












过去的几个月我写了两篇文章,一篇是InnoDB 事务历史相关的危险债务,另一篇是关于MVCC 可能导致MySQL严重的性能问题的真相。在这篇文章里我将讨论一个相关的主题 – InnoDB 事务隔离模式,还有它们与MVCC(多版本并发控制)的关系,以及它们是如何影响MySQL性能的。
MySQL手册提供了一个关于MySQL支持的事务隔离模式的恰当描述 – 在这里我并不会再重复,而是聚焦到对性能的影响上。
SERIALIZABLE – 这是***的隔离模式,本质上打败了在锁管理(设置锁是很昂贵的)的条件下,多版本控制对所有选择进行锁定造成大量的开销,还有你得到的并发。这个模式仅在MySQL应用中非常特殊的情况下使用。
REPEATABLE READ – 这是默认的隔离级别,通常它是相当不错的,对应用程序的便捷性来说也不错。它在***次的时候读入所有数据 (假设使用标准的非锁读)。但是这有很高的代价 – InnoDB需要去维护事务记录,从一开始就要记录,它的代价是非常昂贵的。更为严重的情况是,程序频繁地更新和hot rows – 你真的就不想InnoDB去处理rows了,它有成百上千个版本。
在性能上的影响, 读和写都能够被影响。用select查询遍历多个行是代价高昂的,对于更新(update)也是,在MySQL 5.6中,尤其是版本控制看起来导致了严重的争用问题。
下面是例子:完全在内存中的数据集中运行 sysbench,并启动 transaction 、运行全表、扫描、查询几次,同时保持 transaction 是开着的:
sysbench --num-threads=64 --report-interval=10 --max-time=0 --max-requests=0 --rand-type=pareto --oltp-table-size=80000000 --mysql-user=root --mysql-password= --mysql-db=sbinnodb --test=/usr/share/doc/sysbench/tests/db/update_index.lua run
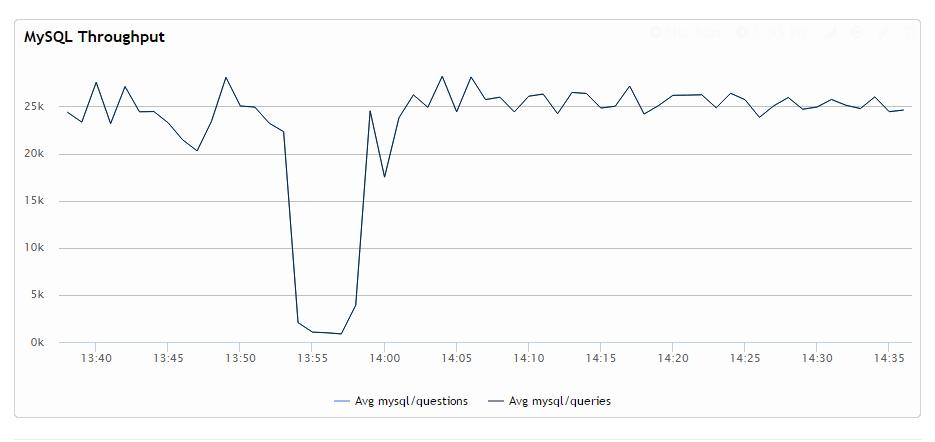
正如你可以看到的,写(write )操作的吞吐量大幅下降,并且持续走低,这时transaction 是开着的,不仅是在查询(query)操作运行的时候。在可复读的隔离模式下,当你已经选择了之外的transaction ,紧接着就是一个long transaction ,这也许是我能找到的最糟糕情况了。当然了你也会在其他情况下看到回归算法(regression )。
如果有人想测试,可以重复下面我用的查询集合:
READ UNCOMMITTED – 我觉得这是最难理解的隔离模式(悲催的只有2条文档),只描述了它的逻辑观点。如果你使用了这种隔离模式,你会看到数据控中所有发生的变化,即使是那些还没被提交的transactions 。这种隔离模式一种好的用例是:你能“watch”到大规模的有脏读(dirty reads)的UPDATE 语句,显示了哪行被改变了,哪些没有改变。
如果transaction 事务在运行的时候出错了,那么这个声明会显示还没被提交的和可能没被提交的变化,所以使用这个模式要小心为妙。有一些用例虽然不需要我们100%准确的数据,在这种情况下,这种模式就变得非常方便。
- select avg(length(c)) from sbtest1;
- begin;
- select avg(length(c)) from sbtest1;
- select sleep(300);
- commit;
不只是可复读(Repeatable Read)的默认隔离级别,同样也可以用于InnoDB 逻辑备份 – mydumper 或者 mysqldump –single-transaction
这些结果显示这个备份的方法恢复的时间太长而不能用于大型数据集合,同样这个方法受到性能影响,也不能用于频繁写入(write )的环境中。
READ COMMITTED 模式和REPEATABLE READ模式很相似,本质区别在于哪个版本都不在transaction中从头开始读取,取而代之的从当前语句开始读取。因此使用这种模式允许InnoDB少维护很多版本,特别是你没有很长的statements要允运行。如果你有很长的select要运行,如报表查询对性能的影响仍然很严重。
通常我认为好的做法是把READ COMITTED隔离模式做为默认,对于应用程序或者transactions 有必要就改成REPEATABLE READ。
那么,从性能角度来看,如何体现READ UNCOMMITTED?理论上,InnoDB 可以清除行版本,在READ UNCOMMITTED模式下即便是该语句已经开始执行之后,也可以创建。在实践中,由于一个bug或者一些复杂实现的细节做不到,语句开始仍然是行版本。所以,如果你在READ UNCOMMITTED声明中运行很长的SELECT,你会得到大量的行版本创建信息,就像你用了READ COMMITTED。No win here。
从SELECT方面还有一个重要的win - READ UNCOMMITTED隔离模式意味着InnoDB 不需要去检查旧的行版本 - ***一行总是对的,这会使得性能有明显的改善,尤其是当undo空间已经在磁盘上溢出,查找旧的行版本会造成大量的IO读写。
也许上面这个select avg(k) from sbtest1;是我能找到的***的查询例子了,能与之类似的更新工作量。假使READ UNCOMMITTED隔离模式在一分钟左右完成,我认为在READ COMMITTED隔离模式下没有完成过,因为新索引条目插入的速度要比扫描速度快。
***思考:正确的使用InnoDB 隔离模式,能够让您的应用程序得到***性能。你得到的好处可能不同,在某些情况下,也可能没什么区别。关系到InnoDB 的历史版本,似乎好有好多工作要做,我希望在未来的MySQL中能解决。
英文原文:MySQL performance implications of InnoDB isolation modes
















