化Linux发行版,专为大型数据中心而设计旨在通过轻量的系统架构和灵活的应用程序部署能力简化数据中心的维护成本和复杂度。CoreOS作为Docker生态圈中的重要一员,日益得到各大云服务商的重视,目前已经完成了A轮融资,发展风头正劲, 一流的云服务商都会提供对 CoreOS 的支持。
作为国内最专业的OpenStack云服务商UnitedStack的一名运维工程师,我会更多地从运维的角度来看待这个操作系统。我认为,作为一个工程师来说,理性看待一项技术非常重要。

判断一个服务器操作系统优秀与否,我会首先看以下方面:
1. 操作系统的服务管理
服务管理对于一个操作系统来说非常重要,因为我们生产环境的操作系统是要跑服务的,服务管理的效率直接影响了运维的效率。
CoreOS使用了Systemd来管理机器级别的服务,Systemd是一个功能极其强大的工具,别的不多说,直接上图,配置从冗长的Shell脚本换成了配置文件式的定义。
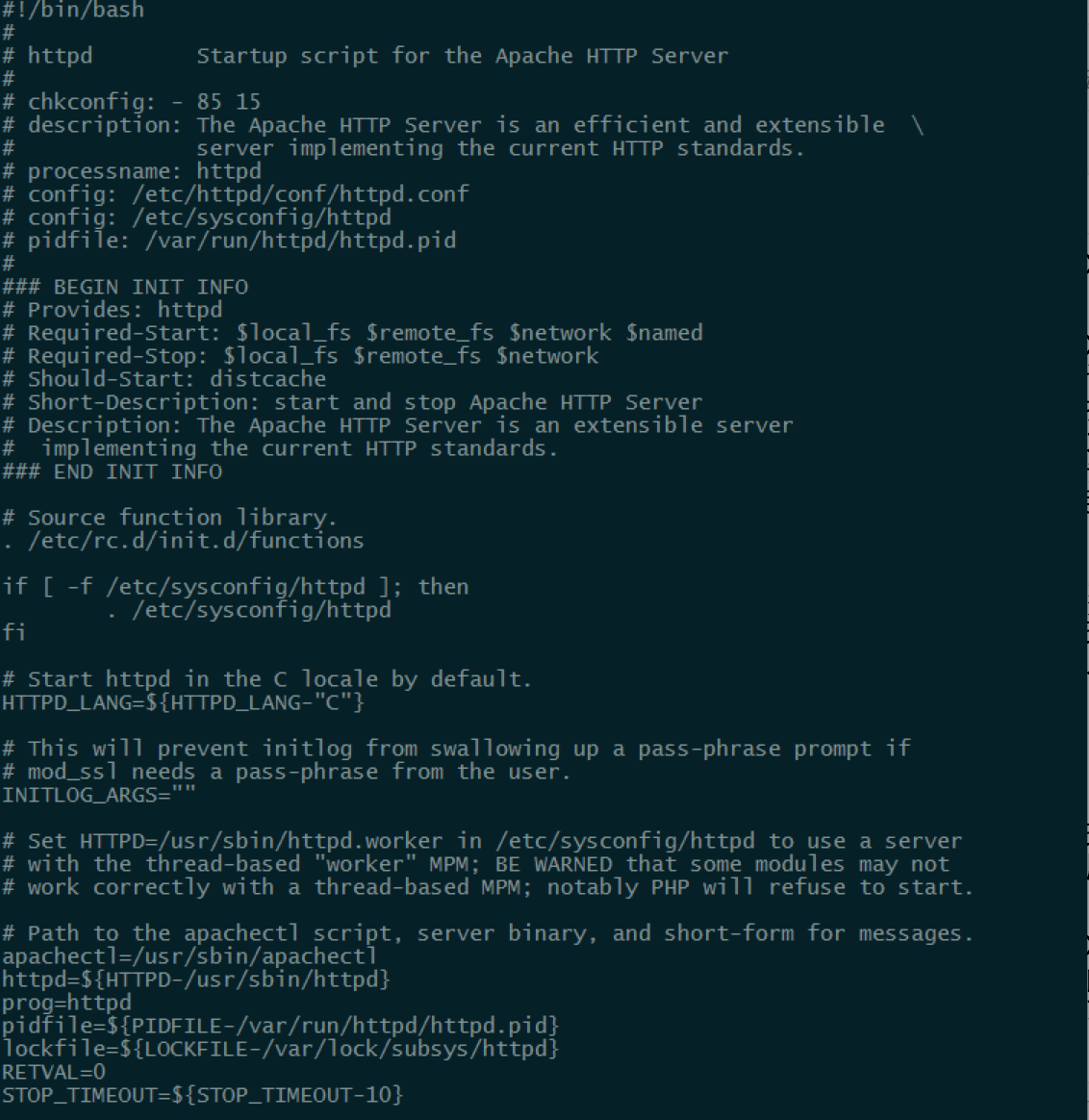
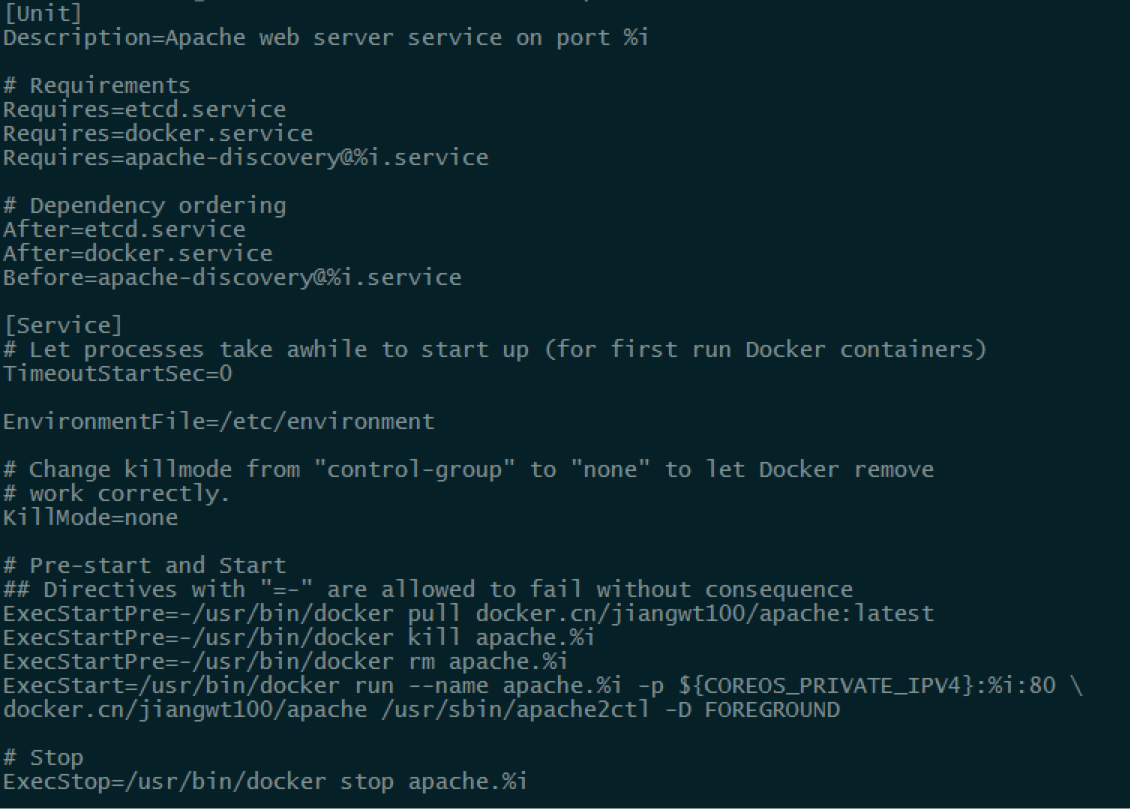
状态所示的内容也比用Sysv的系统丰富了很多(注:上半部分是Sysv的服务管理,下半部分是Systemd的服务管理)
在以前的操作系统上,只有对机器级别服务的管理,没有对集群级别的服务管理。对集群级别的服务管理需要借助第三方工具,比如Puppet和Zabbix。而CoreOS采用了Fleet和Etcd,Fleet用于集群服务管理,etcd用于提供集群服务状态的一致性存储,这无疑是加分项。
2. 操作系统的包管理
当我们运维大量服务器的时候,包管理非常重要,因为软件包的管理直接影响了部署,一个方便的包管理会给运维省掉不少事,不用总是让运维打包,运维会感谢你的。
关于包管理,我的几个看法是:
没有包管理就是最好的包管理,相信运维们都被在不同操作系统上打包需要学习多套包管理折磨过。
利用Docker Image打包最大的好处在于隔离的Runtime和文件系统,各个服务之间不容易出现依赖兼容性不一致的情况。
打成Docker Image开发自己就可以完成,如同Git式的镜像管理符合开发人员的思维。
3. 操作系统采用的内核
每一个公司都会都会选用不同合适的内核,越稳定的内核越不会出问题,越新的内核支持的特性就越多,所以选择合适的内核非常重要。
CoreOS使用了几乎是最新的稳定版的内核,拥有了最多的Feature,在内核的稳定性上我持保留意见。
4. 操作系统的安全机制
如果你运维的服务器半夜被入侵一次你就知道安全是多么重要了。
- CoreOS的安全机制包括:
- 自动更新:自动更新修复漏洞一直是运维工程师安全法宝之一,CoreOS自动更新增加了不少便利。
- usr 目录只有制度权限,用户无法写数据到系统目录下,这意味着封掉了后门的程序的可乘之机。
- Docker的默认Iptables设置省去运维工程师的Iptables配置工作。
- CoreOS提供的Fleet是一个集群服务管理工具,这改变了我们管理服务的方式:
- 它在机器和服务之间构建一个虚拟化层,把服务按照用户要求调度到不同的机器上。
- 通过ETCD,Fleet可以完成对服务健康状态的管理和监控并且根据这些状态来调度服务。
采用了Systemd作为机器层面的服务管理工具,借助Systemd的Unit配置文件,Fleet可以完成集群层面的服务脚本编写。
Fleet提供了容灾机制,当集群中有Worker因为某些原因挂掉,Fleet会把该Worker上的容器调度到其他可以被调度的Worker上。
从运维角度来看,Fleet是一个相当优秀的集群服务管理工具。容灾机制,集群状态管理,Systemd是它的亮点。
写在最后的话
如果读者想试一下CoreOS,可以利用API和Userdata在UOS上创建一个CoreOS集群把玩一下,试一下CoreOS集群的灾备机制,之后的文章会写相关的实验内容。我会把CoreOS和自动化运维的专题放到下一篇文章里去。谢谢。