












虽然云服务商正在变得越来越可靠,但是部分服务商仍然出现了宕机故障。亚马逊AWS和谷歌云平台(Google Cloud Platform)对其IaaS[注](基础设施即服务[注])公有云[注]在2014年可靠性的统计数据让人印象深刻,因为这两家服务商正在接近被部分人认为是可用性的***目标——五个9(即99.999%)。
把时光倒退到2012年,专家们当时曾经感叹,云服务正饱受运行中断的困扰。当时有的宕机故障导致了Reddit等多家知名网站无法访问,而出现在平安夜的宕机故障则导致Netflix遭受到严重影响。不过,在刚刚过去的2014年,情况则发生了改观。
网站追踪公司CloudHarmony一直监测着48家云服务商的宕机故障频率。该公司首先在这些服务商中的每一家都运行一个网络服务器,然后追踪服务何时无法使用,***记录下宕机故障的发生次数和时长。这种办法虽然并不***,但是却可以很好地观察到这些服务商的服务运行情况。总体上,这些服务商的表现都不错,并且正做得越来越好。其中,亚马逊和谷歌的表现尤为出色。
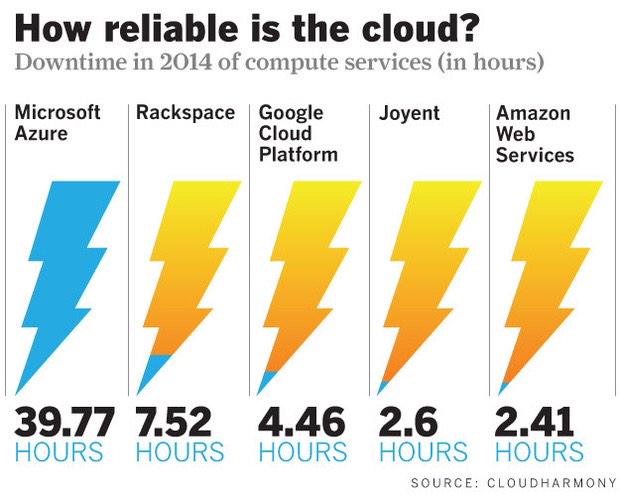
亚马逊的弹性计算云(EC2)在2014年共发生了20次宕机故障,累计宕机时长为2.41小时,这意味着亚马逊云服务的可靠性已得到大幅提升,正常运行时间百分率达到了99.9974%。研究机构Gartner在2014年预测称,亚马逊分布式系统的规模将是其竞争对手的五倍。就亚马逊AWS的规模而言,这样的可靠性数据已经非常了不起了。
或许谷歌云平台存储服务的正常运行时间更为引人注目。据CloudHarmony称,谷歌云平台存储服务在2014年宕机时长仅为14分钟。这意味着其正常运行时间百分率达到了99.9996%。
CloudHarmony的CEO Jason Read说:“越来越多的知名云服务商开始对他们的系统进行微调,以便让服务变得更加稳定。”亚马逊AWS提供云服务的时间比市场上任何一家服务商都要长;而谷歌在其云服务中使用的是现有基础设施,因此在管理高可靠性分布式系统方面,谷歌也拥有较长的追踪记录。
云服务商在2014年也各自遇到了一些问题。在虚拟化平台Xen的漏洞于2014年秋季被发现后,大约10%的AWS EC2实例必须被重启。Rackspace也在2014年秋季经历了一次大规模重启。微软的存储服务在2014年11月出现服务中断。Verizon在2015年刚开始就开局不利。该公司告诉客户称,由于计划性维护,2015年1月其云服务宕机时间最长可能将达到48小时。
微软的宕机事故导致其Azure云服务在可靠性方面成绩不佳。在计算方面,Microsoft Azure一共出现92次宕机故障,总计宕机时长39.77小时。其存储平台共出现了141次宕机故障,总计宕机时长10.97小时。与此形成鲜明对比的是,亚马逊AWS存储平台共出现了23次宕机故障,总计宕机时长2.69小时。对此,微软一直也没有进行过解释。
大多数服务商似乎正在努力提升自己的平台,但是他们最终能否在可用性方面达到运营商级别的99.999%的水平呢?咨询公司Redmonk的高级分析师Donnie Berkholz称,对CloudHarmony数据的深度观察显示(+本站微信networkworldweixin),部分云服务商在服务可用性方面已经实现了五个9。例如,谷歌的存储平台。AWS的部分服务区域(CloudHarmony在AWS云服务中监测着多个区域)在2014年仅有几分钟的宕机时长,有的甚至没有出现过宕机故障,这已经超过了五个9的水平。随着时间的流逝与规模的增长,云服务商似乎正变得越来越擅长提供服务。Berkholz指出,另一个有意思的发展趋势是,用户对于宕机故障的应对也变得越来越灵活。
尽管在2014年没有取得令人注目的正常运行时间百分率(Microsoft Azure的宕机时长为39小时,CenturyLink的宕机时长为26小时,Digital Ocean的宕机时长为16小时),但是部分云服务商(例如Microsoft Azure,以及相对较新的Digital Ocean)正变得越来越受欢迎。Berkholz在电子邮件中说:“在特定领域内,宕机频率并不会阻碍用户选择在其他方面有着出色成绩的云服务商。问题的关键并不是哪家云服务提供商***,而是客户能够忍受哪些限制因素。”
如今用户已经有许多办法可以应对云服务的中断故障。比方说,不在单一地方托管工作负载,使用工具将流量从故障的服务器中迁移出去,经常性地测试系统的容错能力等。用户可能正在关注这些***实践,或许他们根本不会把敏感数据和应用放在会受到宕机影响的云上。不管怎样,云服务商和用户似乎都变得越来越擅长提供和使用这些服务。
















