












如果以时间来计算的话,基于 GPU 来实现通用计算的口号喊出来到现在应该有 10 个年头,不过真正热络起来应该从 DX10 世代 GPU 开始算起。
在 DX9 世代的 R580 GPU 时期,AMD 尝试引入名为 Close To Metal(简称 CTM)的软件开发界面,让开发人员得以实现 GPGPU(GPU 通用计算)开发能力。
Close To Metal 直译就是靠近芯片金属层的意思,在这里就是指这个开发界面是一个底层开发界面,开发人员可以籍此使用 R580 等 AMD GPU 的本机指令集以及内存访问。
不过因为当时 AMD 在新品(R600)上的不力以及开发难度等因素,这个开发界面的主要作用只是为接下来的新开发包铺路和让第三方开发人员取得一些 GPGPU 上的经验,当年的 CTM 现在已经以 GPU 指令集架构文档的形式公开提供。每代 AMD GPU 微架构发布后,开发人员都能在不久后就下载到相应的文档,比主要的独立显卡竞争对手大方许多。
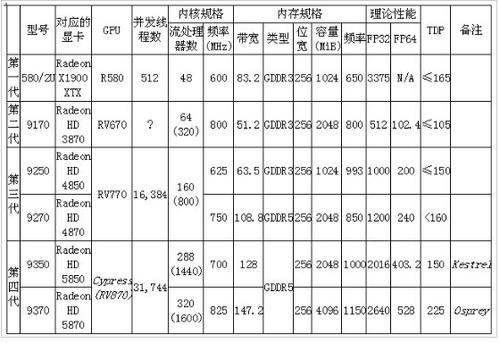
在 2006 年到 2012 年期间,AMD 发布了四代型号为 FireStream 的 GPU 超算专用卡:
▲
FireStream R580/2U 属于 DX9 世代的产品,缺乏双精度计算能力,从 GPGPU 的角度而言,所谓的***代自然是属于试探性的产品。
接下来的三代 FireStream 都是基于名为 TeraScale 的微架构,特点流处理器采用了 VLIW ALU 组成方式,按照世代划分的话,有三代 TeraScale 微架构,即 TeraScale1、TeraScale2、TeraScale3,其中前两代是 VLIW5,而 TeraScale3 是 VLIW4。
VLIW 架构的特点是计算密度比较高,非常适合于图形渲染,但是对软件开发的要求比较高,而且容易出现相依性问题导致的计算资源闲置问题。从通用计算的角度而言,TeraScale 微架构并不十分友好。
到了 2012 年,AMD 认为,从产品线的角度而言,FireStream 和 FirePro 存在较大的重叠,因此在这一年开始,FireStream 被并入到 FirePro 中。
也是从 2012 年起,AMD 在异架构计算方面开始真正渐入佳境,因为在这一年 AMD 正式推出名为 Graphics Core Next(简称 GCN)的新一代 GPU 微架构。
GCN 采用了 SIMD16 的 ALU 组合方式,显著改善了通用计算方面的效率问题。
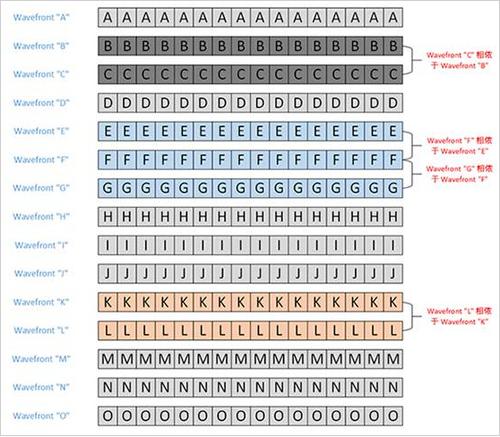
假定我们有 A 到 O 共计 15 个 wavefront(在 AMD GPU 中硬件调度器的最小调度单位,这个单位大小是和硬件相关的,目前 AMD GPU 的 wavefront 由 64 个在 OpenCL 中定义为 work-item 的“thread(线程)”组成;在 NVIDIA CUDA 中称作 warp,目前 NVIDIA CUDA 中的 warp 都是 32 个 work-item 组成。据我所知,wavefront 和 warp 在 OpenCL 中没有完全对应的术语,不过有时候为了方便,可以称作 sub-workgroup)组成的队列,其中有若干个 wavefront 存在相依性。
例如这里面的 wavefront C 需要 wavefront B 的计算结果才能正确执行,因此这两个 wavefront 是不应该并行执行。
▲
在采用 VLIW4 ALU 组合的 TeraScale3 或者说 RADEON HD 6900 上执行上面的队列就会发生下面的情况(红色方块表示 SP 中闲置的个别 VLIW 计算单元):
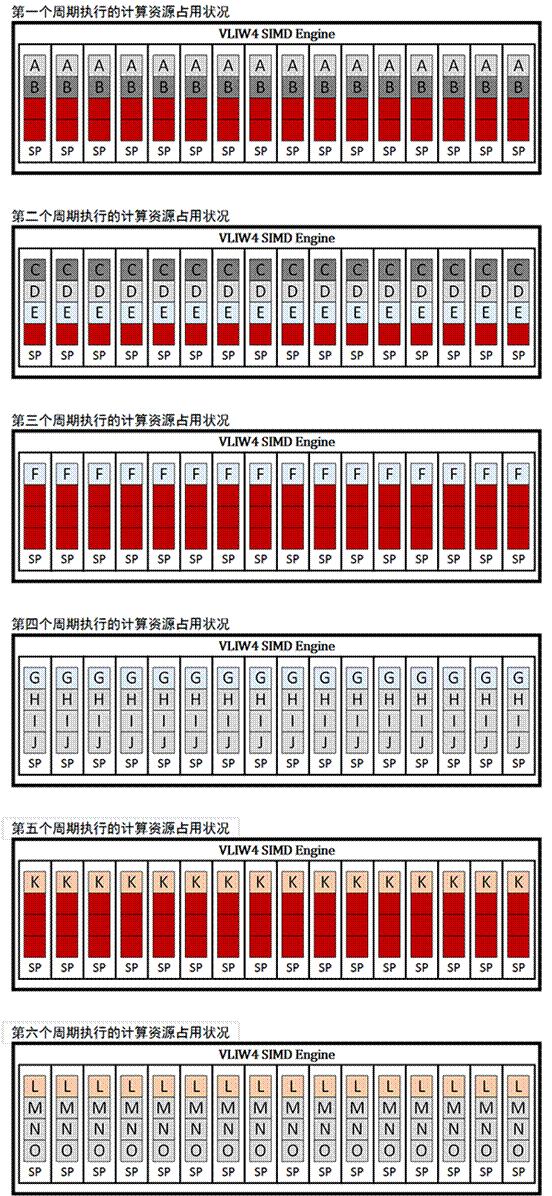
从上面的示意图可以看到,在出现相依性的时候,VLIW 形式的 ALU 比较容易出现计算资源闲置的情况。而在 AMD 从 2012 年引入的 GCN 上情况就有较大的改善:
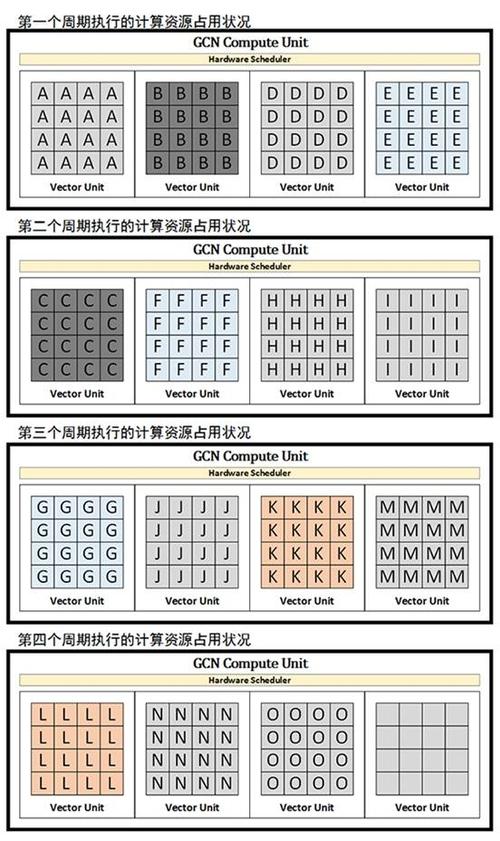
▲
正如你所看到的,GCN 的计算资源利用率有显著的改善,原本需要 6 个周期跑的队列,现在只需要 4 个周期就行了,按照 AMD 的说法,GCN 1.0 的计算资源利用率***可以达到 TeraScale3 的 7.5 倍。
当然,造成计算资源闲置的原因其实很复杂,例如分支,不过即使这样,GCN 在这些问题上的处理还是要比 TeraScale 更好。
从 2012 年到现在 2015 年,GCN 作为微架构也在不断地更新。例如 2012 年的 GCN 版本就是 1.0(Tahiti),而后的有 1.1(Hawaii),***的则是 1.2(Tonga)。
在 GCN 之前,AMD 奉行的产品规划是 sweet spot 战略,也就是管芯大小控制在 300 mm^2 的水平,原因是当时 AMD 主打的还是游戏玩家为主的市场,但是到了 GCN 尤其是 GCN 1.1 以后,这样的策略已经有明显的变化,管芯面积更大(438 mm^2)的 Hawaii 出现在了旗舰产品线上。这是因为 GPU 计算市场已经被证明是存在而且发展趋势良好,因此做针对高性能计算的大芯片 GPU 是有客户需求基础的。
目前 AMD 基于 Hawaii GPU 的 FirePro 产品有三款:
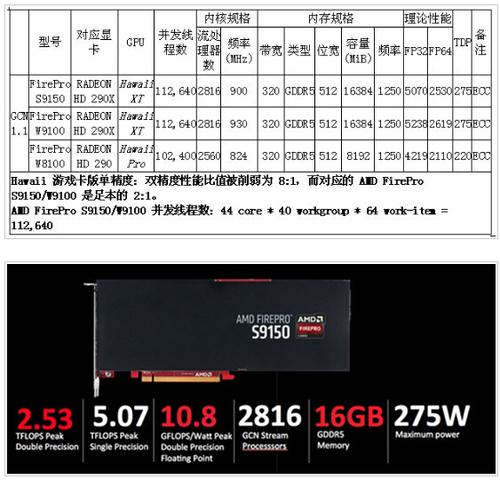
▲
其中的 AMD FirePro S9150 是专门针对超算服务器市场而推出的,在 2014 年年末评选的绿色超级计算机 500 强里,基于 AMD FirePro S9150 的 GSI L-CSC 集群拿下了年度***名的成绩,每瓦双精度实测(High Performance Linpack)性能***实现了超过 5 GFLOPS。
新近上市的 AMD FirePro W7100 采用了 GCN 1.2 版微架构,其中的卖点之一是视频处理能力增强以及单槽 8 GiB 内存,如果应用涉及视频处理的话,AMD FirePro W7100 是***的选择。
由于选择了开放标准作为主打的开发环境,AMD 现在的合作伙伴数量正在不断扩大中,例如编译器厂商 PathScale 就和 AMD 在 OpenMP 4.0 方面有密切的合作,PathScale 甚至正协助 AMD 开发 Linux 下的开源驱动,籍此进一步改善 AMD GPU/APU 的计算性能。
根据***的统计,包括像 Adobe、Autodesk、达索系统等世界***企业已经将 OpenCL 应用到旗下的实际产品中,开发工具方面也涌现了 OpenCV(可视化库)、Bolt(C++ 模板库)、clMath(数学库)、Ararapi(Java 7 OpenCL 加速)等丰富的开源库,大量培训机构也开启了 OpenCL 的课程,整个 OpenCL 阵营已经***的壮大。
毫无疑问的是,现在 GPU 通用计算的市场已经全面开启,AMD、NVIDIA、Intel 根据各自市场定位推出了性能、特点各异的产品,其中 AMD 主打的是性能/耗电比以及 OpenCL 开发生态环境,具备强劲的单 GPU 双精度性能和合理的电力要求,而两点对用户来说意味着可以有更多的资源来获得更强大的性能或者较低的使用成本,预期未来也将在此基础上在内存带宽、内存容量、通用计算特性上有更多的提升。














