继云计算之后,大数据(Big Data)接棒成为最热门的科技潮字,和大数据有关的技术和科技接二连三成为科技圈注目的焦点。如果你也关注云端跟大数据的资讯,Hadoop 这个字出现频率一定挺高的,这个黄色小象 Logo 也应该经常亮相。

究竟 Hadoop 是什么?能够用来解决什么问题?又为什么重要?比起解释一大堆技术上的细节,倒不如把重点放在 Hadoop 处理巨量资料的角度切入了解,看 Hadoop 能够带来什么好处,同时也从这个方向反过来理解大数据。
Hadoop 的雏形 Nutch 最初是由 Doug Cutting 和 Mike Cafarella 针对网页相关的资料搜寻而开发,2006 年 Doug Cutting 进入 Yahoo 后成立了专业的团队继续研究发展这项技术,正式命名为 Hadoop。
Hadoop 这个名称并不代表任何英文字汇或者缩写代号,「Hadoop」来自于 Doug Cutting 儿子的一个黄色大象填充玩具1,主要塬因是开发过程中他需要为这套软体提供一个代号方便沟通,而 Hadoop 这个名字发音简单拼字容易,而且毫无意义、也没有在任何地方使用过,因此雀屏中选,黄色小象也因而成为 Hadoop 的标誌。
值得一提的是,在 Hadoop 之后所发展的几个相关软件和模组也都参考了这样的命名方式,名称不会与主要功能实际相关,而是採用与大象或其他动物有关的名称作为其开发代号,像是 Pig、Hive、ZooKeeper 等等。
什么是 Hadoop?
首先,想像有个档案大小超过 PC 能够储存的容量,那便无法储存在你的电脑裡,对吧?
Hadoop 不但让你储存超过一个伺服器所能容纳的超大档案,还能同时储存、处理、分析几千几万份这种超大档案,所以每每提到大数据,便会提到 Hadoop 这套技术。
简单来说,Hadoop 是一个能够储存并管理大量资料的云端平台,为 Apache 软体基金会底下的一个开放塬始码、社群基础、而且完全免费的软体,被各种组织和产业广为採用,非常受欢迎。
#p#
然而要懂 Hadoop,你必须先了解它最主要的两项功能:
Hadoop 如何储存资料(Store)
Hadoop 怎么处理资料(Process)
分散式档案系统 HDFS
Hadoop 是一个丛集系统(cluster system),也就是由单一伺服器扩充到数以千计的机器,整合应用起来像是一台超级电脑。而资料存放在这个丛集中的方式则是採用 HDFS 分散式档案系统(Hadoop Distributed File System)。
HDFS 的设计概念是这样的,丛集系统中有数以千计的节点用来存放资料,如果把一份档案想成一份藏宝图,机器中会有一个机器老大(Master Node)跟其他机器小弟(Slave/Worker Node),为了妥善保管藏宝图,先将它分割成数小块(block),通常每小块的大小是 64 MB,而且把每小块拷贝成叁份(Data replication),再将这些小块分散给小弟们保管。机器小弟们用「DataNode」这个程式来放藏宝图,机器老大则用「NameNode」这个程式来监视所有小弟们藏宝图的存放状态。
如果老大的程式 NameNode 发现有哪个 DataNode 上的藏宝图遗失或遭到损坏(例如某位小弟不幸阵亡,顺带藏宝图也丢了),就会寻找其他 DataNode 上的副本(Replica)进行复製,保持每小块的藏宝图在整个系统都有叁份的状态,这样便万无一失。
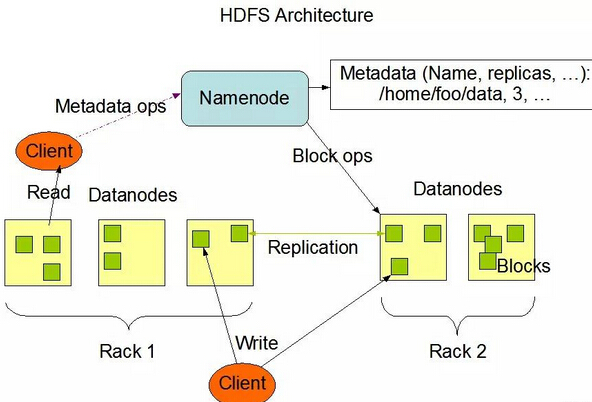
透过 HDFS,Hadoop 能够储存上看 TB(Tera Bytes)甚至 PB(Peta Bytes)等级的巨量资料,也不用担心单一档案的大小超过一个磁碟区的大小,而且也不用担心某个机器损坏导致资料遗失。
来看看 Yahoo 的 Hadoop cluster 系统:
MapReduce 平行运算架构
上一段提到,HDFS 将资料分散储存在 Hadoop 电脑丛集中的数个机器裡,现在我们要谈谈 Hadoop 如何用 MapReduce 这套技术处理这些节点上的资料。
在函数程式设计(Functional programming)3中很早就有了 Map(映射)和 Reduce(归纳)的观念,类似于演算法中个别击破(Divide and Conquer)的作法,也就是将问题分解成很多个小问题之后再做总和。
MapReduce 顾名思义是以 Map 跟 Reduce 为基础的应用程式。一般我们进行资料分析处理时,是将整个档案丢进程式软体中做运算出结果,而面对巨量资料时,Hadoop 的做法是採用分散式计算的技术处理各节点上的资料。
在各个节点上处理资料片段,把工作分散、分佈出去的这个阶段叫做 Mapping;接下来把各节点运算出的结果直接传送回来归纳整合,这个阶段就叫做 Reducing。这样多管齐下、在上千台机器上平行处理巨量资料,可以大大节省资料处理的时间。
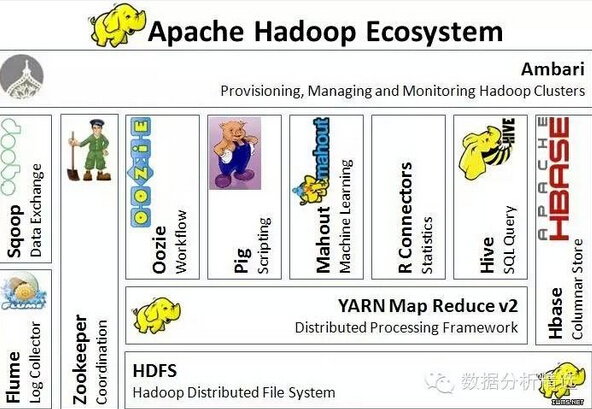
黄色小象以及小象的朋友们
总和来看,Hadoop 透过 HDFS 和 MapReduce 这两项核心功能,解决了档案存放的问题、解决了系统扩张的问题、解决了系统备份的问题、解决了资料处理的问题,非常适合应用于大数据储存和大数据分析,因此被广泛接受成为大数据的主流技术。
当然 Hadoop 并没有解决所有巨量资料带来的难题,所以许多与 Hadoop 相关的技术被开发来应付巨量资料的其他需求4。像是用来处理资料的 script 语言「Pig」、类似 SQL 语法查询功能的「Hive」、专门用在 Hadoop 上的资料库系统「HBase」等。
Hadoop 生态系:
对 Hadoop 有初步的认识后,如果想进一步学习相关的大数据技术,可以参考《成为大数据时代的精英学子:Big Data 的推荐好课!》一文,其中列出了许多线上的 Hadoop 推荐好课。