













背景大家都懂的,要过年了,正是红包满天飞的日子。正巧前两天学会了Python,比较亢奋,就顺便研究了研究微博红包的爬取,为什么是微博红包而不是支付宝红包呢,因为我只懂Web,如果有精力的话之后可能也会研究研究打地鼠算法吧。
因为本人是初学Python,这个程序也是学了Python后写的第三个程序,所以代码中有啥坑爹的地方请不要当面戳穿,重点是思路,嗯,如果思路中有啥坑爹的的地方也请不要当面戳穿,你看IE都有脸设置自己为默认浏览器,我写篇渣文得瑟得瑟也是可以接受的对吧……
我用的是Python 2.7,据说Python 2和Python 3差别挺大的,比我还菜的小伙伴请注意。
0×01 思路整理
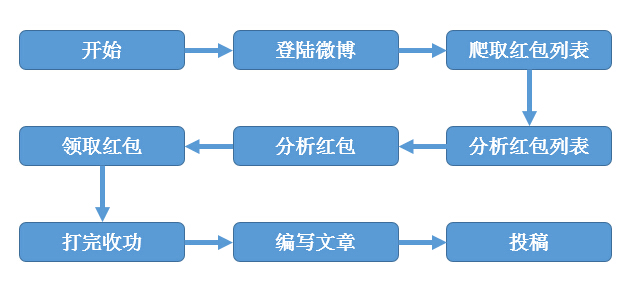
懒得文字叙述了,画了张草图,大家应该可以看懂。
首先老规矩,先引入一坨不知道有啥用但又不能没有的库:
- import re
- import urllib
- import urllib2
- import cookielib
- import base64
- import binascii
- import os
- import json
- import sys
- import cPickle as p
- import rsa
然后顺便声明一些其它变量,以后需要用到:
- reload(sys)
- sys.setdefaultencoding('utf-8&') #将字符编码置为utf-8
- luckyList=[] #红包列表
- lowest=10 #能忍受红包领奖记录最低为多少
这里用到了一个rsa库,Python默认是不自带的,需要安装一下:https://pypi.python.org/pypi/rsa/
下载下来后运行setpy.py install安装,然后就可以开始我们的开发步骤了。
0×02 微博登陆
抢红包的动作一定要登陆后才可以进行的,所以一定要有登录的功能,登录不是关键,关键是cookie的保存,这里需要cookielib的配合。
- cj = cookielib.CookieJar()
- opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
- urllib2.install_opener(opener)
这样凡是使用opener进行的网络操作都会对处理cookie的状态,虽然我也不太懂但是感觉好神奇的样子。
接下来需要封装两个模块,一个是获取数据模块,用来单纯地GET数据,另一个用来POST数据,其实只是多了几个参数,完全可以合并成一个函数,但是我又懒又笨,不想也不会改代码。
- def getData(url) :
- try:
- req = urllib2.Request(url)
- result = opener.open(req)
- text = result.read()
- text=text.decode("utf-8").encode("gbk",'ignore')
- return text
- except Exception, e:
- print u'请求异常,url:'+url
- print e
- def postData(url,data,header) :
- try:
- data = urllib.urlencode(data)
- req = urllib2.Request(url,data,header)
- result = opener.open(req)
- text = result.read()
- return text
- except Exception, e:
- print u'请求异常,url:'+url
有了这两个模块我们就可以GET和POST数据了,其中getData中之所以decode然后又encode啥啥的,是因为在Win7下我调试输出的时候总乱码,所以加了些编码处理,这些都不是重点,下面的login函数才是微博登陆的核心。
- def login(nick , pwd) :
- print u"----------登录中----------"
- print "----------......----------"
- prelogin_url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.15)&_=1400822309846' % nick
- preLogin = getData(prelogin_url)
- servertime = re.findall('"servertime":(.+?),' , preLogin)[0]
- pubkey = re.findall('"pubkey":"(.+?)",' , preLogin)[0]
- rsakv = re.findall('"rsakv":"(.+?)",' , preLogin)[0]
- nonce = re.findall('"nonce":"(.+?)",' , preLogin)[0]
- #print bytearray('xxxx','utf-8')
- su = base64.b64encode(urllib.quote(nick))
- rsaPublickey= int(pubkey,16)
- key = rsa.PublicKey(rsaPublickey,65537)
- message = str(servertime) +'\t' + str(nonce) + '\n' + str(pwd)
- sp = binascii.b2a_hex(rsa.encrypt(message,key))
- header = {'User-Agent' : 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)'}
- param = {
- 'entry': 'weibo',
- 'gateway': '1',
- 'from': '',
- 'savestate': '7',
- 'userticket': '1',
- 'ssosimplelogin': '1',
- 'vsnf': '1',
- 'vsnval': '',
- 'su': su,
- 'service': 'miniblog',
- 'servertime': servertime,
- 'nonce': nonce,
- 'pwencode': 'rsa2',
- 'sp': sp,
- 'encoding': 'UTF-8',
- 'url': 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
- 'returntype': 'META',
- 'rsakv' : rsakv,
- }
- s = postData('http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)',param,header)
- try:
- urll = re.findall("location.replace\(\'(.+?)\'\);" , s)[0]
- login=getData(urll)
- print u"---------登录成功!-------"
- print "----------......----------"
- except Exception, e:
- print u"---------登录失败!-------"
- print "----------......----------"
- exit(0)
这里面的参数啊加密算法啊都是从网上抄的,我也不是很懂,大概就是先请求个时间戳和公钥再rsa加密一下最后处理处理提交到新浪登陆接口,从新浪登录成功之后会返回一个微博的地址,需要请求一下,才能让登录状态彻底生效,登录成功后,后面的请求就会带上当前用户的cookie。
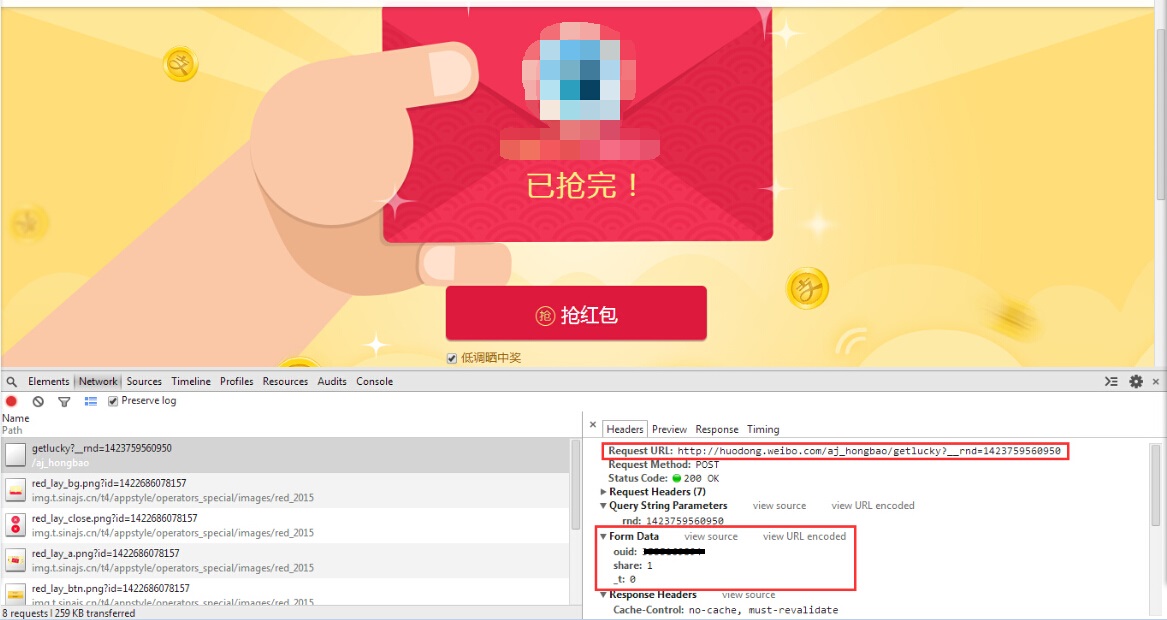
成功登录微博后,我已迫不及待地想找个红包先试一下子,当然首先是要在浏览器里试的。点啊点啊点啊点的,终于找到了一个带抢红包按钮的页面了,F12召唤出调试器,看看数据包是咋请求的。
可以看到请求的地址是http://huodong.weibo.com/aj_hongbao/getlucky,主要参数有两个,一个是ouid,就是红包id,在URL中可以看到,另一个share参数决定是否分享到微博,还有个_t不知道是干啥用的。
好,现在理论上向这个url提交者三个参数,就可以完成一次红包的抽取,但是,当你真正提交参数的时候,就会发现服务器会很神奇地给你返回这么个串:
- 1
- {"code":303403,"msg":"抱歉,你没有权限访问此页面","data":[]}
这个时候不要惊慌,根据我多年Web开发经验,对方的程序员应该是判断referer了,很简单,把请求过去的header全给抄过去。
- def getLucky(id): #抽奖程序
- print u"---抽红包中:"+str(id)+"---"
- print "----------......----------"
- if checkValue(id)==False: #不符合条件,这个是后面的函数
- return
- luckyUrl="http://huodong.weibo.com/aj_hongbao/getlucky"
- param={
- 'ouid':id,
- 'share':0,
- '_t':0
- }
- header= {
- 'Cache-Control':'no-cache',
- 'Content-Type':'application/x-www-form-urlencoded',
- 'Origin':'http://huodong.weibo.com',
- 'Pragma':'no-cache',
- 'Referer':'http://huodong.weibo.com/hongbao/'+str(id),
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 BIDUBrowser/6.x Safari/537.36',
- 'X-Requested-With':'XMLHttpRequest'
- }
- res = postData(luckyUrl,param,header)
这样的话理论上就没啥问题了,事实上其实也没啥问题。抽奖动作完成后我们是需要判断状态的,返回的res是一个json串,其中code为100000时为成功,为90114时是今天抽奖达到上限,其他值同样是失败,所以:
- hbRes=json.loads(res)
- if hbRes["code"]=='901114': #今天红包已经抢完
- print u"---------已达上限---------"
- print "----------......----------"
- log('lucky',str(id)+'---'+str(hbRes["code"])+'---'+hbRes["data"]["title"])
- exit(0)
- elif hbRes["code"]=='100000':#成功
- print u"---------恭喜发财---------"
- print "----------......----------"
- log('success',str(id)+'---'+res)
- exit(0)
- if hbRes["data"] and hbRes["data"]["title"]:
- print hbRes["data"]["title"]
- print "----------......----------"
- log('lucky',str(id)+'---'+str(hbRes["code"])+'---'+hbRes["data"]["title"])
- else:
- print u"---------请求错误---------"
- print "----------......----------"
- log('lucky',str(id)+'---'+res)
其中log也是我自定义的一个函数,用来记录日志用的:
- def log(type,text):
- fp = open(type+'.txt','a')
- fp.write(text)
- fp.write('\r\n')
- fp.close()
0×04 爬取红包列表
单个红包领取动作测试成功后,就是我们程序的核心大招模块了——爬取红包列表,爬取红包列表的方法和入口应该有不少,比如各种微博搜索关键字啥啥的,不过我这里用最简单的方法:爬取红包榜单。
在红包活动的首页(http://huodong.weibo.com/hongbao)通过各种点更多,全部可以观察到,虽然列表连接很多,但可以归纳为两类(最有钱红包榜除外):主题和排行榜。
继续召唤F12,分析这两种页面的格式,首先是主题形式的列表,比如:http://huodong.weibo.com/hongbao/special_quyu
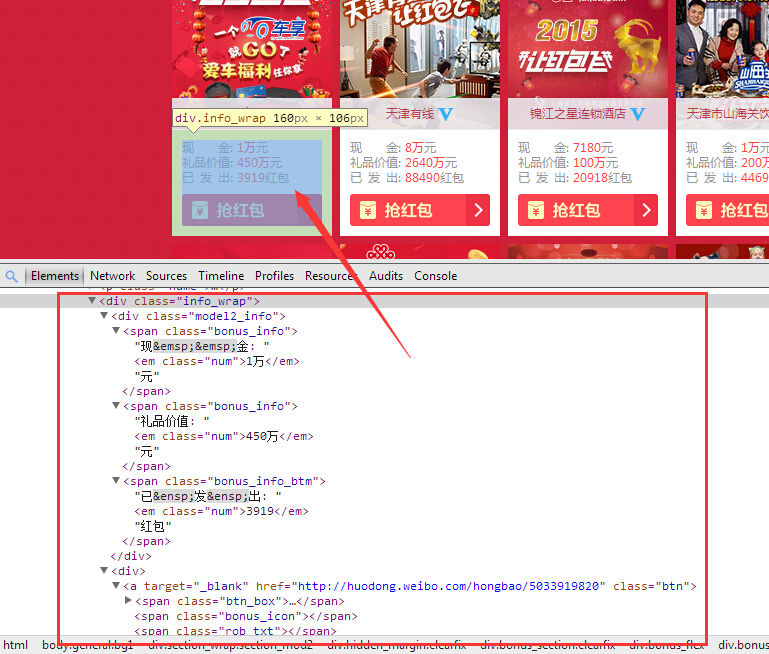
可以看到红包的信息都是在一个类名为info_wrap的div中,那么我们只要活动这个页面的源码,然后把infowrap全抓出来,再简单处理下就可以得到这个页面的红包列表了,这里需要用到一些正则:
- def getThemeList(url,p):#主题红包
- print u"---------第"+str(p)+"页---------"
- print "----------......----------"
- html=getData(url+'?p='+str(p))
- pWrap=re.compile(r'(.+?)',re.DOTALL) #h获取所有info_wrap的正则
- pInfo=re.compile(r'.+(.+).+(.+).+(.+).+href="(.+)" class="btn"',re.DOTALL) #获取红包信息
- List=pWrap.findall(html,re.DOTALL)
- n=len(List)
- if n==0:
- return
- for i in range(n): #遍历所有info_wrap的div
- s=pInfo.match(List[i]) #取得红包信息
- info=list(s.groups(0))
- info[0]=float(info[0].replace('\xcd\xf2','0000')) #现金,万->0000
- try:
- info[1]=float(info[1].replace('\xcd\xf2','0000')) #礼品价值
- except Exception, e:
- info[1]=float(info[1].replace('\xd2\xda','00000000')) #礼品价值
- info[2]=float(info[2].replace('\xcd\xf2','0000')) #已发送
- if info[2]==0:
- info[2]=1 #防止除数为0
- if info[1]==0:
- info[1]=1 #防止除数为0
- info.append(info[0]/(info[2]+info[1])) #红包价值,现金/(领取人数+奖品价值)
- # if info[0]/(info[2]+info[1])>100:
- # print url
- luckyList.append(info)
- if 'class="page"' in html:#存在下一页
- p=p+1
- getThemeList(url,p) #递归调用自己爬取下一页
话说正则好难,学了好久才写出来这么两句。还有这里的info中append进去了一个info[4],是我想的一个大概判断红包价值的算法,为什么要这么做呢,因为红包很多但是我们只能抽四次啊,在茫茫包海中,我们必须要找到最有价值的红包然后抽丫的,这里有三个数据可供参考:现金价值、礼品价值和领取人数,很显然如果现金很少领取人数很多或者奖品价值超高(有的甚至丧心病狂以亿为单位),那么就是不值得去抢的,所以我憋了半天终于憋出来一个衡量红包权重的算法:红包价值=现金/(领取人数+奖品价值)。
排行榜页面原理一样,找到关键的标签,正则匹配出来。
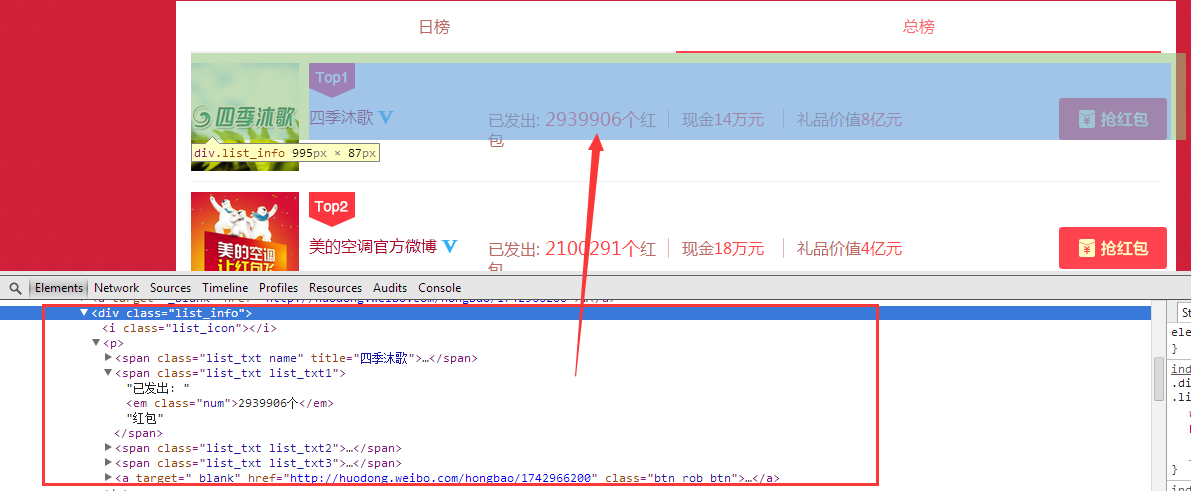
- def getTopList(url,daily,p):#排行榜红包
- print u"---------第"+str(p)+"页---------"
- print "----------......----------"
- html=getData(url+'?daily='+str(daily)+'&p='+str(p))
- pWrap=re.compile(r'(.+?)',re.DOTALL) #h获取所有list_info的正则
- pInfo=re.compile(r'.+(.+).+(.+).+(.+).+href="(.+)" class="btn rob_btn"',re.DOTALL) #获取红包信息
- List=pWrap.findall(html,re.DOTALL)
- n=len(List)
- if n==0:
- return
- for i in range(n): #遍历所有info_wrap的div
- s=pInfo.match(List[i]) #取得红包信息
- topinfo=list(s.groups(0))
- info=list(topinfo)
- info[0]=topinfo[1].replace('\xd4\xaa','') #元->''
- info[0]=float(info[0].replace('\xcd\xf2','0000')) #现金,万->0000
- info[1]=topinfo[2].replace('\xd4\xaa','') #元->''
- try:
- info[1]=float(info[1].replace('\xcd\xf2','0000')) #礼品价值
- except Exception, e:
- info[1]=float(info[1].replace('\xd2\xda','00000000')) #礼品价值
- info[2]=topinfo[0].replace('\xb8\xf6','') #个->''
- info[2]=float(info[2].replace('\xcd\xf2','0000')) #已发送
- if info[2]==0:
- info[2]=1 #防止除数为0
- if info[1]==0:
- info[1]=1 #防止除数为0
- info.append(info[0]/(info[2]+info[1])) #红包价值,现金/(领取人数+礼品价值)
- # if info[0]/(info[2]+info[1])>100:
- # print url
- luckyList.append(info)
- if 'class="page"' in html:#存在下一页
- p=p+1
- getTopList(url,daily,p) #递归调用自己爬取下一页
好,现在两中专题页的列表我们都可以顺利爬取了,接下来就是要得到列表的列表,也就是所有这些列表地址的集合,然后挨个去抓:
- def getList():
- print u"---------查找目标---------"
- print "----------......----------"
- themeUrl={ #主题列表
- 'theme':'http://huodong.weibo.com/hongbao/theme',
- 'pinpai':'http://huodong.weibo.com/hongbao/special_pinpai',
- 'daka':'http://huodong.weibo.com/hongbao/special_daka',
- 'youxuan':'http://huodong.weibo.com/hongbao/special_youxuan',
- 'qiye':'http://huodong.weibo.com/hongbao/special_qiye',
- 'quyu':'http://huodong.weibo.com/hongbao/special_quyu',
- 'meiti':'http://huodong.weibo.com/hongbao/special_meiti',
- 'hezuo':'http://huodong.weibo.com/hongbao/special_hezuo'
- }
- topUrl={ #排行榜列表
- 'mostmoney':'http://huodong.weibo.com/hongbao/top_mostmoney',
- 'mostsend':'http://huodong.weibo.com/hongbao/top_mostsend',
- 'mostsenddaka':'http://huodong.weibo.com/hongbao/top_mostsenddaka',
- 'mostsendpartner':'http://huodong.weibo.com/hongbao/top_mostsendpartner',
- 'cate':'http://huodong.weibo.com/hongbao/cate?type=',
- 'clothes':'http://huodong.weibo.com/hongbao/cate?type=clothes',
- 'beauty':'http://huodong.weibo.com/hongbao/cate?type=beauty',
- 'fast':'http://huodong.weibo.com/hongbao/cate?type=fast',
- 'life':'http://huodong.weibo.com/hongbao/cate?type=life',
- 'digital':'http://huodong.weibo.com/hongbao/cate?type=digital',
- 'other':'http://huodong.weibo.com/hongbao/cate?type=other'
- }
- for (theme,url) in themeUrl.items():
- print "----------"+theme+"----------"
- print url
- print "----------......----------"
- getThemeList(url,1)
- for (top,url) in topUrl.items():
- print "----------"+top+"----------"
- print url
- print "----------......----------"
- getTopList(url,0,1)
- getTopList(url,1,1)
0×05 判断红包可用性
这个是比较简单的,首先在源码里搜一下关键字看看有没有抢红包按钮,然后再到领取排行里面看看最高纪录是多少,要是最多的才领那么几块钱的话就再见吧……
其中查看领取记录的地址为http://huodong.weibo.com/aj_hongbao/detailmore?page=1&type=2&_t=0&__rnd=1423744829265&uid=红包id
- def checkValue(id):
- infoUrl='http://huodong.weibo.com/hongbao/'+str(id)
- html=getData(infoUrl)
- if 'action-type="lottery"' in html or True: #存在抢红包按钮
- logUrl="http://huodong.weibo.com/aj_hongbao/detailmore?page=1&type=2&_t=0&__rnd=1423744829265&uid="+id #查看排行榜数据
- param={}
- header= {
- 'Cache-Control':'no-cache',
- 'Content-Type':'application/x-www-form-urlencoded',
- 'Pragma':'no-cache',
- 'Referer':'http://huodong.weibo.com/hongbao/detail?uid='+str(id),
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 BIDUBrowser/6.x Safari/537.36',
- 'X-Requested-With':'XMLHttpRequest'
- }
- res = postData(logUrl,param,header)
- pMoney=re.compile(r'< span class="money">(\d+?.+?)\xd4\xaa< /span>',re.DOTALL) #h获取所有list_info的正则
- luckyLog=pMoney.findall(html,re.DOTALL)
- if len(luckyLog)==0:
- maxMoney=0
- else:
- maxMoney=float(luckyLog[0])
- if maxMoney< lowest: #记录中最大红包小于设定值
- return False
- else:
- print u"---------手慢一步---------"
- print "----------......----------"
- return False
- return True
0×06 收尾工作
主要的模块都已经搞定,现在需要将所有的步骤串联起来:
- def start(username,password,low,fromFile):
- gl=False
- lowest=low
- login(username , password)
- if fromfile=='y':
- if os.path.exists('luckyList.txt'):
- try:
- f = file('luckyList.txt')
- newList = []
- newList = p.load(f)
- print u'---------装载列表---------'
- print "----------......----------"
- except Exception, e:
- print u'解析本地列表失败,抓取在线页面。'
- print "----------......----------"
- gl=True
- else:
- print u'本地不存在luckyList.txt,抓取在线页面。'
- print "----------......----------"
- gl=True
- if gl==True:
- getList()
- from operator import itemgetter
- newList=sorted(luckyList, key=itemgetter(4),reverse=True)
- f = file('luckyList.txt', 'w')
- p.dump(newList, f) #把抓到的列表存到文件里,下次就不用再抓了
- f.close()
- for lucky in newList:
- if not 'http://huodong.weibo.com' in lucky[3]: #不是红包
- continue
- print lucky[3]
- id=re.findall(r'(\w*[0-9]+)\w*',lucky[3])
- getLucky(id[0])
因为每次测试的时候都要重复爬取红包列表,很麻烦,所以加了段将完整列表dump到文件的代码,这样以后就可以读本地列表然后抢红包了,构造完start模块后,写一个入口程序把微博账号传过去就OK了:
- if __name__ == "__main__":
- print u"------------------微博红包助手------------------"
- print "---------------------v0.0.1---------------------"
- print u"-------------by @无所不能的魂大人----------------"
- print "-------------------------------------------------"
- try:
- uname=raw_input(u"请输入微博账号: ".decode('utf-8').encode('gbk'))
- pwd=raw_input(u"请输入微博密码: ".decode('utf-8').encode('gbk'))
- low=int(raw_input(u"红包领取最高现金大于n时参与: ".decode('utf-8').encode('gbk')))
- fromfile=raw_input(u"是否使用luckyList.txt中红包列表:(y/n) ".decode('utf-8').encode('gbk'))
- except Exception, e:
- print u"参数错误"
- print "----------......----------"
- print e
- exit(0)
- print u"---------程序开始---------"
- print "----------......----------"
- start(uname,pwd,low,fromfile)
- print u"---------程序结束---------"
- print "----------......----------"
- os.system('pause')
0×07 走你!
基本的爬虫骨架已经基本可以完成了,其实这个爬虫的很多细节上还是有很大发挥空间的,比如改装成支持批量登录的,比如优化下红包价值算法,代码本身应该也有很多地方可以优化的,不过以我的能力估计也就能搞到这了。
最后程序的结果大家都看到了,我写了几百行代码,几千字的文章,辛辛苦苦换来的只是一组双色球,尼玛坑爹啊,怎么会是双色球呢!!!(旁白:作者越说越激动,居然哭了起来,周围人纷纷劝说:兄弟,不至于的,不就是个微博红包么,昨天手都撸酸了也没摇出个微信红包。)
唉,其实我不是哭这个,我难过的是我已经二十多岁了,还在做写程序抓微博红包这么无聊的事情,这根本不是我想要的人生啊!













