| 本博文出自51CTO博客gaochaojs博主,有任何问题请进入博主页面互动讨论! |
如前几次博文中所述,流程结束后的实例信息可以通过统一的入口即高级查询(可以导出excel,也预留了生成各种报表的接口)查询。但对于一些特殊的工作流,比如转正、离职、考勤等我们也提供了专门的查询模块。比如本文中所述的离职模块:离职模块共分三个部分,分别为离职信息新增、审批中离职、已结束离职三个子模块。离职信息新增功能主要是针对被动离职,也即单位劝退、辞退或单方面解除合同的离职信息新增,此类离职一旦保存即可认为是已结束离职,所以不像审批中离职查询逻辑中十分清晰,已结束离职需要关联多表进行查询。在测试系统中进行测试时,我们发现直接执行已结束离职查询sql,在数据量为17条时,约1s,实际较慢,但尚可接受。该功能在正式系统上线后,离职数据约400条,用户简单在前端计时,约需十余秒等待,用户体验已经极差。拿出该查询sql,如下:
- SELECT *
- (SELECT DISTINCT leaveinfo.id, f_sqrgh, f_sqrbm, f_sqr, f_sqbmbm
- , f_sqbm, f_lxdhfj, f_sjhm, f_sqrq, f_rzrq
- , f_ndlzrq, f_qrlzrq, f_zw, f_gw, f_gwlx
- , f_gwcj, f_szdq, f_gzdd, f_lzyy, f_lzyyzs
- , f_yggxbmtjl, f_lzlx, f_inputtype, belongCompany, postDirection
- , techLevel, idCard, staffinfo.sex, staffinfo.birthday, exec.id AS 'processExecutionId'
- , exec.status AS 'processExecutionStatus', exec.formDefineId, exec.processDefineId, exec.processInstanceId, exec.tableName
- , process.`name` AS 'processDefineName'
- FROM T_DYMC_20140625100255 leaveinfo LEFT JOIN t_per_staffinfo staffinfo ON staffinfo.staffId = leaveinfo.f_sqrgh LEFT JOIN t_bpm_process_execution exec ON exec.pkValue = leaveinfo.id LEFT JOIN t_bpm_process_define process ON process.id = exec.processDefineId
- WHERE leaveinfo.f_sqrgh = staffinfo.staffId
- AND (exec.`status` = 2
- AND leaveinfo.f_inputtype = 'FLOW'
- OR leaveinfo.f_inputtype = 'MANUAL')
- ) allData LEFT JOIN t_sys_user sysUser ON allData.f_sqrgh = sysUser.staffId
这是一个分页查询,查询出所有结果的数量,如下:
- SELECT COUNT(DISTINCT allData.id)
- FROM (SELECT DISTINCT leaveinfo.id, leaveinfo.f_sqrgh
- FROM T_DYMC_20140625100255 leaveinfo LEFT JOIN t_per_staffinfo staffinfo ON staffinfo.staffId = leaveinfo.f_sqrgh LEFT JOIN t_bpm_process_execution exec ON exec.pkValue = leaveinfo.id LEFT JOIN t_bpm_process_define process ON process.id = exec.processDefineId
- WHERE leaveinfo.f_sqrgh = staffinfo.staffId
- AND (exec.`status` = 2
- AND leaveinfo.f_inputtype = 'FLOW'
- OR leaveinfo.f_inputtype = 'MANUAL')
- ) allData LEFT JOIN t_sys_user sysUser ON allData.f_sqrgh = sysUser.staffId
在测试系统我们对两条sql在17条数据时分别进行了测试,耗时都在0.5s以下。但在正式系统,测试时数据量398条时,***条的执行时间约为9.313s,第二条耗时约4.341s。
显然,398条数据仅查询就超过10s显然超过了用户的忍耐,大大影响了系统的性能,在用户体验大打折扣。
首先我们梳理一下sql,以***条为例,我们关联查询了多张表,而这多张表是否必要,是否有从逻辑角度优化的可能。
我们查询的主表是离职信息表,关联了档案、运行、流程定义三张表,***又增加了前文提出的数据权限限制,关联到用户表。关联档案我们是希望通过档案查询出离职人员的信息,关联运行表信息则是希望查询出当前办理者和当前办理阶段,关于流程定义表则是希望查询出流程定义的名称。经过分析,我们首先发现这个sql是工程师从高级查询里照搬过来的,因为高级查询应用于所有流程,流程名需要通过processDefineId查询,而我们的离职查询,就是查询的离职流程,不需要再关联一张表去查询。我们将这一关联去掉,直接返回"离职流程" as processDefineName。
去掉这一关联,sql的效率有所改善,但改善并不明显。从逻辑角度我们已经没有优化的空间。所以希望从数据库技术角度去进行优化。在着手进行优化之前,我们先看一看当前语句已经使用的优化技术(对于非专业DBA首先可以想到的优化一般是index),而在mysql里提供了explain来查询mysql如何使用索引来处理select语句以及连接表。下面,我们看看在未优化之前,在该查询语句是不是有用优化技术,又使用了哪些优化技术。在未进行优化之前,我们已经有了针对档案和用户两张表的staffid的索引,查询索引的sql语句如下:
- show index from t_per_staffinfo
如下图:

以及user表的索引:
![]()
查询语句中还有两张表分别为t_bpm_process_define和t_bpm_process_execution,我们为其创建索引,希望加入索引后查询效率有所改善:
- ALTER TABLE t_bpm_process_execution ADD INDEX pkValue_index (pkValue);
类似的我们为状态status,以及t_bpm_process_define也加入了索引。
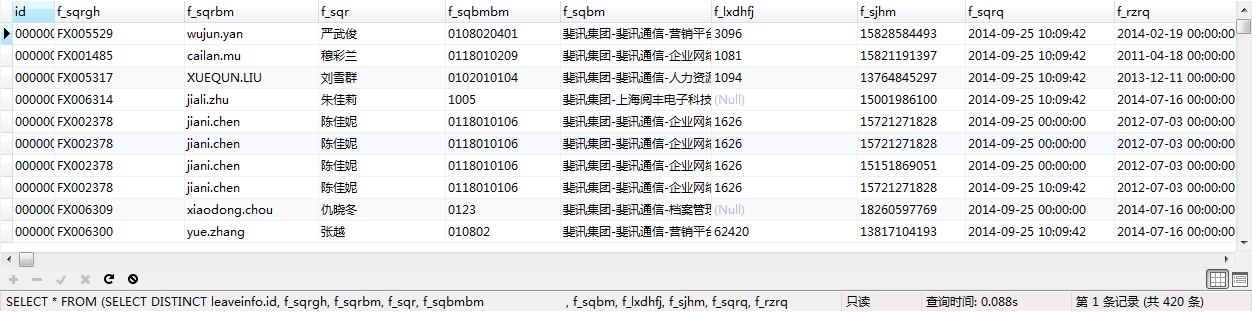
现在我们用explain看看我们目前的查询语句,如下图:

基于上图我们看一下,使用explain查出的信息中的各列的含义,顾名思义,我们看下来,table指的是查询的表名、type指的是连接使用的哪种类型(从好到差的连接类型依次是const、eq_reg、ref、range、index、all)、possible_key表示可能使用在该表中的索引、key指的是在本次查询中实际使用到的索引(如果值为null表示没有使用索引,mysql在很少情况下会使用未优化的索引,但也可以使用using idex强制使用索引)、key_len表示索引长度(在不损失精度的前提下,长度越短越好)、ref则是哪一列使用了索引、rows是MySQL认为需要检查的用来请求返回数据的长度、Extra表示关于解析查询的额外信息。通过分析Extra,我们可以看出哪些index需要优化以及如何优化。
Extra的值有Distinct、Not Exist、Range cheched for each record、using filesort、using temporary、Using index、where used、system、const、eq_ref、ref、index、all。当出现using filesort(需要额外的步骤进行排序)、using temporary(需要临时表存储中间结果)时表示查询需要进行优化。
由图中我们可以看出,一些索引还需要进一步优化,但我们查询的速率已经由近10s缩减为0.088s。对于非专业的DBA这次优化已经算是成功了。优化到此结束,关于更进一步优化using temporary的问题我会进一步与DBA沟通,将优化进行到底。
接下来,我们谈一下查询的基础理论、索引对于查询的改善和和索引的基础知识。
对于MySQL的查询机制,MySQL manual(7.2.1)中一段这样的描述:
| “The tables are listed in the output in the order that MySQL would read them while processing the query. MySQL resolves all joins using a single-sweep multi-join method. This means that MySQL reads a row from the first table, then finds a matching row in the second table, then in the third table, and so on. When all tables are processed, MySQL outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.” |
我们从第三句开始做一下简单的翻译:Mysql从***张表读取***行数据,然后在第二张表中查找匹配行,然后在查找第三张表,以此类推。当所有表处理完毕,Mysql输出选中的列然后回溯表的列表一直到能够匹配更多行的表出现。从这张表中读取下一行,然后继续查询下一张表。这个关联查询的过程的关键就是从上一张表来查询当前表的内容。
了解到从上一张表查询当前表的原理后,我们创建index的目的就是告诉MySQL如何直接查询下一张表的数据,以及如何按照需要的顺序来join下一张表。
上文中我们也介绍了查看和创建索引的语句,更进一步了解其他操作方法可以查看一些关于索引的基础知识。