













机器生成的日志数据对于查找各种硬件和软件故障的根源至关重要。来自该日志数据的信息可提供改进系统架构、减缓系统退化和改善正常运行时间方面的反馈。最近,一些企业开始使用这些日志数据获取业务洞察。在使用一个容错的架构时,Flume 是一个拥有高效收集、聚合和转移大量日志数据的分布式服务。本文将介绍如何部署 Flume,以及如何将它与 Hadoop 集群和简单的分布式 Web 服务结合使用。
Flume 架构
Flume 是一项分布式、可靠的、容易使用的服务,用于收集、聚合从许多来源传来的大量流事件数据并将它们转移到一个中央数据存储中。
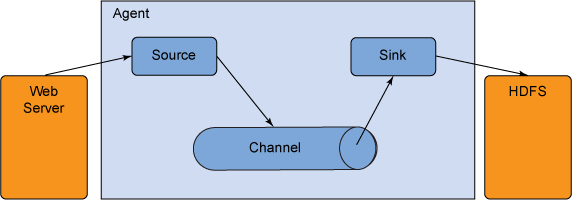
图 1. Flume 架构
Flume 事件可定义为一个拥有工作负载(字节)和一个可选的字符串属性集的数据流单元。Flume 代理是一个托管组件的 JVM 进程,事件通过该进程从外部来源流到下一个目标(跃点)。
InfoSphere® BigInsights™ 支持以较低的延迟持续分析和存储流数据。InfoSphere Streams 可用于配置上述代理和收集器进程(参见 参考资料)。Flume 也可用于在一个远程位置收集数据,而且可在 InfoSphere BigInsights 服务器上配置一个收集器,将数据存储在分布式文件系统 (DFS) 上。但是,在本文中,我们会同时将 Flume 用作代理和收集器进程,并使用一个 Hadoop 分布式文件系统 (HDFS) 集群作为存储。
数据流模型
一个 Flume 代理有三个主要组成部分:来源、通道和接收器 (sink)。来源 使用了外部来源(比如 Web 服务)传送给它的事件。外部来源以一种可识别的格式将事件发送给 Flume。当 Flume 来源收到事件后,它会将这些事件存储在一个或多个通道 中。通道是一种被动存储,它将事件保留到被 Flume 接收器 使用为止。例如,一个文件通道使用了本地文件系统;接收器从通道提取事件,并将它放在一个外部存储库(比如 HDFS)中,或者将它转发到流中下一个 Flume 代理(下一个跃点)的 Flume 来源;给定代理中的来源和接收器与暂存在通道中的事件同步运行。
来源可针对不同的用途而使用不同的格式。例如,Avro Flume 来源可用于从 Avro 客户端接收 Avro 事件。Avro 来源形成了一半的 Flume 的分层集合支持。在内部,这个来源使用了 Avro 的 NettyTransceiver 监听和处理事件。它可与内置 AvroSink 配套使用,共同创建分层集合拓扑结构。Flume 使用的其他流行的网络流包括 Thrift、Syslog 和 Netcat。
Avro
Apache 的 Avro 是一种数字序列化格式。它是一个基于 RPC 的框架,被 Apache 项目(比如 Flume 和 Hadoop)广泛用于数据存储和通信。Avro 框架的用途是提供丰富的数据结构、一种紧凑而又快速的二进制数据格式,以及与动态语言(比如 C++、Java™、Perl 和 Python)的简单集成。Avro 使用 JSON 作为其接口描述语言 (Interface Description Language, IDL),以指定数据类型和协议。
Avro 依赖于一种与数据存储在一起的模式。因为没有每个值的开销,这实现了轻松而又快速的序列化。在远程过程调用 (RPC) 期间,该模式会在客户端-服务器握手期间交换。使用 Avro,字段之间的通信很容易得到解决,因为它使用了 JSON。
可靠性、可恢复性和多跃点流
Flume 使用一种事务型设计来确保事件交付的可靠性。事务型设计相当于将每个事件当作一个事务来对待,事件暂存在每个代理上的一个通道中。每个事件传送到流中的下一个代理(比如来源栏)或终端存储库(比如 HDFS)。事件被存储在下一个代理的通道中或终端存储库中后,就会从上一个通道中删除,以便在收到存储确认之前维护一个最新事件队列。这个过程通过来源和接收器完成,它们将存储或检索信息封装在通道提供的一个事务中。这可以确保为 Flume 中的单跃点消息传送语义提供了端到端的流可靠性。
可恢复性通过通道中的暂存事件来维护,用于管理故障恢复。 Flume 支持一种受本地文件系统支持的持久性的文件通道(基本上用于在永久存储上维护状态)。如果使用一个持久性的文件通道,任何丢失的事件(在发生崩溃或系统故障时)都可以恢复。还有一个内存通道将事件存储在内存中的一个队列中,这么做更快,但在事件进程结束时,仍留在内存通道内的所有事件都无法恢复。
Flume 还允许用户构建多跃点流,事件会经历多个代理,然后才会到达最终的目标。对于多跃点流,来自上一个跃点的接收器和来自下一个跃点的来源都会运行自己的事务进程,以确保数据安全地存储在下一个跃点的通道中。
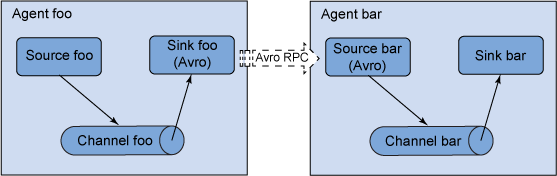
图 2. 多跃点流
#p#
系统架构
本节将讨论如何使用 Flume 设置一个可扩展的 Web 服务。出于此目的,我们需要使用代码来读取 RSS 提要。我们还需要配置 Flume 代理和收集器来接收 RSS 数据,并将它们存储在 HDFS 中。
Flume 代理配置存储在一个本地配置文件中。这类似于一个 Java 属性文件,并且被存储为一个文本文件。可在同一个配置文件中指定一个或多个代理的配置。配置文件包含一个代理中每个来源、接收器和通道的属性,以及它们如何连接在一起来形成数据流。
Avro 来源需要一个主机名(IP 地址)和端口号来接收数据。内存通道可能拥有最大队列大小(容量)限制,HDFS 接收器需要知道文件系统 URI 和路径才能创建文件。Avro 接收器可以是一个转发接收器 (avro-forward-sink),它可以转发到下一个 Flume 代理。
我们的想法是创建一个微型的 Flume 分布式提要(日志事件)收集系统。我们将使用代理作为节点,它们从一个 RSS 提要阅读器获取数据(在本例中为 RSS 体验)。这些代理将这些提要传递到一个收集器节点,后者负责将这些提要存储到一个 HDFS 集群中。在本例中,我们将使用两个 Flume 代理节点,一个 Flume 收集器节点和一个包含三个节点的 HDFS 集群。表 1 描述了代理和收集器节点的来源和接收器。

表 1. 代理和收集器节点的来源和接收器
图 3 给出了我们的多跃点系统的架构概述,该系统包含两个代理节点、一个收集器节点和一个 HDFS 集群。RSS Web 提要(参见下面的代码)是两个代理的 Avro 来源,它将提要存储在一个内存通道中。当提要在两个代理的内存通道中积累时,Avro 接收器开始将这些事件发送到收集器节点的 Avro 来源。收集器还使用一个内存通道和一个 HDFS 接收器将这些提要转储到 HDFS 集群中。参见下图,了解代理和收集器配置。
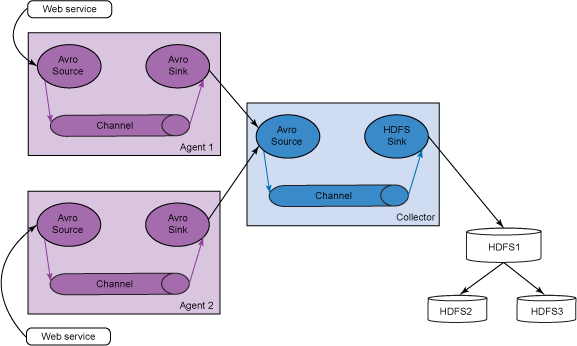
图 3. 多跃点系统的架构概述
让我们来看一下如何使用 Flume 启动一个简单的新闻阅读器服务。以下 Java 代码描述了一个从 BBC 读取 RSS Web 来源的 RSS 阅读器。您可能已经知道,RSS 是一个 Web 提要格式系列,用于以一种标准化格式发布频繁更新的网站,比如博客文章、新闻提要、音频和视频 。RSS 使用一种发布-订阅模型来定期检查订阅的提要中的更新。
#p#
下面的 Java 代码使用 Java 的 Net 和 Javax XML API 读取 W3C 文档中一个 URL 来源的内容,处理该信息,然后将该信息写入到 Flume 通道中。
清单 1. Java 代码 (RSSReader.java)
- import java.net.URL;
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import org.w3c.dom.CharacterData;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
- public class RSSReader {
- private static RSSReader instance = null;
- private RSSReader() {
- }
- public static RSSReader getInstance() {
- if(instance == null) {
- instance = new RSSReader();
- }
- return instance;
- }
- public void writeNews() {
- try {
- DocumentBuilder builder = DocumentBuilderFactory.newInstance().
- newDocumentBuilder();
- URL u = new URL("http://feeds.bbci.co.uk/news/world/rss.xml
- ?edition=uk#");
- Document doc = builder.parse(u.openStream());
- NodeList nodes = doc.getElementsByTagName("item");
- for(int i=0;i
- Element element = (Element)nodes.item(i);
- System.out.println("Title: " + getElementValue(element,"title"));
- System.out.println("Link: " + getElementValue(element,"link"));
- System.out.println("Publish Date: " + getElementValue(element,"pubDate"));
- System.out.println("author: " + getElementValue(element,"dc:creator"));
- System.out.println("comments: " + getElementValue(element,"wfw:comment"));
- System.out.println("description: " + getElementValue(element,"description"));
- System.out.println();
- }
- } catch(Exception ex) {
- ex.printStackTrace();
- }
- }
- private String getCharacterDataFromElement(Element e) {
- try {
- Node child = e.getFirstChild();
- if(child instanceof CharacterData) {
- CharacterData cd = (CharacterData) child;
- return cd.getData();
- }
- } catch(Exception ex) {
- }
- return "";
- }
- protected float getFloat(String value) {
- if(value != null && !value.equals("")) {
- return Float.parseFloat(value);
- }
- return 0;
- }
- protected String getElementValue(Element parent,String label) {
- return getCharacterDataFromElement((Element)parent.getElements
- ByTagName(label).item(0));
- }
- public static void main(String[] args) {
- RSSReader reader = RSSReader.getInstance();
- reader.writeNews();
- }
- }
下面的代码清单给出了两个代理(10.0.0.1 和 10.0.0.2)和一个收集器 (10.0.0.3) 的样例配置文件。这些配置文件定义了来源、通道和接收器的语义。对于每种来源类型,我们还需要定义类型、命令、标准错误行为和故障选项。对于每个通道,我们需要定义通道类型。还必须定义容量(通道中存储的最大事件数)和事务容量(对于每个事务,通道将从一个来源获取或提供给一个接收器的最大事件数)。类似地,对于每种接收器类型,我们需要定义类型、主机名(事件接收者的 IP 地址)和端口。对于 HDFS 接收器,我们提供了到达 HDFS 标头名称节点的目录路径。
清单 2 显示了示例配置文件 10.0.0.1.
清单 2. 代理 1 配置(10.0.0.1 上的 flume-conf.properties)
- # The configuration file needs to define the sources,
- # the channels and the sinks.
- # Sources, channels and sinks are defined per agent,
- # in this case called 'agent'
- agent.sources = reader
- agent.channels = memoryChannel
- agent.sinks = avro-forward-sink
- # For each one of the sources, the type is defined
- agent.sources.reader.type = exec
- agent.sources.reader.command = tail -f /var/log/flume-ng/source.txt
- # stderr is simply discarded, unless logStdErr=true
- # If the process exits for any reason, the source also exits and will produce no
- # further data.
- agent.sources.reader.logStdErr = true
- agent.sources.reader.restart = true
- # The channel can be defined as follows.
- agent.sources.reader.channels = memoryChannel
- # Each sink's type must be defined
- agent.sinks.avro-forward-sink.type = avro
- agent.sinks.avro-forward-sink.hostname = 10.0.0.3
- agent.sinks.avro-forward-sink.port = 60000
- #Specify the channel the sink should use
- agent.sinks.avro-forward-sink.channel = memoryChannel
- # Each channel's type is defined.
- agent.channels.memoryChannel.type = memory
- # Other config values specific to each type of channel(sink or source)
- # can be defined as well
- # In this case, it specifies the capacity of the memory channel
- agent.channels.memoryChannel.capacity = 10000
- agent.channels.memoryChannel.transactionCapacity = 100
清单 3 显示了示例配置文件 10.0.0.2。
清单 3. 代理 2 配置(10.0.0.2 上的 flume-conf.properties)
- agent.sources = reader
- agent.channels = memoryChannel
- agent.sinks = avro-forward-sink
- # For each one of the sources, the type is defined
- agent.sources.reader.type = exec
- agent.sources.reader.command = tail -f /var/log/flume-ng/source.txt
- # stderr is simply discarded, unless logStdErr=true
- # If the process exits for any reason, the source also exits and will produce
- # no further data.
- agent.sources.reader.logStdErr = true
- agent.sources.reader.restart = true
- # The channel can be defined as follows.
- agent.sources.reader.channels = memoryChannel
- # Each sink's type must be defined
- agent.sinks.avro-forward-sink.type = avro
- agent.sinks.avro-forward-sink.hostname = 10.0.0.3
- agent.sinks.avro-forward-sink.port = 60000
- #Specify the channel the sink should use
- agent.sinks.avro-forward-sink.channel = memoryChannel
- # Each channel's type is defined.
- agent.channels.memoryChannel.type = memory
- # Other config values specific to each type of channel(sink or source)
- # can be defined as well
- # In this case, it specifies the capacity of the memory channel
- agent.channels.memoryChannel.capacity = 10000
- agent.channels.memoryChannel.transactionCapacity = 100
清单 4 显示了收集器配置文件 10.0.0.3。
清单 4. 收集器配置(10.0.0.3 上的 flume-conf.properties)
- Collector configuration (flume-conf.properties on 10.0.0.3):
- # The configuration file needs to define the sources,
- # the channels and the sinks.
- # Sources, channels and sinks are defined per agent,
- # in this case called 'agent'
- agent.sources = avro-collection-source
- agent.channels = memoryChannel
- agent.sinks = hdfs-sink
- # For each one of the sources, the type is defined
- agent.sources.avro-collection-source.type = avro
- agent.sources.avro-collection-source.bind = 10.0.0.3
- agent.sources.avro-collection-source.port = 60000
- # The channel can be defined as follows.
- agent.sources.avro-collection-source.channels = memoryChannel
- # Each sink's type must be defined
- agent.sinks.hdfs-sink.type = hdfs
- agent.sinks.hdfs-sink.hdfs.path = hdfs://10.0.10.1:8020/flume
- #Specify the channel the sink should use
- agent.sinks.hdfs-sink.channel = memoryChannel
- # Each channel's type is defined.
- agent.channels.memoryChannel.type = memory
- # Other config values specific to each type of channel(sink or source)
- # can be defined as well
- # In this case, it specifies the capacity of the memory channel
- agent.channels.memoryChannel.capacity = 10000
#p#
后续步骤
现在我们已拥有读取 RSS 提要的代码,并知道如何配置 Flume 代理和收集器,我们可通过三个步骤设置整个系统。
步骤 1
编译的 Java 代码应作为一个后台进程执行,以保持运行。
清单 5. 编译的 Java 代码
- $ javac RSSReader.java
- $ java -cp /root/RSSReader RSSReader > /var/log/flume-ng/source.txt &
步骤 2
想启动代理之前,您需要使用 $FLUME_HOME/conf/ 目录下提供的模板来修改配置文件。在修改配置文件后,可使用以下命令启动代理。
清单 6 显示了启动节点 1 上的代理的命令。
清单 6. 启动节点 1 上的代理
- Agent node 1 (on 10.0.0.1):
- $ $FLUME_HOME/bin/flume-ng agent -n agent1 -c conf -f
- $FLUME_HOME/conf/flume-conf.properties
清单 7 显示了启动节点 2 上的代理的命令。
清单 7. 启动节点 2 上的代理
- Agent node 2 (on 10.0.0.2):
- $ $FLUME_HOME/bin/flume-ng agent -n agent2 -c conf -f
- $FLUME_HOME/conf/flume-conf.properties
在这里,$FLUME_HOME 被定义为一个环境变量(bash 或 .bashrc),它指向 Flume 的主目录(例如 /home/user/flume-1.4/)。
步骤 3
清单 8 启动收集器。值得注意的是,配置文件负责节点的行为方式,比如它是代理还是收集器。
清单 8. 收集器节点(10.0.0.3 上)
- $ $FLUME_HOME/bin/flume-ng agent -n collector -c conf -f
- $FLUME_HOME/conf/flume-conf.properties
结束语
在本文中,我们介绍了 Flume,一个用于高效收集大量日志数据的、分布式的、可靠的服务。我们介绍了如何根据需要使用 Flume 来部署单跃点和多跃点流。我们还介绍了一个部署多跃点新闻聚合器 Web 服务的详细示例。在该示例中,我们使用了 Avro 代理读取 RSS 提要,并使用一个 HDFS 收集器存储新闻提要。Flume 可用于构建可扩展的分布式系统来收集大量数据流。
















