












Olery成立于2010年,总部位于阿姆斯特丹。该初创公司为酒店行业提供声誉管理与媒体监控工具,帮助酒店将网络评论和社交媒体反馈转化成可执行的商业智能分析。
Olery成立最初是使用MySQL来存储(用户、合同等等)核心数据,用MongoDB来存储评论及其类似的数据(即哪些在数据丢失的情况下很容易恢复的数据)。一开始,这样的安装运行的非常好,然而,随着公司的成长,开始遇到了各种各样的问题,尤其是MongoDB的问题居多。其中一些问题是由于应用与数据库的交互方式而引起的,一些则是由数据库本身而产生的。
例如,某个时刻,Olery需要从MongoDB中删除一百万个文档,以后再把这些数据重新插入到MongoDB里。这样的处理方法使得整个数据库几乎要被锁定数个小时,自然服务性能就会降低。而且直到对数据库执行修复(即在 MongoDB上执行repairDatabase命令)后才会解锁。而且完成修复还要花费数个小时,修复所花的小时数要根据数据库的大小来确定。
在另一实例中Olery注意到应用程序的性能降低和设法跟踪到的 MongoDB 集群。然而,经过进一步检查,无法找到问题的真正原因。无论怎么安装,或使用什么工具敲了什么命令都找不到原因。直到Olery更换了集群的初选,性能才恢复正常。
这只是两个例子,Olery已经有过许多这样的情况。这个问题的核心是,这不只数据库在运行,而且无论何时察看它都没有绝对的迹象表明是什么原因导致的问题。
无模式的问题
另外,Olery面对的核心问题是mongoDB的重要特征之一:模式的缺乏。模式的缺乏可能听起来是有趣的,并且在一些情况下是有好处的。然而,对于许多无模式存储引擎的用法,其导致了一些模式之间的内部问题。这些模式没有通过存储引擎定义而是通过应用的行为及其可能的需要而定义的。
例如:你可能有一页存储你的应用需要的字符串类型的title字段的集合。这儿这个模式是非常符合当前情形的,即使它没有被明确的定义。但如果这个数据结果改变超时,尤其是如果原来的数据没有被迁移到新的数据结构,这就成了问题(在一些无模式的存储引擎上是相当有问题的)。例如,你可能有下面这样的 Ruby代码:
- post_slug = post.title.downcase.gsub(/\W+/, '-')
这样,针对每一个有“title”字段并返回一个String的文档,它都能正常工作。然而,对于那些使用不同字段名字(例如:post_title)或者根本没有标题字段的文档来说,它将不能正常工作。为了处理这种情况,你需要将代码调整为下面内容:
- if post.title
- post_slug = post.title.downcase.gsub(/\W+/, '-')
- else
- # ...
- end
另一种处理方法是,在你的模型中定义一个模式。例如 Mongoid,一个流行的针对Ruby的MongoDB ODM,就能让你做到这一点。然而,当使用这些工具定义一个模式时,你可能会好奇为什么它们不在数据库内定义该模式。实际上,这样做可以解决另一个问题:可重用性。如果你只有一个应用程序,那么在代码中定义模式并不是什么大问题。然而,如果你有许多应用程序的话,这将很快会成为一个大麻烦。
无模式存储引擎希望通过删除对模式的限制的方式,让你的工作变得更简单。但现实的情况是,确保数据一致性的责任推到了用户自己的身上。有时候无模式引擎可以工作,但我打赌,更多的时候是事与愿违。
好数据库的需求
有了更多的特殊需求后,迫使Olery寻求一款更好的数据库来解决问题。对于系统,特别是数据库,Olery非常注重以下几点:
- 一致性
- 数据和系统行为的可视化
- 正确性和明确性
- 可拓展
一致性是重要的在于它有助于帮助Olery对系统设定明确的期望。如果数据总是按照同样的方式存储,那么系统可以很方便的使用这些数据。如果在数据库层面要求表的莫一列必须存在,那么在应用层面就不用检查这列数据是否存在。数据库即使实在高压情况下,也必须保证每一次操作的完整性。没有什么事情比单纯的插入数据,过了几分钟后却找不到数据的事更让人沮丧了。
可见性包含了两点:系统本身以及从中获取数据的容易程度。如果一个系统出错那么应该易于调试。反过来,用户应很容易查到想要查询的数据。
正确性是指系统的行为如Olery所期望的那样。如果某个字段定义为一个数值型,没有人可以像其中插入文本。这方面MySQL是臭名昭著,一旦你这样做你将得到伪结果。
可扩展性不仅针对性能而言,而且也涉及财务方面和系统能够多么好地应对不断变化的需求。一个系统在没有大量资金成本或减缓系统所依赖的开发周期情况下,很难表现得非常好。
#p#
放弃MongoDB
上面的需求牢记于心后,Olery就开始寻找一个取代MongoDB的数据库。上面提到的特性通常是传统RDBM特征的一组核心集,所以Olery锁定了两个候选者:MySQL和PostgreSQL。
本来,MySQL是第一候选,因为Olery的一些关键数据已经在使用它存储。然而,MySQL也有一些问题。例如,当将一个字段定义为int(11)时,你却可以轻松地向该字段插入文本数据,因为MySQL会试图对它进行转换。下面是一些例子:
- mysql> create table example ( `number` int(11) not null );
- Query OK, 0 rows affected (0.08 sec)
- mysql> insert into example (number) values (10);
- Query OK, 1 row affected (0.08 sec)
- mysql> insert into example (number) values ('wat');
- Query OK, 1 row affected, 1 warning (0.10 sec)
- mysql> insert into example (number) values ('what is this 10 nonsense');
- Query OK, 1 row affected, 1 warning (0.14 sec)
- mysql> insert into example (number) values ('10 a');
- Query OK, 1 row affected, 1 warning (0.09 sec)
- mysql> select * from example;
- +--------+
- | number |
- +--------+
- | 10 |
- | 0 |
- | 0 |
- | 10 |
- +--------+
- 4 rows in set (0.00 sec)
值得注意的是,MySQL在这些情况下会发出警告。但是,仅仅是警告而已,它们通常(若非总是)会被忽略。
此外,MySQL的另一个问题是,任何表的修改操作(例如:添加一列)都会导致表被锁,此时将无法进行读或写操作。这就意味着,使用这种表的任何操作都不得不等待修改完成之后才能进行。对于包含有大量数据的表,这可能会花费几个小时才能完成,很可能会导致应用程序宕机。这已经导致一些公司(例如 SoundCloud)不得不自己开发工具(例如lhm)来解决该问题。
了解到上面的问题后,Olery开始考察PostgreSQL。PostgreSQL可以解决很多MySQL不能解决的问题。例如,PostgreSQL中你不能将文本数据插入一个数字字段:
- olery_development=# create table example ( number int not null );
- CREATE TABLE
- olery_development=# insert into example (number) values (10);
- INSERT 0 1
- olery_development=# insert into example (number) values ('wat');
- ERROR: invalid input syntax for integer: "wat"
- LINE 1: insert into example (number) values ('wat');
- ^
- olery_development=# insert into example (number) values ('what is this 10 nonsense');
- ERROR: invalid input syntax for integer: "what is this 10 nonsense"
- LINE 1: insert into example (number) values ('what is this 10 nonsen...
- ^
- olery_development=# insert into example (number) values ('10 a');
- ERROR: invalid input syntax for integer: "10 a"
- LINE 1: insert into example (number) values ('10 a');
PostgreSQL 还具有在许多方式中不需要每一个操作都上锁就可以改写表的能力。例如,添加一列没有默认值却可以设置为null的列并能够快速完成无需锁定整个表。
还有其他各种有趣的功能,如在 PostgreSQL 可以:trigram 为基础的索引和检索,全文检索,支持JSON查询,支持查询/存储键-值对,支持发布/订阅等更多。
最重要的是PostgreSQL在性能,可靠性,正确性和一致性之间能够权衡。
#p#
迁移到PostgreSQL
最后,为了在所关心的各种项目之中达到平衡,Olery决定使用PostgreSQL。但是,将整个平台从MongoDB迁移到一个截然不同的数据库并不是很容易的事。为了使转移工作简单化,Olery将此过程分成了3个步骤:
- 搭建一个PostgreSQL数据库,并迁移数据的一个小子集。
- 更新所有依赖于MongoDB的应用程序,连同任何需要的重构,都用依赖于PostgreSQL的程序替代。
- 将产品数据迁移到新数据库上,然后部署新平台。
部分数据迁移
在考虑把所有数据迁移到新数据库之前,Olery先迁移了一小部分数据来做测试。如果仅仅是迁移一小部分数据,就有非常多的麻烦的话,那么数据库迁移也就没什么意义了。
尽管有现成的工具可以利用,但还是有些数据(比如,列重命名,数据类型不一致)要做转换,对于这些数据Olery自己开发了些工具。这些工具中,大部分都是Ruby写的一次性脚步,用于删除一些评论,整理数据编码,修正主键发生序列等等。
在测试开始阶段尽管有些数据上的问题,并没有出现大的会阻碍迁移的问题。例如,有些用户提交的数据没有完全按格式编码,导致这些数据被重新编码之前,不能被导入到新数据库。例外一个有意思的改变是,之前评论的数据存的是评论用的语言的名称(如“荷兰语”,“英语”等),现在改了存语言的编码,因为 Olery新的语义分析系统使用的是语言编码,而不再是语言名称。
更新应用
目前为止,花费时间最多的就是更新应用,尤其是那些严重依赖MongoDB聚合框架的应用。扔掉那少数几个遗留的Rails应用吧,光是测试就会花掉你几个星期的时间。更新应用的过程大致如下:
- 用PostgreSQL的相关代码来替换掉MongoDB的驱动/设置模块的代码
- 运行测试
- 修复Bugs
- 反复运行测试,直到所有测试通过
对于非Rails应用,Olery推荐使用 Sequel,对于Rails应用,Olery现在还无法摆脱ActiveRecord(至少是现在)。Sequel是一个非常好的数据库工具集,它支持绝大多数(如果不是全部)我们想使用的PostgreSQL特性。相较于ActiveRecord,它基于DSL的query要强大的多,尽管可能耗时会有点长。
举个例子,假设你想计算有多少用户使用某种语言,并计算每种语言所占的比例(相对于整个集合)。纯粹的SQL查询语句如下所示:
- SELECT locale,count(*) AS amount,
- (count(*) / sum(count(*)) OVER ()) * 100.0 AS percentageFROM users
- GROUP BY localeORDER BY percentage DESC;
- 在我们的例子中,将会产生以下输出(当使用PostgreSQL命令行界面时):
- locale | amount | percentage
- --------+--------+--------------------------
- en | 2779 | 85.193133047210300429000
- nl | 386 | 11.833231146535867566000
- it | 40 | 1.226241569589209074000
- de | 25 | 0.766400980993255671000
- ru | 17 | 0.521152667075413857000
- | 7 | 0.214592274678111588000
- fr | 4 | 0.122624156958920907000
- ja | 1 | 0.030656039239730227000
- ar-AE | 1 | 0.030656039239730227000
- eng | 1 | 0.030656039239730227000
- zh-CN | 1 | 0.030656039239730227000
- (11 rows)
Sequel允许你使用纯Ruby编写上面的查询,而不需要字符串分段(ActiveRecord经常需要):
- star = Sequel.lit('*')User.select(:locale)
- .select_append { count(star).as(:amount) }
- .select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) }
- .group(:locale)
- .order(Sequel.desc(:percentage))
如果你不喜欢使用“Sequel.lit(“*”)”,你也可以使用下面的语法:
- User.select(:locale)
- .select_append { count(users.*).as(:amount) }
- .select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) }
- .group(:locale)
- .order(Sequel.desc(:percentage))
虽然这可能有些冗长,但是上面的两种查询都使得它们更易于重用,而无需进行字符串连接。
未来可能也会将Olery的Rails应用程序迁移到Sequel,但是考虑到Rails与ActiveRecord耦合得如此紧密,所以Olery还不完全确定这是否值得花费时间和精力。
#p#
迁移生产数据
最终Olery来到迁移生产数据的过程。一般有两种方法来做这件事:
- 关掉整个平台,直到所有数据都已迁移完成。
- 迁移数据的同时保持系统运行。
第一个选项具有一个明显的缺点:停机时间。第二个选项不需要停机但是很难处理。例如,在这个方案中,当你迁移数据的同时,你必须要考虑所有将要添加的数据,否则你就会损失数据。
幸运的是,Olery有一个独特的方案就是Olery的数据库的绝大多数写操作都是相当定期的,经常变化的数据(例如用户通讯录信息)只占总数据量的一小部分,相比起Olery检查数据,迁移它们花费的时间相当的小。
这部分的基本流程是:
- 迁移关键数据,例如用户、合同和那些无论如何都无法承担损失的数据。
- 迁移不那么关键的数据(我们可以重新收集,重新计算等的数据)
- 测试是否所有事情都已完成,并运行在一组分离的服务器上。
- 将生产环境转换到新的服务器上。
- 重新迁移第一步的数据,确保在迁移过程中产生的数据没有丢失。
到目前为止,第二步花费的时间最长,大约为24小时。另一方面,迁移步骤1和5中提到的数据只花了45分钟。
结论
Olery迁移完成并且直到非常满意大概过去了一个月。到现在为止除了那些积极的影响,还曾在各种情况中让应用的性能大幅提高。举例来说,Olery的 酒店评论数据API(Hotel Review Data API)(在Sinatra运行)相比迁移之前交互延迟变低了许多:
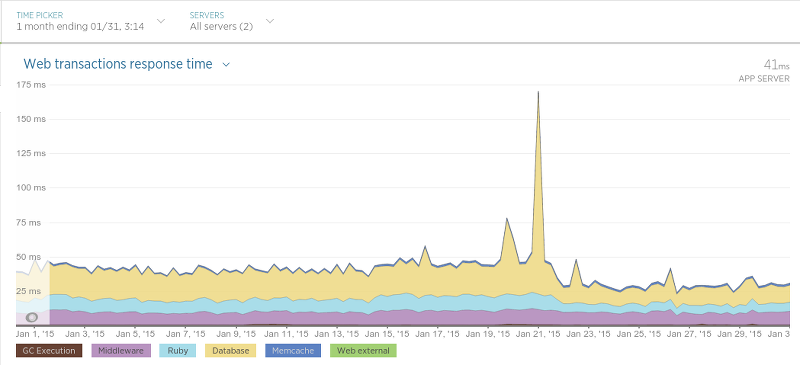
迁移是在1月21日开始的,高峰表示应用性能的硬重启(在处理期间导致交互时间轻微变慢)。在21日之后交互的平均时间大致是原来的一半。
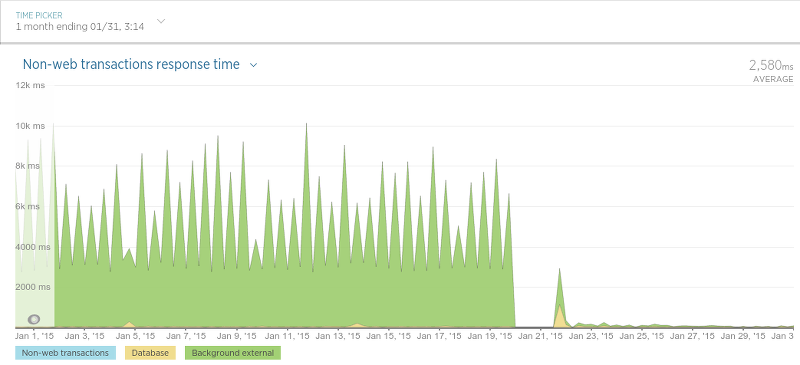
在另外一种被Olery称作“评论持久化”(译者注:即存储评论)的过程中,Olery发现了性能上巨大的提升。后台程序目标很简单:保存评论数据(评论内容,评论分数等等)。当最终完成了为迁移工作做的很多大的更改后,结果令人振奋:
抓取器也变的更快了:
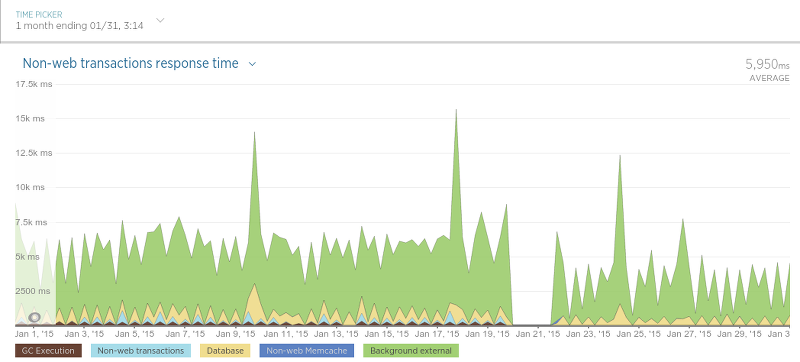
抓取器性能提升没有评论存储的过程那样大,因为抓取器只用数据库来查询某个评论是否存在(一个相对很快的操作),所以这样的结果并不很令人吃惊。
最后来到程序里用来调度抓取过程的进程(简单称之为“调度器”):
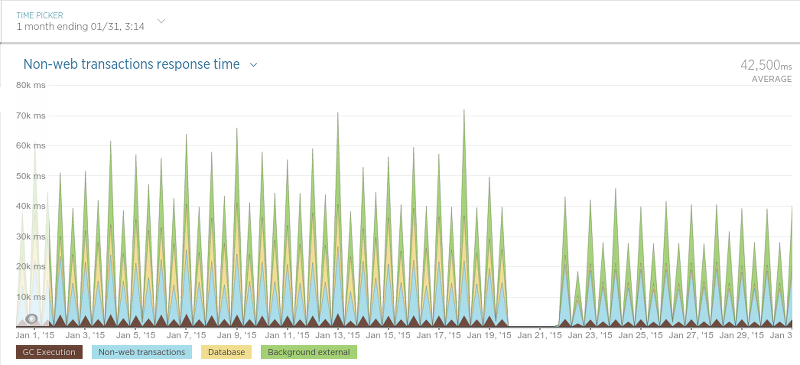
因为调度器只是以固定频度运行,这个图可能有点难以理解,但是不管怎样,在迁移之后有一个很清晰的平均处理时间的下降。










