首先,题目中说是路由项定位结构而非查找结构,说的是,使用这个结构,以一个IPv4地址作为输入的时候,在得到下一跳的过程中,将不会有任何的查找操作,仅仅不断使用索引定位就可以了。为了先有一个直观上的认识,先给出查找结构图:
1.先从多级索引说起
在 我的那次失败经历中,我企图完全模仿MMU来设计路由查找结构,结果失败了。其实现在想想,也不失败,因为路由项的数目毕竟是有限的,对于整个4G个 IPv4地址来讲,它的数量可以忽略。因此还是可以使用多级索引的。以16-16二级分割,效果也还不错,构建和查找结构理解起来都不难。但是我们计算一 下它的内存占用,64k的一级索引表是必须的,根据前缀长度大于16的路由项的数目N,分裂出N个64k的二级表项,然后就结束了,一共N+1个64k的 表项,一级索引指向二级表的地址,起码要4字节,二级表项可以指向一个下一跳表的索引,鉴于直连下一跳的数量不会超过256,1字节足够。
如果使用多级表,也还可以。但是有更优化的方式,因为你会看到,这么多表中,很多内容都是重复的,我们需要的是,再引入一些表,压缩掉这些重复的数据。
2.再谈DxR算法
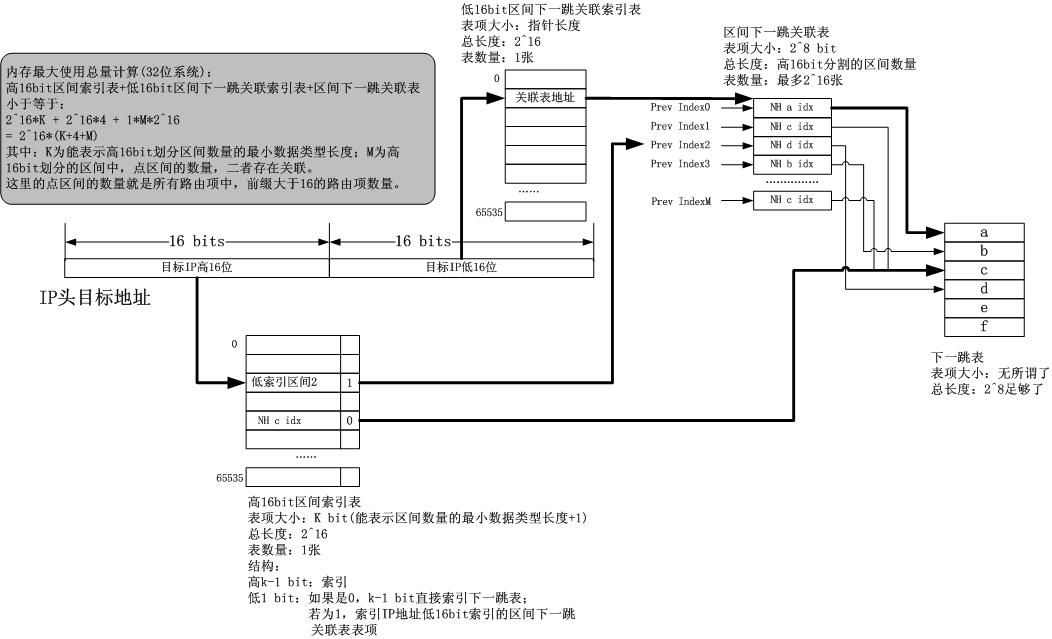
我终于可以在本文中给出一个DxR的真实结构而不仅仅是一个思想。如下图所示:
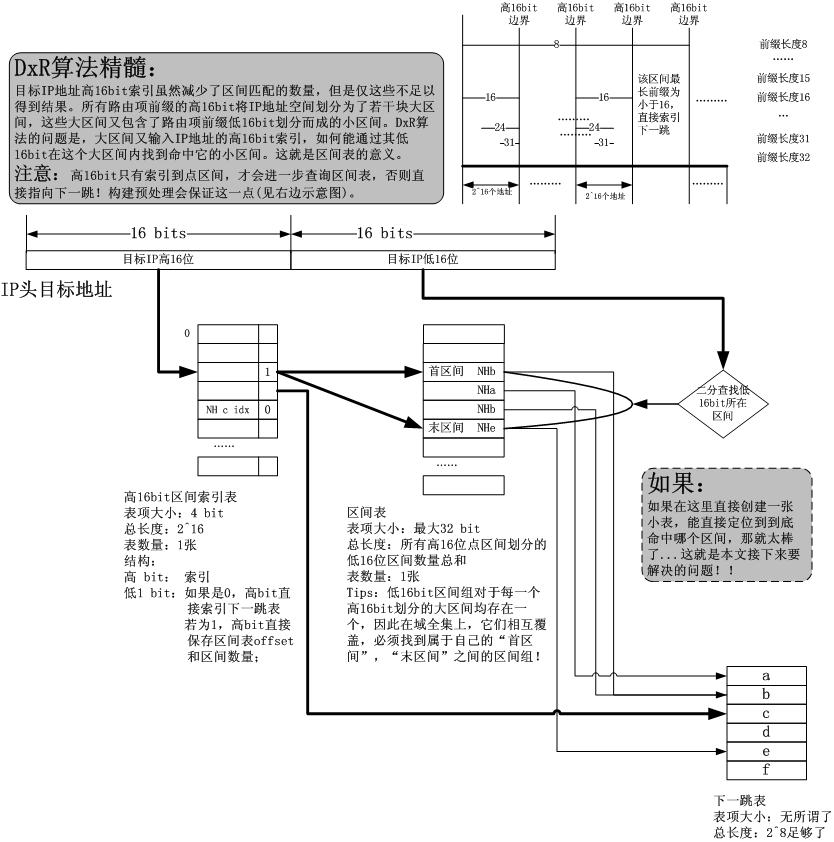
关于它,我要说的就是那个“如果”,事实上,就剩下这一步了。只要能找出一个办法快速索引到区间idx,问题就结了。#p#
3.直观的设想
依然保持二级结构,然而我需要想办法压缩N张二级表。压缩到多少算好呢?于是狠一点,就死死地保持1张!至于怎么做?再想!
既然只有1张二级表,就要想办法将之前的N张二级表的内容压缩到一个位置,即另外一组表。
必须明白一个事实,即我知道一级表中点区间的数量和位置。位置可以通过一级索引在预处理时定位,数量可以在预处理时数出来。
这个事实至关重要,为此,我将一级索引表中所有的点区间进行顺序编号,并将这个号保存在点区间对应的索引项中。在明白了这个事实之后,接下来我在想如何利 用它,此时另一个事实也逐渐呈现,即二级表只有1个,而对于所有的一级表索引的每一个点区间而言,对应的低16位二级表空间同样都是从从0到65535的 地址子空间。
那么现在的问题就是,如何将其区分开来,这个时候,刚刚认识到的第一个事实就有用了。对!就是用一级表索引的点区间编号来索引二级表索引到的那个表,这个表很显然就是区间下一跳关联表。总体示意图如下:
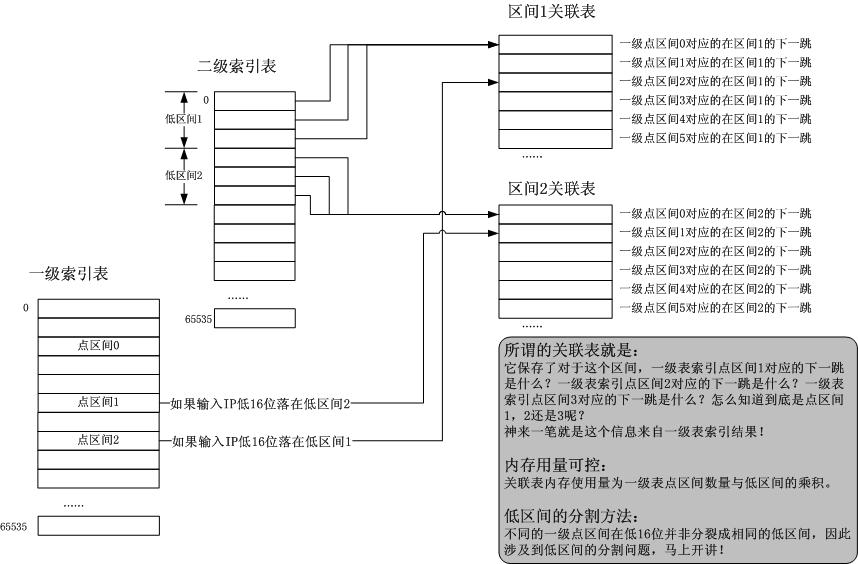
可见,享用数组下标寻址的终极的目标就是,将稀疏的变成密集的,如果不能,就要引入额外的表用来提取共享数据。
4.低区间的分割方式
从现在开始,我将路由表说成是转发表。因为路由表经过预处理已经完全变成转发表了。
此时,如果我能给出转发表预处理中最关键的一步,即低区间的分割方式,那么就几乎可以构建转发表了。构建过程如下图所示
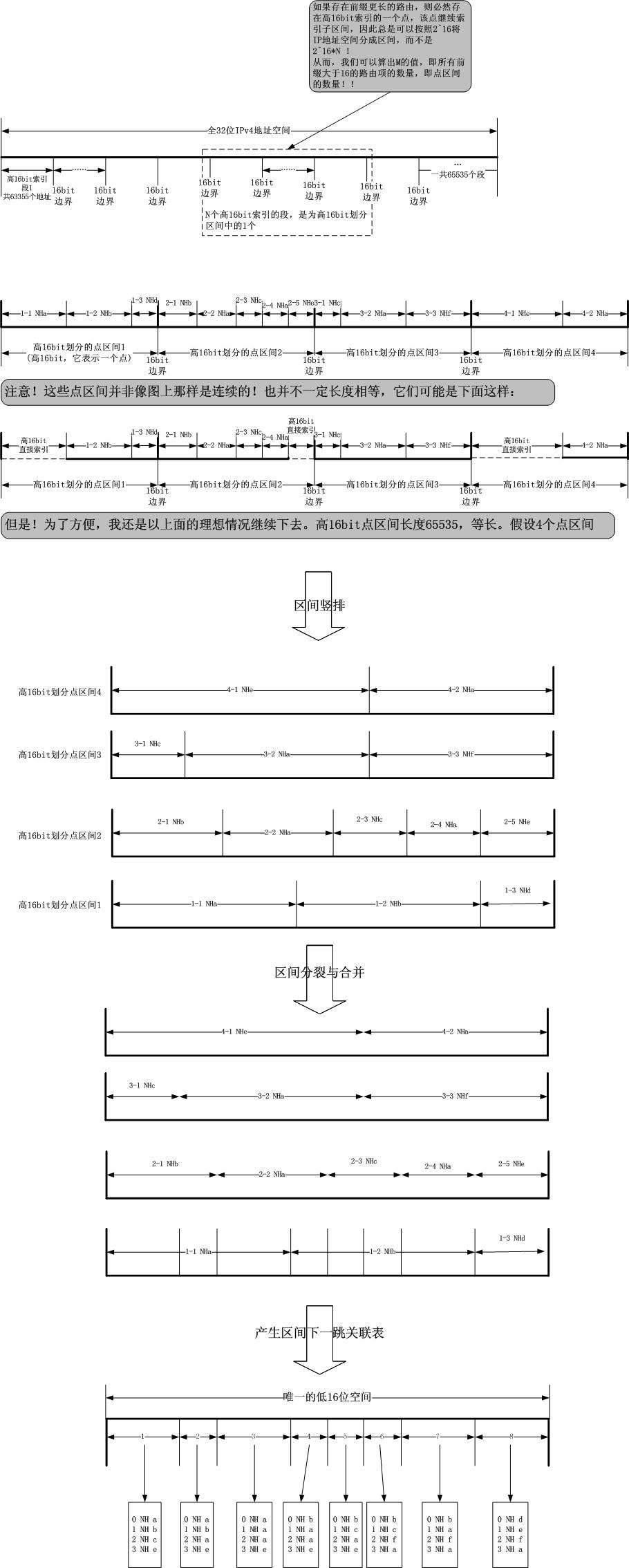
之 所以需要如此构建是因为我只有一个二级低区间表,由于对于不同的一级点区间,低区间无论从数量还是分布上看都是不同的,也就是说,每一个一级点区间都有自 己独立的低区间,这样一来就根本没有办法用唯一的一张低区间表来索引多个一级点区间引申出来的低区间,因此,我必须将所有这些独立的低区间集合映射到同一 个16bit域上,而映射的过程就是上图所示的过程!这个过程用文字描述如下:
1).所有M个一级点区间对应的低区间分割点元素放入一个集合S中;
2).将这个集合S进行排序,去掉重复点元素,此时S中元素个数为N;
3).构建N张关联表,每张关联表n的元素按照一级点区间索引顺序排列,其中下一跳索引要么使用自己在低区间合并前保存的-该分割点为该低区间固有,要么继承关联表n-1的对应下标处的下一跳-该分割点乃为了统一映射而硬放进来的。
到此,我们可以比较一下DxR的思想和我的低区间合并思想了。
DxR思想:一级点区间对应的所有二级低区间分别排列,由于所有低区间都在同一个16bit域上,它们中间有可能出现严重数据冗余,DxR算法无法发现这一点;
低区间合并思想:一级点区间对应的所有二级低区间统一排列,因此可以去除冗余数据,比如1.2.3.0/24和2.2.3.0/24的低区间分割点都有3.0/8,它们显然可以合并,但是也可能将一个大区间拆分成多个小的...
我们来举一个例子,有下列4个一级点区间对应的低区间分割点序列:
点区间1:0,1,3,4,7,8,16,32
点区间2:0,3,7,8,20,25,32
点区间3:0,2,4,24,32
点区间4:0,7,16,32
对于DxR算法,很显然在区间表中会将上述分割点全部写下:0,1,3,4,7,8,16,32|0,3,7,8,20,25,32|0,2,4,24,32|0,7,16,32
而在低区间合并法中,合并后的区间为:0,1,2,3,4,7,8,16,20,24,25,32
可见,消除了很多冗余区间分割点,但是对于所有点区间,它都将一些低区间劈开成了完全相同的两个,当然,下一跳也完全相同...这就是代价,不多的代价,但是必须付出的代价。#p#
5.我的下一跳定位结构
笔不多墨,火车上不啰嗦,关键是流量不稳定,只能离线写。事实上是目前移动IP做的太垃圾,高铁快速移动的时候,不能保证应用层不中断,MLXGB,于是就少说,慎独?Oh,NO!
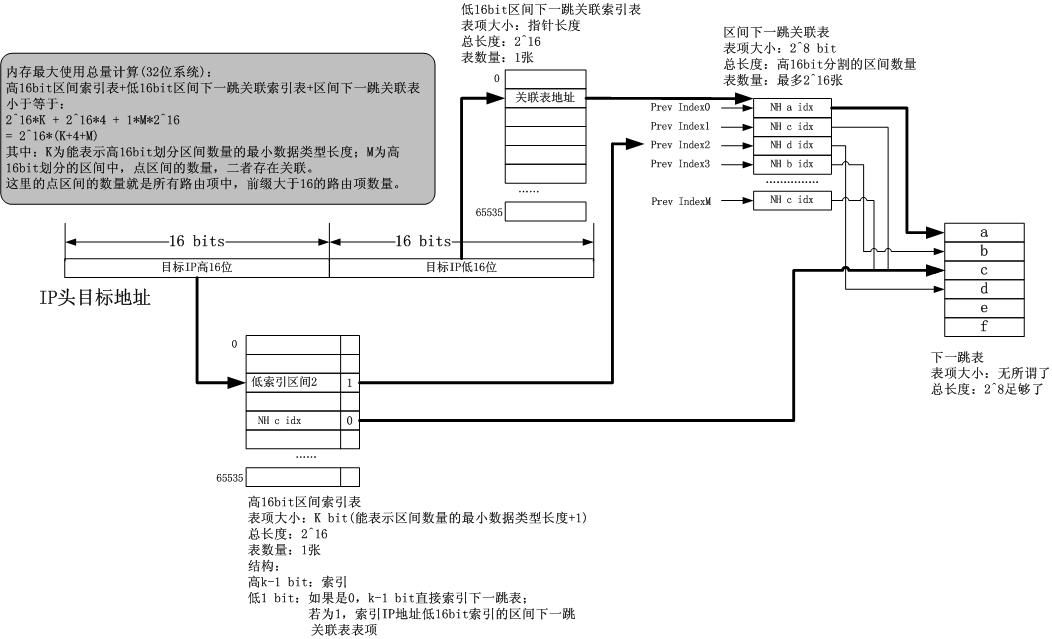
我这玩意儿到底有多好,我要说它起码拒绝了所有的查找操作,它只是单纯的定位!但是它是不是用庞大且高尚的空间换了可耻的时间呢?oh,NO!现在让我们看一下DxR算法的内存占用,这个图来自http://www.nxlab.fer.hr/dxr/。
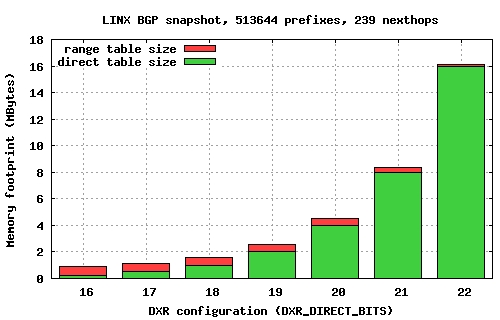
以16-16分割为例,它的区间表占用量几乎是64k的3-4倍,只要我能证明我的数据结构中二级表和关联表的内存占用量总和也是这个数量级的,我就赢了(之前华为有家伙写过一篇论文,使用并推崇了多级索引算法设计转发表,但是我不屑于这种方案,随便算一下DxR或者我的方案的空间复杂度,就会发现即便华为的人也不是不可及的...国内很多论文总是有欺世盗名之嫌疑,旋转升降座椅一定会爆炸,等着吧)。我赢的前提是,我没有使用任何“算法”,我只是基于索 引定位!然而,我也并没有因此使用更多的内存!
在DxR算法中,区间表的数量为所有一级索引表中点区间分割的二级区间的总和,其实我完全可以用西格玛符号写个算式的,但是需要截图,就算了。所以我用文 字表示:一级点区间1的a个元素低区间数组+点区间2的b个元素低区间数组+点区间3的c个元素低区间数组...+点区间M的x个元素低区间数组
我的算法中,使用了一个唯一的二级索引表,大小固定64k,而关联表数量不固定,关联表的数量为合并后的低区间数量,而每一个关联表的大小为一级索引表点区间的数量,计算公式为:
a,b,c,...x这M个低区间合并后的新区间1的M个元素数组+a,b,c,...x这M个低区间合并后的新区间2的M个元素数组....+a,b,c,...x这M个低区间合并后的新区间N的M个元素数组
写了个Python脚本,计算结果,发现我的方案在大多数路由项均匀排布情况下,比DxR占用空间更小...爆炸!这个实际的工作促进了我对Python的学习。
6.转发表和路由表
这个小节本来我想写一篇完整的文章的,但是现在在高铁上,怕旁座的人嘲笑我(其实按照概率算,80%的人都不知道我在写什么...),就只能把它写成项目报告的形式了,爆炸!
在Linux中,路由表就是转发表,每一个数据包都要去查询这个表(别扯路由Cache,目前已经被cut了,why?因为考虑到应用的多样性,特别是P2P环境下,数据包的时间局部性特性已经不再是一个前提,so,....),这就会带来一个问题...路由表存储的是前缀-下一跳映射,而数据包要完成 是找到这么一个路由项,因此就需要进行一系列的查找过程...
为什么不对路由项进行一系列预处理呢?结果就是让一个IP地址直接找到下一跳!我在想我如果能建立一张表,能让一个IP地址能以“最快的速度”映射到下一 跳,那么我就足以月薪还贷养女无压力了....但是,我错了,因为这是一个傻逼都能想出的思路。我只是把它描述了一下而已,不过如果要是能早出生30年, 现在应该已经是一个爷爷了...
“以最快的速度”直接找到下一跳,有两种方式,第一就是在空间占有有严格要求的苛刻环境下使用更高效的算法,第二种方式就是用大量的空间节省宝贵的时间,但是我的方案是,用稍微的一点空间占用完全索引化路由定位!
路由表是什么?是协议栈IP层控制平面的内容。转发表是什么?是协议栈IP层数据平面的内容。理解了这个区别,你就可以用最大的可能性优化转发表,即便路 由表的数据结构是如此的固定。换句话说,路由表需要更高的效率进行增,删,更新操作,而转发表则需要更高的效率进行查询操作。路由表在稳定的时候,可以 “慢慢地”转化为转发表。Linux并没有区分路由表和转发表(别把Linux的路由cache理解成转发表),这是一个通用操作系统内核协议栈的通用做 法,而不是专业路由器操作系统的做法,因为,专业路由器的操作系统内核协议栈往往只注重控制平面和管理平面,而数据平面的操作则完全不在操作系统协议栈里 面完成,而是专门的硬件或者软件子系统来完成的,控制平面和管理平面控制和管理的是什么?是数据平面!#p#
7.非要16-16分割吗?
虽 然我在上面一直都是使用一二级索引表的16bit-16bit分割,就好像一定要这样才可以,事实上不是这样的。毕竟我的一部分思想来自DxR,另一部分 来自区间位图匹配,还有一部分来自MMU,不管这些中的哪个,都没有固定一级索引的长度,区间位图索引实际上也不一定非要固定长度索引。
一级索引长度可以根据路由项的分布以及CPU Cache Line情况具体情况具体分析,比如说,如果路由项中有大量的16-20前缀长度的路由项,那么完全可以使用20bit的一级索引,因为这样可以减少二级 低区间合并后的数量。甚至,还可以更加灵活一点,一级索引表中额外使用2bit数据,00指示一级索引直接索引下一跳,01指示一级索引的作用是索引低区 间,10指示一级索引用来定位DxR区间表的start和end,也就是说使用DxR的算法,我的最初想法是采用下面的序列动态变换一级索引表项的那 2bit数据:
1).离线统计,作为2bit数据设置的依据
基于一段时间作离线统计,得到路由项命中最不经常(它们只是平添了 二级低区间的分割数量)最不绝对(意味着这些路由项没有时间局部性,延迟可容忍)且前缀分布最散列(分布太散,意味着二级低区间将因为这些路由项被分割成 数量巨大的小块)的前K个路由项(涉及到KD树算法)。这三个指标可以加权取平均,权值自定义。同时统计出上述三个指标的另一端极致,取D个路由项,统计 出D个中前缀长度依次从小到大排列的m个路由项。
2).设置DxR区间表
将这K个路由项的一级索引的2bit指示位设置成10,并设置DxR区间表。既然这K个路由项最不经常使用且碎片化而且在很大概率上是可以容忍延迟的,那么就让它们慢慢被二分检索吧,不会增加由于二级低区间的过度切割带来的内存用量递增。
3).设置一级索引bit长度
将m个路由项的最长长度前缀的长度值作为一级索引的长度,以保证这些路由项的下一跳可以在最少的CPU周期内直接被一级索引表项定位到。
4).设置二级低区间
剩下的所有路由项采用我的办法进行二级定位。
8.结束
这 篇文章没有什么技术含量和技术门槛,但是却占用了我很多的时间。这个想法很久以前就萦绕在老湿心里了。那得从一次不赚一分钱的私活儿说起,纯粹是帮 忙...在物联网时代,仿佛一切又回到了20年前从新开始,内存苛刻,延迟不能容忍...自然路由子系统也逐步不再只是高大上的核心网管理员才能碰触的圣 物,我也不能再仅仅局限于能看懂讲明白甚至移植或者写出Linux内核的那套算法了,不管是HASH还是LC-Trie...我要找的是一个忽略时间复杂 度的定位结构,而不是一个查找结构,注意,是找而不是设计。然而这不可避免的会遇到空间复杂度的问题...恰恰是华为的人帮我理清了思路,虽然不管怎么 说,他的方法我不敢恭维...
虽然构思了很久,但是一直没有动笔,直到听说本周要来京出差,我想这次应该可以挤出一些时间了,从来京的高铁上开始,工作结束后到酒店开始画图,整理思 路,终于有了一点逻辑,然后手写了一个预处理好的测试结构程序,注意,难点在预处理,我不想花太多的精力写这个预处理程序,因为这不可避免要碰到排序,二 叉树,路径压缩树,统计,KD树,消除重复项,寻找接近点等问题,这些过程都很简单,程序算法也能在各种面试宝典上找到,我想当我debug的时候,肯定 又会去baidu,连goolge都不用,所以我假设这些预处理都已经做好了,我只需要做一个索引即可,而这个程序只有不到200行代码,大概去掉打印# 号也就150行左右吧...数据使用了DxR的测试数据,加入了100k到500k左右的路由项,这已经是核心路由器的数量级了,测试下来,真的碉堡了 DxR,至于毫不区分路由表和转发表的Linux协议栈IP路由算法,我就不描述它的惨象了。只能说还行吧,确实还行,沾了点边。
这篇文章算是写完了,北京今天天气不错,蓝蓝的天没有云,明天又是新的一天,又有新的任务,踏上新的征途,感觉像是又一个2012/2013年要来了,在 那个初期我在地狱接着爬上山腰的项目中我锻炼了自身,学到了很多,但是却依然没有达到山顶,可以旋转360度俯视野草的境界(其实野草我是看不见的,看见 的只是云...),于是又有了希望,不管是设计一个新东西,还是继续SP,对于一个1983年出生的程序员中的网管,网管中的程序员,比较能扯历史,拘谨 又无畏,养女又还贷的IT技术男而言,接下来还有多少机会呢?我是一个平凡的人,虽然也曾经像每一个有梦想且自恋的技术宅男一样觉得自己是伟大且不自信 的。平凡的人不会创造历史,历史是英雄创造的,但是平凡的人是幸福的。人人为我,我为人人,我们都是平凡的人。最后用一段我对一件真实且平凡的事件的评价彻底结束本文:
知道什么叫学习和传道吗?今天和同事在出租车上聊起了古希腊马拉松的起源,出租车司机也参与了进来,他说起了古希腊有个人计算了地 球的周长,自以为精通希腊的我虽知道算法但竟然不知道这人叫什么,司机说此人名字很长,但他也记不清了,...于是到酒店后赶紧把那个人相关的时代和背景 复习了一下...现在我知道他叫埃拉托克尼(这个名字对于我而言,真心不算长)....事实上,我也教了司机一件他不知道的 事情,那就是旋转升降座椅会爆炸,并baidu了图片给他看...无论是谁,都可以是自己的老湿...他可能是的哥,三轮车夫,送快递外卖的,甚至饭店服 务员,然则你也要教他一件事作为回报,比如座椅爆炸...这就是基督教真谛,人人为我,我为人人。我妈信教,不知不觉,我也信了....爆炸如果我能本着 宣传座椅爆炸的精神和能力宣传公司的产品和技术,促进和别家的互补合作,促进产品的完善,那将会一幅多么美丽的画卷...爆炸!