












数据挖掘、数据仓库,近些年在国内越来越热、越来越流行,需求比较多,应用也比较广泛,它们常服务于商务智能活动。通俗地概括来讲,我们可将它们统称作数据分析、数据计算。
我们介绍数据仓库在商业应用,主要涉及有两个方面,一个是有关数据仓库的常用技术,另一个是有关数据仓库的应用案例。同时也涉及数据仓库的两个背景,在我们经历的北美项目中,一个主要方面属于实际的商业应用项目,另一方面属于高校的学术研究领域的项目。两者在很多方面有明显的区别。我们这里主要介绍数据仓库的商业应用,因为商业应用经验存在比较大的价值。
数据仓库的商业应用技术之一:异构数据集成技术
数据仓库是集成的,数据仓库的要素包括本身是集成的、面向主题的、只读的、历史变化的。
如下图1:
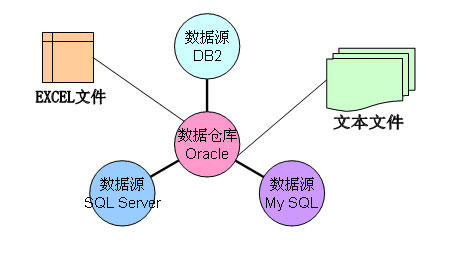
例如,应用Oracle作为数据仓库的支撑环境,它有很多数据源,是由业务生产系统源源不断产生的,可能包括DB2、SQL Server、MY SQL等等不同的源数据。
异构数据集成的方法有很多,主要包括:
1. 如果Oracle作为数据仓库是基于Windows环境的,通过MS ODBC开放数据库互联;第三方ODBC开放数据库互联,如Data Direct Connect for ODBC;专用数据网关,如Transpatent Gateway;
2. 如果Oracle作为数据仓库是基于Unix或Linux环境的,通过Unix ODBC开放数据库互联;专用数据网关等。
3. 通过外部文件到数据库的导出和导入。
#p#
数据仓库的商业应用技术之二:数据的ETL抽取、变换、载入技术
1. 三层ETL体系
我们将数据的抽取、变换、载入技术称为ETL技术。ETL技术中,按要素分为三层,即元数据层、数据操纵层、数据存储层,三层交互作用。ETL工作首先需要在元数据层定义和构建,同时也涉及到有关数据存储的方式定义;基于元数据层的对象,ETL工作在数据操纵层对数据进行实际操作,并把数据载入到数据存储层;ETL工作还需要在数据存储层做一些必要的数据管理和优化工作。这就形成了ETL数据操纵的三层体系,如下图。

元数据 -> 数据操作层 -> 数据存储层。
2. ETL递进式数据演变
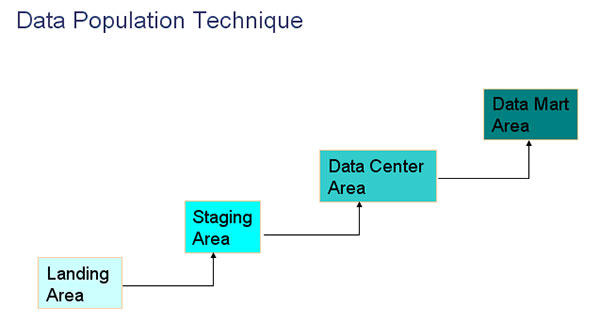
ETL数据变换在实际项目中有很多的方法,很多阶段,在此我们根据经验分为4个阶段为:
LANDING:抽取数据到Landing层中。
STAGING:根据我们业务的要求进行数据变换到Staging层中。
DATA CENTER:再根据需求设计放在Data Center层(也是EDW企业级数据仓库)中。
DATA MART:***根据主题存放在Data Mart层中,如下图。
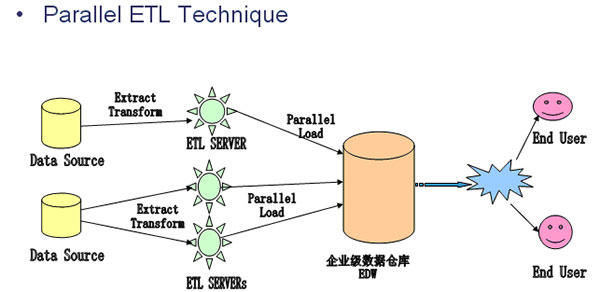
3. 并行ETL架构
并行处理技术也是数据库的一项核心技术,它可以提高ETL过程中在数据层处理的执行效率,将大量的查询过程分布到多个节点上同时执行。一个并行处理体系结构的数据仓库系统,不仅应该确保底层硬件平台的所有资源都得充分利用,而且应该能够将这些资源适当分配给多个并发请求,以提高数据层的并发处理能力,如下图。
4. ETL任务调度及备份
ETL任务调度(Scheduling Tasks)很重要,需要实时的备份。常用的ETL任务调度工具(Scheduling Tools)有:
Unix scripts:Corn有比较稳定的可靠性。
Database Management Tool:Oracle Enterprise Manager
Third Party Tool:Control-M专用工具,专门为数据仓库完成任务,主要做ETL的Scheduling。
ETL任务调度备份方法有很多,如:
Scheduling Backup:Control-M as Master,
Unix Corn as Backup.
这样,相当于做了两个Scheduling设计,互为备份。
#p#
数据仓库的商业应用技术之三:数据仓库的架构技术
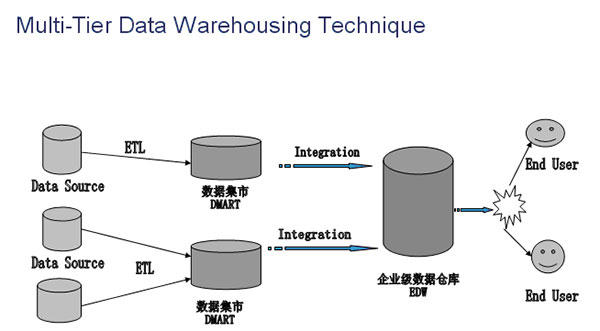
1. 多层次企业级数据仓库:DataMart-> EDW
在这个数据仓库架构的模型中,左边的是数据源通过变换到数据集市中,然后从数据集市再到企业级数据仓库(EDW)中,***直接给终端用户使用。多层次主要体现在ETL和数据集成上,这个方法的优点在于建立了多个数据集市,它体现了一个分布式集成的概念,很大程度降低了企业级数据仓库建设的风险,更减少了资源投入,如下图。
2. 多层次企业级数据仓库: EDW -> DataMart
这个模型一开始就设计它的企业级数据仓库(EDW),这种方法针对于一些涵盖了多个业务系统、面向不同用户的需求、针对数据平台也不一样的企业,例如:银行。用这个方法,把所有的业务系统考虑入内,通常考虑整体设计,然后再分发出去。DataMart划分方法有很多种。它的优点是集成度比较好,总体设计一开始就把所有的数据源都放到企业级数据仓库。缺点是风险高,投入也相对很高,如下图。
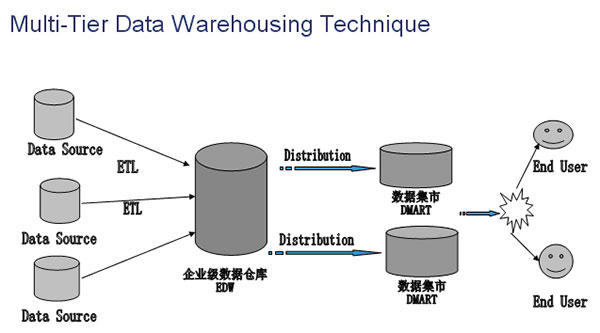
通常来说,实际项目中采用***种方法的比较多。
3. 近实时的数据仓库
数据仓库是动态的,是随时间变化的。应用数据仓库,我们可以每天、每个月、每年分段来调取数据,如下图。

近实时(Near Real Time)的要求是比较高的,例如我们建立了一个数据仓库是全球性的,数据仓库中心在多伦多,数据源分布在很多地方如北美、欧洲,它需要一个近实时的操作系统。近实时的概念是操作系统和业务系统产生的数据,在一小时之内完成所有ETL任务,***进入数据仓库。它对数据源的业务系统有比较高的要求,如数据的稳定性、可靠性、网络传输速率等,同时也涵盖了很多方面的专门技术来解决实时性。
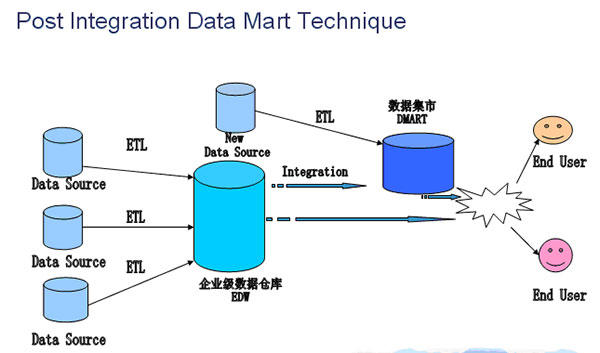
4. 后复合数据集市
由于业务的扩展,企业增加了一个新的生产系统,从而诞生了新的数据源。我们需要建立一个新的数据源(New Data Source)通过ETL工作集成到数据集市(DMART)中,并与企业级数据仓库(EDW)结合到一起,***提供给终端用户,如下图。
#p#
数据仓库的商业应用技术之四:数据仓库的优化技术
数据仓库优化包括很多内容,包括数据库实例优化、数据库的设计优化、数据仓库设计(建模)优化、数据存储优化、存储过程优化、中间层支持优化、应用支持优化(智能报表、即时查询、数据挖掘等应用)。
数据仓库的客户有两个常见要求,一个要求是快,还有一个要求是稳定。快有很多方面,在核心的数据库,有太多的因素影响速度,所以优化时要各个方面都要考虑。
1. 数据仓库设计(建模)优化
在设计的时候有很多的情况发生,在这里重点提一点,数据仓库还要考虑一个时间的因素,有的时候开始设计的时候性能非常好,但随着系统长时间的运行,发生了很多无法解决的、由设计造成的问题,如性能问题。曾经有欧洲的一家汽车企业,设计师对数据仓库的模型设计想法非常好,但是不适宜一个长时间的运行,数据增长以后性能大幅下降,数据运行可能会非常的慢,到了无法容忍的地步,结果导致运行两年以后就不行了。想要再进行结构修改也不可行了,必须要全部重来。
2. 数据存储优化
数据存储优化主要是如何尽量减小存储空间和提升性能。这点很重要,数据仓库往往都是牺牲空间来提升速度。但是也需要优化,很多问题在一些小的数据仓库系统可能都不存在,但是在比较大型的数据仓库系统中就会出现了。数据仓库数据不断增加,当使用时间比较长之后就会造成数据量过大、性能会大幅下降,为了避免这样的情况,我们在开始设计时,就要考虑到后续的使用,需要进行数据存储优化,主要包括:
Data Block Design:基本存储单位的设计。
Table Spacing:表空间的设计。
Table Partitioning:表空间的优化。
Indexing:索引的设计。
Index Partitioning:索引优化。
Data Compressing:数据压缩(同时会牺牲一些性能)。
3. 存储过程优化:就是后台的一些存储过程的优化。
4. 中间层支持优化:WEB SERVER之类的系统优化。
5. 应用支持优化:主要有智能报表、即时查询、数据挖掘等应用,也就是前台的一些应用也是需要优化的。一个REQUEST发出去,返回的RESULT,这个过程是有很多的步骤,也是需要进行优化处理的。
另外,还需要在一些方面对数据仓库进行优化,如:异构数据库互联优化。异构数据库互联,做数据仓库***步就会碰到,数据仓库肯定有很多不同的数据源。具体如下图所示。
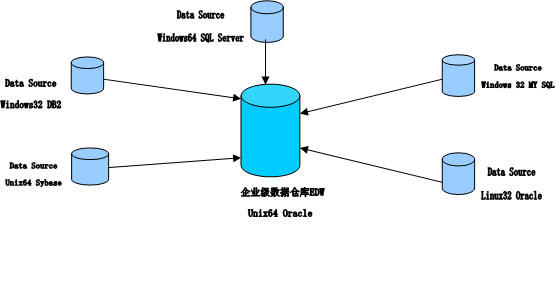
上述例子就比较复杂,既有不同数据库,又有不同操作系统。异构数据库互联优化的案例:
A、文件导出导入 -〉开放数据库互联
由文件导出导入方案改为开放数据库互联方案,可优化异构数据库互联的性能。例如:Windows ODBC, Unix ODBC,性能和可控性上肯定会比较好一点,但是有的时候并不是这样简单的要求,还需要考虑数据安全性的要求。例如某些情况下,条件不允许做数据库的互联。还有业务系统的健壮性能也要考虑。
B、通用ODBC -〉第三方专用ODBC
由ODBC方案改为第三方专用ODBC方案,可优化异构数据库互联的性能。例如: MS ODBC -> Data Direct ODBC。
C、开放数据库互联-〉专用数据网关
由ODBC方案改为专用数据网关方案,可优化异构数据库互联的性能。例如: MS ODBC -> Transparent Gateway。












