












|
本博文出自51CTO博客谌玺博主,有任何问题请进入博主页面互动讨论! |
演示目标:
1 动态路由协议在某种程度上可以帮助HSRP收敛无跟踪的盲点
2 动态路由协议RIP可能引发HSRP收敛的问题
3 为什么同一子网的主机,有些收敛快,有些慢?
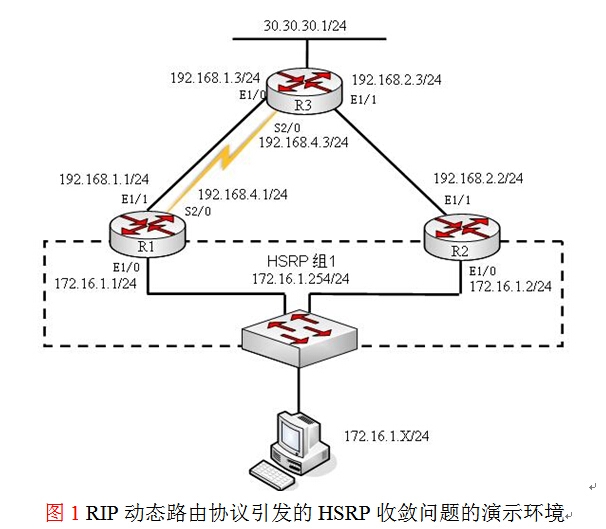
演示环境:如图1所示的环境
背景说明:从实践的角度来讲,在需要部署HSRP进行三层冗余的环境中,通常物理链路也是成环的,那么这种环境中,进行网络设计时需要特别注意动态路由协议的选择,以及评估和预测可能引发的各种收敛问题,明确到底是HSRP在为用户网络在实现冗余,还是三层的动态路由协议在为用户实现冗余,如果发生收敛问题,比如:收敛慢,是什么原因导致问题的发生,以及如何对这些问题进行修复。
 #p#
#p#
演示步骤:
***步:在如图1所示的网络环境中为所有的三层设备启动RIPv2的动态路由协议,具体配置如下所示,确保各个路由器的动态路由学习正常,这是整个演示环境的基础保障。
路由器R1的RIP配置:
R1(config)#routerrip
R1(config-router)#noauto-summary
R1(config-router)#version2
R1(config-router)#network 192.168.1.0
R1(config-router)#network 192.168.4.0
R1(config-router)#network 172.16.0.0
R1(config-router)#exit
路由器R2的RIP配置:
R2(config)#routerrip
R2(config-router)#version2
R2(config-router)#noauto-summary
R2(config-router)#network 192.168.2.0
R2(config-router)#network 172.16.0.0
R2(config-router)#exit
路由器R3的RIP配置:
R3(config)#routerrip
R3(config-router)#version2
R3(config-router)#noauto-summary
R3(config-router)#network 192.168.1.0
R3(config-router)#network 192.168.4.0
R3(config-router)#network 192.168.2.0
R3(config-router)#network 30.30.30.0
R3(config-router)#exit
完成上述配置后路由器R1的路由器表如图2所示。

注意:在R1的路由表中有一条暂时没有显示,被隐藏的到 30.30.30.0的RIP路由,这条路由器R1通过下一跳是R2的172.16.1.2来到达30.30.30.0的路由,它为什么会被隐藏,因为RIP以跳数来评估路由的度量,通过192.168.4.3和192.168.1.3是1跳,而经过R2的172.16.1.2来到达30.30.30.0的路由是2跳,所以它暂时被隐藏,那么在一种情况下该路由器会出现,那就是下一跳192.168.4.3和192.168.1.3这两条路由失效时,到此为后面的问题做出了预设。
现在将路由器R1和R2的E1/0接口规划到HSRP热容组1,虚拟IP地址是172.16.1.254,要求R1为活动路由器,并配置两台路由器的抢占功能,具体配置如下所示:
注意:暂时不去配置任何接口跟踪!
路由器R1的HSRP配置:
interface Ethernet1/0
ipaddress 172.16.1.1 255.255.255.0
standby1 ip 172.16.1.254 * 配置HSRP的虚拟IP地址
standby 1 priority 110 * 配置优先级为110,确保R1成HSRP组中的活动路由器
standby 1 preempt * 配置抢占功能
路由器R2的HSRP配置:
interface Ethernet1/0
ipaddress 172.16.1.2 255.255.255.0
standby 1 ip 172.16.1.254
standby 1 preempt
为什么不为R2配置优先级?
默认优先级为100,为了确保能让R1(优先级110)成为活动路由器,所以没必要去配置R2的优先级,使用保持默认的100。
提出一个问题:现在到***步的配置为止,如果路由器的S2/0和E1/1端口出现故障,请问HSRP的活动路由器是否会从R1切换到R2,流量是否会被R2所接管,在主机上能否成功的ping通30.30.30.1?#p#
第二步:在路由器R1上制造故障去shutdown路由器R1的S2/0和E1/1接口
R1(config)#intes2/0
R1(config-if)#shutdown *关闭S2/0
R1(config-if)#exit
R1(config)#intee1/1
R1(config-if)#shutdown *关闭E1/1
R1(config-if)#exit
系统提示:两个接口的管理属性为down!
*Jul 24 11:24:11.047: %LINK-5-CHANGED: InterfaceSerial2/0, changed state to administratively down
*Jul 24 11:24:11.055: %LINEPROTO-5-UPDOWN: Lineprotocol on Interface Serial2/0, changed state to down
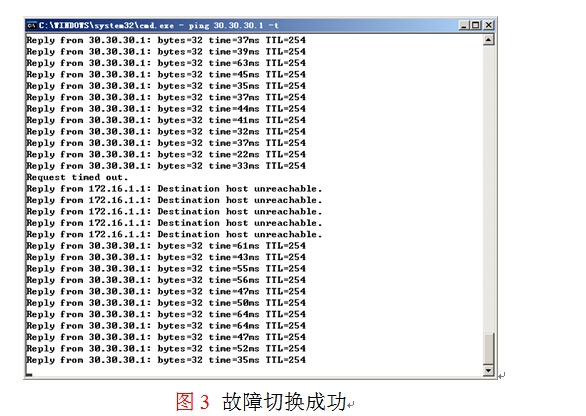
当路由器R1的S2/0和E1/1故障后,如图3所示,故障成功被切换,中间存在几个丢包是因为切换故障的延迟所致,但是HSRP冗余组中的活动路由器还是R1,备份路由器是R2,事实上,HSRP的角色状态并没有改变,而是路由协议来帮助用户完成了故障转移,并非HSRP的功劳。
具体分析如下:
首先在***步之后,可以在R1上通过show standby brief查看HSRP的信息,如图4所示,可看出,R1仍然是活动路由器,即便是R1的S2/0和E1/1关闭,但是由于HSRP并没有配置track跟踪接口功能,所以关闭接口的行为不会造成HSRP的角色转换。那么此时的流量是如何被R2接管?那是因为RIP动态路由协议帮助用户网络收敛。

在R1上通过show ip route指令查看路由表,如图5所示,由于R1的S2/0和E1/1故障,所以通过这两条链路的路由会随故障的发生而收敛,消失在R1的路由表中,此时,具备2跳度量值的哪条路由(通过R2到30.30.30.1)会出现在路由表中,那么R1就可以将主机发来的流量转向投递到R2,然后由R2发送到R3上的30.30.30.1,具体的证据如图6所示,如果用户在主机上跟踪到30.30.30.1的路径,不难看出,主机首先仍然将流量转发给活动路由器R1,然后R1再转发给R2,R2***转给目标。

路由协议去替代HSRP接管故障,切换流量的好处是网络可以依赖于动态路由协议的收敛来完成故障转移,其实这也是各大厂商推荐的一种方案,不足之处就是不同的动态路由协议的收敛速度不同,可能会为网络造成更大的收敛延迟,关于这一点后面会有实验来证明;另外它对于HSRP的初学者而言,可能造成对技术知道点的混淆,比如:没有配置跟踪track功能,也能收敛那么跟踪功能还有什么意义。#p#
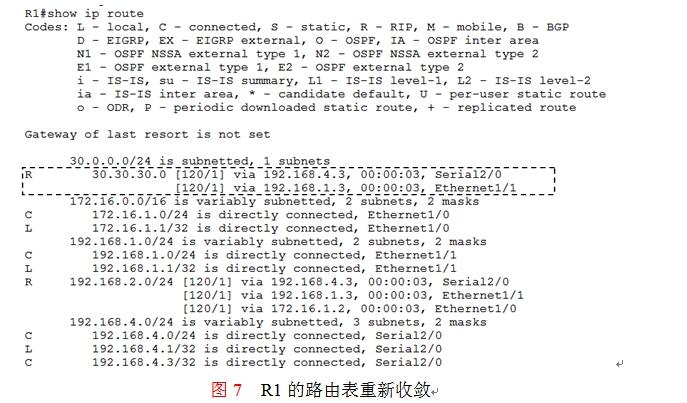
第三步:如果此时不让路由器R1的E1/0接口从R2学30.30.30.0的路由,那么动态路由协议RIP将无法替代HSRP帮助用户去接管故障。先恢复在R1上切断的两个接口,等待RIP再次收敛,还原到如图7所示。
为了阻止RIP通过R2去替代HSRP的故障接管,在路由器R1上使用路由过滤列表来阻止路由器R1从连接R2的E1/0接口学习到30.30.30.0的路由,具体配置如下:
在路由器R1上配置路由过滤列表:
R1(config)#access-list 1 deny 30.30.30.0 0.0.0.255 *使用ACl拒绝30.30.30.0
R1(config)#access-list 1 permit any * 允许其它网络
R1(config)#router rip
R1(config-router)#distribute-list 1 in e1/0 * 将ACL列表1应用到RIP进程E1/0的入站上
R1(config-router)#exit
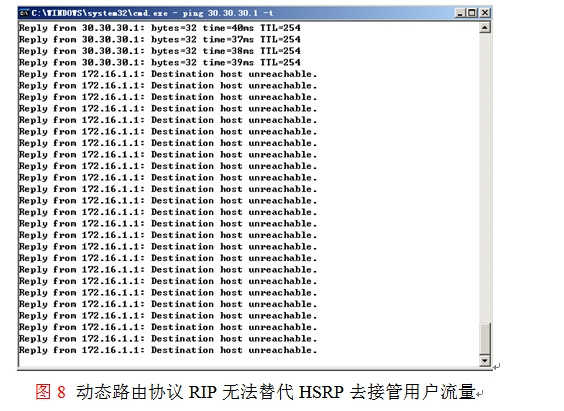
如果此时再次去切断路由器R1的S2/0和E1/1,动态路由协议RIP再也无法帮助用户完成收敛,去接管用户流量,而当前的HSRP并没有配置track功能,没有去跟踪外部接口S2/0和E1/1的状态,当两个外部接口关闭后,HSRP状态不会改变,不会让R2接管R1成为活动路由器,所以主机将一直丢包,如图8所示。
 #p#
#p#
第四步:首先请使用no shut指令再次恢复R1上的两个接口(S2/0和E1/1),然后配置路由器R1的HSRP去跟踪S2/0和E1/1。使用HSRP的接口跟踪功能去替代路由收敛的故障接管行为,具体配置如下所示:
配置路由器R1的接口跟踪功能:
R1(config)#intee1/0
R1(config-if)#standby1 track s2/0 5 * 跟踪S2/0接口,如果故障优先级减5
R1(config-if)#standby1 track e1/1 20 * 跟踪E1/1接口,如果故障优先级减20
R1(config-if)#exit
从实践的角度来讲为什么在跟踪两个不同接口时会作出这样的优先级设计?
从实验环境不难看出,路由器R1的S2/0是一条低速链路,R1和R2的以太网链路具备同等的收发速率,就即便是R1的S2/0故障,R1也和R2具备相同的发送速率,所以没必要S2/0故障后,进行HSRP的角色转换(将R2活动路由器),所以使用standby 1 track s2/0 5指令申明当S2/0故障后,HSRP的优先级只减少5,那么R1就会从原来的优先级110,变为105,仍然高于路由器R2的优先级100,所以R1仍然会是HSRP冗余组中的活动路由器。
路由器R2是不会接管故障,断续充当备份路由器的角色,这样做的***实践是,省去了收敛时发生丢包的可能。
如果R1的E1/1接口故障,效果就完全不同,如果R1的E1/1故障,即便是S2/0仍然存活,如果不将HSRP冗余组的路由器进行角色转换(将R2转为活动路由器),那么整个企业网络的流量都将通过R1的低速链路S2/0进行转发,这样会导致链路的利用率下降,所以使用指令standby 1 track e1/1 20申明,跟踪R1的E1/1,如果E1/1故障,那么优先级将下降20,从原来的110变为90,那么些时R2的优先级100就高于R1的90,那么R2将接管故障,成为HSRP冗余组中的活动路由器,流量将切换到R2进行转发。
完成上述的配置后,可以通过指令Show standby来查看R1当前的优先级、各个跟踪链路优先级的递减值,如图9所示。
 #p#
#p#
第五步:通过制造R1的E1/1故障的现象来验证R2接管故障的事实,如下所示的配置,在路由器R1上切断E1/1接口。
R1(config)#intee1/1
R1(config-if)#shutdown
R1(config-if)#exit
系统提示:跟踪状态E1/1从up转为down。
*Jul 24 11:43:52.967: %TRACKING-5-STATE: 2 interfaceEt1/1 line-protocol Up->Down
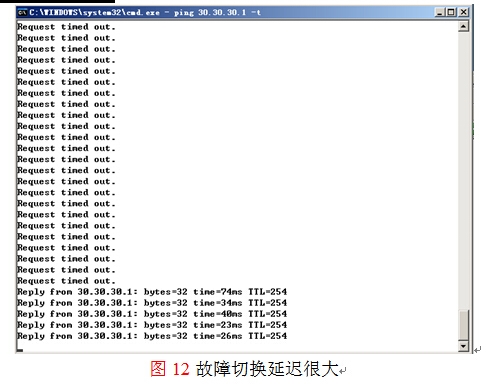
然后在路由器R1上执行show standby查看当前HSRP冗余组的状态,如图10所示,可看到E1/1的状态为down,优先级减少20,当前优先级为90,活动路由器为R2。然后在主机上执行路由跟踪,如图11所示,可看到流量通过R2(172.16.1.2)转发。
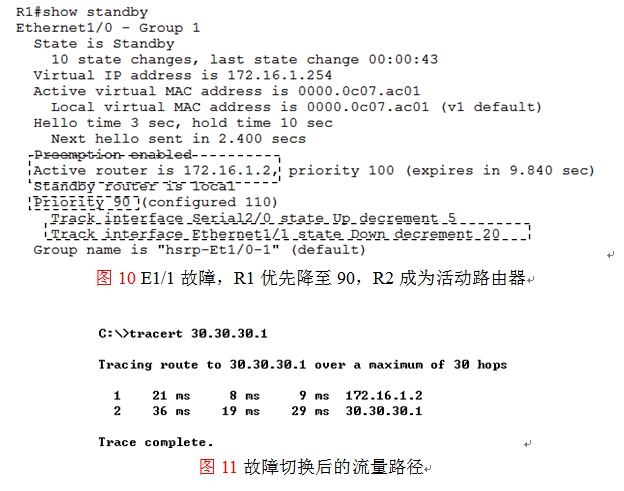
动态路由协议RIP引发HSRP的慢收敛问题:
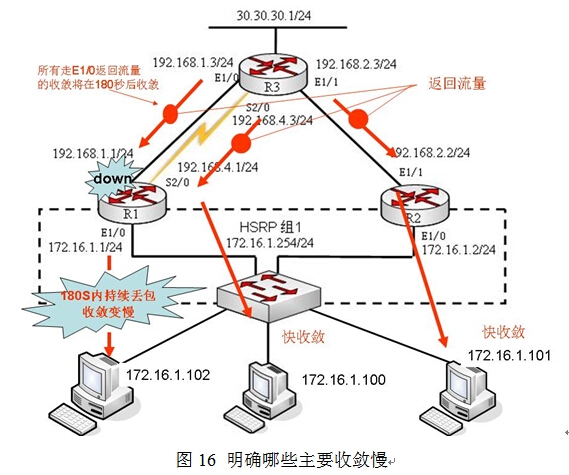
注意在本实验环境的第五步中,当路由器R1的E1/1发生故障,172.16.1.0/24子网的主机在做故障切换时,有部分主机可能会很可能会收敛很慢如图12所示,而另一部则收敛很快,现在需要来理解清楚目标是:
1 哪些主机收敛慢,哪些主机收敛快,这是为什么?
2 是什么原因导致收敛慢?
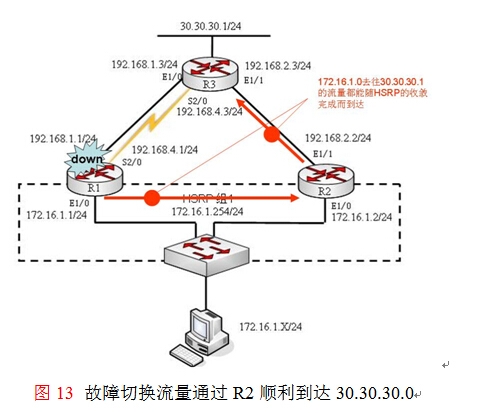
首先来分析当路由器R1的E1/0故障后,由于HSRP的冗余跟踪了该接口所以会立即触发HSRP的故障切换,此时R2会成为HSRP组中的活动路由器,172.16.1.0到30.30.30.0的流量将如图13所示通过R2到达,这是不可质疑的,所以去往30.30.30.0的通信流量很顺利。造成长时间(至少180秒)的收敛的原因主要出现在30.30.30.0返回给172.16.1.0网络的通信过程中。
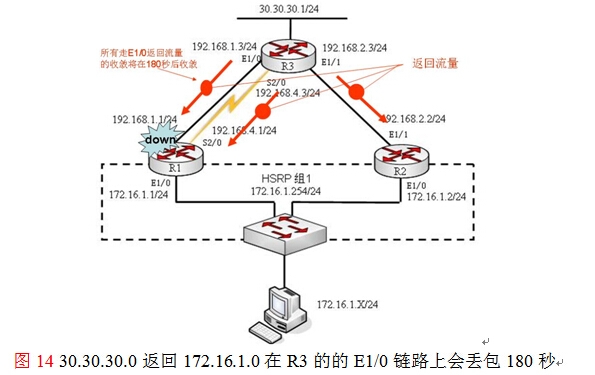
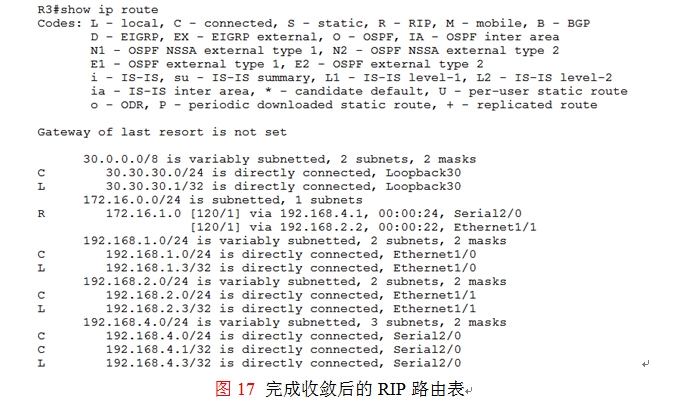
众所周知的一个事实,RIP的收敛一直都是一件非常令人头痛的问题,特别是非本地直连接口故障后,路由表中的相关记录要守侯invalid(无效定时器)超时,默认情况下180S,这条故障的路由才会从路由表中消失,以该本环境为例,当路由器R1的E1/1接口故障,路由器R3的路由表中“172.16.1.0 255.255.255.0 192.168.1.1”这条路由要等待180秒左右,也就是3分钟才会从表中消失,如图15所示,那么在这3分钟左右整个网络将发生什么样的事件呢?
如图14所示,30.30.30.0的返回目标172.16.1.0网络的通信流量时,在180秒内将在三条路径上进行负载均衡,已经故障的链路R3的E1/0,因为“172.16.1.0 255.255.255.0192.168.1.1”这条路由没到180秒,还存在于路由表中,所有只要是通过“172.16.1.0255.255.255.0 192.168.1.1”这条路由返回给目标172.16.1.0的数据都会出现丢包,而且时间在三分钟左右,收敛慢。
 #p#
#p#
这将进一步引出一个问题:172.16.1.0主机在故障切换的这个过程中,一些主机故障收敛较快,丢包很少,一些主机收敛很慢,会有长达3分钟左右的丢包,关键是哪些主机收敛快,哪些主机收敛慢,这是为什么原因?
这被R3的ip cef的负载均衡模式所决定,在R3上RIP没有收敛的180秒内, 路由表还维系在如图15所示的状态下,30.30.30.1将仍然使用“172.16.1.0 255.255.255.0192.168.1.1”这条路由来返回流量给172.16.1.0,默认情况下R3的ip cef的负载均衡方式是:如果存在多条路径(本环境中有三条),那么30.30.30.1将根据不同的目标主机来完成负载均衡,为了方便理解,举一实例来说明:如图16所示,当流量从30.30.30.1返回给172.16.1.0网络时,172.16.1.0网络的主机就是目标,那么R3的ip cef决定根据不同的目标主机使用三条路径来完成负载均衡,此时的172.16.1.101、172.16.1.100、172.16.1.102三台主机就是三个不同的目标,如果到目标172.16.1.101使有E1/1返回流量,那么收敛快;如果到目标172.16.1.100使有S2/0返回流量,收敛也快,因为这两条链路都是稳定的不需要RIP作收敛,但是到目标172.16.1.102在180S内就会出现持续的丢包,收敛慢,直到故障路由从R3的路由表中消失,如图17所示,才能顺利完成收敛。当然管理员可以在R3上通过clear iproute *来强制初始化R3的路由表,可以提高收敛的速度,但是这个解决方案过于极端,特别是在工业生产环境中,是不建议这样做的。
通过上述的分析与实验取证,大家应该能够体会到一个事实:往往一个网络现象或者故障并不是某一个技能知识点所引发,它可能是藏于一个知识点的背后,也可能是多个知识点进行集成应用时发生的,建议大家在网络工程领域始终不要以“一个点”的方式来看待发生的问题,应该进行联动分析,综合取证。
以该环境为例,大家看到了矢量路由协议在实战应用环境中的确如各个设备生产商所述的收敛是一个很大的问题,那么在该环境中,来使用静态路由去替代RIP并接合HSRP来完成冗余部署是否会有更好的效果,就本人看来问题更严重,如果不建立预设分析,那么用户将永远不知道将生什么,发生的原因,及如何解决?










