本文将会对常用的几个压缩算法的性能作一下比较。结果表明,某些算法在极端苛刻的CPU限制下仍能正常工作。
文中进行比较的算有:
- JDK GZIP ——这是一个压缩比高的慢速算法,压缩后的数据适合长期使用。JDK中的java.util.zip.GZIPInputStream / GZIPOutputStream便是这个算法的实现。
- JDK deflate ——这是JDK中的又一个算法(zip文件用的就是这一算法)。它与gzip的不同之处在于,你可以指定算法的压缩级别,这样你可以在压缩时间和输出文件大小上进行平衡。可选的级别有0(不压缩),以及1(快速压缩)到9(慢速压缩)。它的实现是java.util.zip.DeflaterOutputStream / InflaterInputStream。
- LZ4压缩算法的Java实现——这是本文介绍的算法中压缩速度最快的一个,与最快速的deflate相比,它的压缩的结果要略微差一点。如果想搞清楚它的工作原理,我建议你读一下这篇文章。它是基于友好的Apache 2.0许可证发布的。
- Snappy——这是Google开发的一个非常流行的压缩算法,它旨在提供速度与压缩比都相对较优的压缩算法。我用来测试的是这个实现。它也是遵循Apache 2.0许可证发布的。
压缩测试
要找出哪些既适合进行数据压缩测试又存在于大多数Java开发人员的电脑中(我可不希望你为了运行这个测试还得个几百兆的文件)的文件也着实费了我不少工夫。最后我想到,大多数人应该都会在本地安装有JDK的文档。因此我决定将javadoc的目录整个合并成一个文件——拼接所有文件。这个通过tar命令可以很容易完成,但并非所有人都是Linux用户,因此我写了个程序来生成这个文件:
- public class InputGenerator {
- private static final String JAVADOC_PATH = "your_path_to_JDK/docs";
- public static final File FILE_PATH = new File( "your_output_file_path" );
- static
- {
- try {
- if ( !FILE_PATH.exists() )
- makeJavadocFile();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- private static void makeJavadocFile() throws IOException {
- try( OutputStream os = new BufferedOutputStream( new FileOutputStream( FILE_PATH ), 65536 ) )
- {
- appendDir(os, new File( JAVADOC_PATH ));
- }
- System.out.println( "Javadoc file created" );
- }
- private static void appendDir( final OutputStream os, final File root ) throws IOException {
- for ( File f : root.listFiles() )
- {
- if ( f.isDirectory() )
- appendDir( os, f );
- else
- Files.copy(f.toPath(), os);
- }
- }
- }
在我的机器上整个文件的大小是354,509,602字节(338MB)。
测试
一开始我想把整个文件读进内存里,然后再进行压缩。不过结果表明这么做的话即便是4G的机器上也很容易把堆内存空间耗尽。
于是我决定使用操作系统的文件缓存。这里我们用的测试框架是JMH。这个文件在预热阶段会被操作系统加载到缓存中(在预热阶段会先压缩两次)。我会将内容压缩到ByteArrayOutputStream流中(我知道这并不是最快的方法,但是对于各个测试而言它的性能是比较稳定的,并且不需要花费时间将压缩后的数据写入到磁盘里),因此还需要一些内存空间来存储这个输出结果。
下面是测试类的基类。所有的测试不同的地方都只在于压缩的输出流的实现不同,因此可以复用这个测试基类,只需从StreamFactory实现中生成一个流就好了:
- @OutputTimeUnit(TimeUnit.MILLISECONDS)
- @State(Scope.Thread)
- @Fork(1)
- @Warmup(iterations = 2)
- @Measurement(iterations = 3)
- @BenchmarkMode(Mode.SingleShotTime)
- public class TestParent {
- protected Path m_inputFile;
- @Setup
- public void setup()
- {
- m_inputFile = InputGenerator.FILE_PATH.toPath();
- }
- interface StreamFactory
- {
- public OutputStream getStream( final OutputStream underlyingStream ) throws IOException;
- }
- public int baseBenchmark( final StreamFactory factory ) throws IOException
- {
- try ( ByteArrayOutputStream bos = new ByteArrayOutputStream((int) m_inputFile.toFile().length());
- OutputStream os = factory.getStream( bos ) )
- {
- Files.copy(m_inputFile, os);
- os.flush();
- return bos.size();
- }
- }
- }
这些测试用例都非常相似(在文末有它们的源代码),这里只列出了其中的一个例子——JDK deflate的测试类;
- public class JdkDeflateTest extends TestParent {
- @Param({"1", "2", "3", "4", "5", "6", "7", "8", "9"})
- public int m_lvl;
- @Benchmark
- public int deflate() throws IOException
- {
- return baseBenchmark(new StreamFactory() {
- @Override
- public OutputStream getStream(OutputStream underlyingStream) throws IOException {
- final Deflater deflater = new Deflater( m_lvl, true );
- return new DeflaterOutputStream( underlyingStream, deflater, 512 );
- }
- });
- }
- }
测试结果
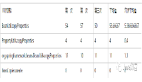
输出文件的大小
首先我们来看下输出文件的大小:
||实现||文件大小(字节)|| ||GZIP||64,200,201|| ||Snappy (normal)||138,250,196|| ||Snappy (framed)|| 101,470,113|| ||LZ4 (fast)|| 98,316,501|| ||LZ4 (high) ||82,076,909|| ||Deflate (lvl=1) ||78,369,711|| ||Deflate (lvl=2) ||75,261,711|| ||Deflate (lvl=3) ||73,240,781|| ||Deflate (lvl=4) ||68,090,059|| ||Deflate (lvl=5) ||65,699,810|| ||Deflate (lvl=6) ||64,200,191|| ||Deflate (lvl=7) ||64,013,638|| ||Deflate (lvl=8) ||63,845,758|| ||Deflate (lvl=9) ||63,839,200||

可以看出文件的大小相差悬殊(从60Mb到131Mb)。我们再来看下不同的压缩方法需要的时间是多少。
压缩时间
||实现||压缩时间(ms)|| ||Snappy.framedOutput ||2264.700|| ||Snappy.normalOutput ||2201.120|| ||Lz4.testFastNative ||1056.326|| ||Lz4.testFastUnsafe ||1346.835|| ||Lz4.testFastSafe ||1917.929|| ||Lz4.testHighNative ||7489.958|| ||Lz4.testHighUnsafe ||10306.973|| ||Lz4.testHighSafe ||14413.622|| ||deflate (lvl=1) ||4522.644|| ||deflate (lvl=2) ||4726.477|| ||deflate (lvl=3) ||5081.934|| ||deflate (lvl=4) ||6739.450|| ||deflate (lvl=5) ||7896.572|| ||deflate (lvl=6) ||9783.701|| ||deflate (lvl=7) ||10731.761|| ||deflate (lvl=8) ||14760.361|| ||deflate (lvl=9) ||14878.364|| ||GZIP ||10351.887||

我们再将压缩时间和文件大小合并到一个表中来统计下算法的吞吐量,看看能得出什么结论。
吞吐量及效率
||实现||时间(ms)||未压缩文件大小||吞吐量(Mb/秒)||压缩后文件大小(Mb)|| ||Snappy.normalOutput ||2201.12 ||338 ||153.5581885586 ||131.8454742432|| ||Snappy.framedOutput ||2264.7 ||338 ||149.2471409017 ||96.7693328857|| ||Lz4.testFastNative ||1056.326 ||338 ||319.9769768045 ||93.7557220459|| ||Lz4.testFastSafe ||1917.929 ||338 ||176.2317583185 ||93.7557220459|| ||Lz4.testFastUnsafe ||1346.835 ||338 ||250.9587291688 ||93.7557220459|| ||Lz4.testHighNative ||7489.958 ||338 ||45.1270888301 ||78.2680511475|| ||Lz4.testHighSafe ||14413.622 ||338 ||23.4500391366 ||78.2680511475|| ||Lz4.testHighUnsafe ||10306.973 ||338 ||32.7933332124 ||78.2680511475|| ||deflate (lvl=1) ||4522.644 ||338 ||74.7350443679 ||74.7394561768|| ||deflate (lvl=2) ||4726.477 ||338 ||71.5120374012 ||71.7735290527|| ||deflate (lvl=3) ||5081.934 ||338 ||66.5101120951 ||69.8471069336|| ||deflate (lvl=4) ||6739.45 ||338 ||50.1524605124 ||64.9452209473|| ||deflate (lvl=5) ||7896.572 ||338 ||42.8033835442 ||62.6564025879|| ||deflate (lvl=6) ||9783.701 ||338 ||34.5472536415 ||61.2258911133|| ||deflate (lvl=7) ||10731.761 ||338 ||31.4952969974 ||61.0446929932|| ||deflate (lvl=8) ||14760.361 ||338 ||22.8991689295 ||60.8825683594|| ||deflate (lvl=9) ||14878.364 ||338 ||22.7175514727 ||60.8730316162|| ||GZIP ||10351.887 ||338 ||32.651051929 ||61.2258911133||

可以看到,其中大多数实现的效率是非常低的:在Xeon E5-2650处理器上,高级别的deflate大约是23Mb/秒,即使是GZIP也就只有33Mb/秒,这大概很难令人满意。同时,最快的defalte算法大概能到75Mb/秒,Snappy是150Mb/秒,而LZ4(快速,JNI实现)能达到难以置信的320Mb/秒!
从表中可以清晰地看出目前有两种实现比较处于劣势:Snappy要慢于LZ4(快速压缩),并且压缩后的文件要更大。相反,LZ4(高压缩比)要慢于级别1到4的deflate,而输出文件的大小即便和级别1的deflate相比也要大上不少。
因此如果需要进行“实时压缩”的话我肯定会在LZ4(快速)的JNI实现或者是级别1的deflate中进行选择。当然如果你的公司不允许使用第三方库的话你也只能使用deflate了。你还要综合考虑有多少空闲的CPU资源以及压缩后的数据要存储到哪里。比方说,如果你要将压缩后的数据存储到HDD的话,那么上述100Mb/秒的性能对你而言是毫无帮助的(假设你的文件足够大的话)——HDD的速度会成为瓶颈。同样的文件如果输出到SSD硬盘的话——即便是LZ4在它面前也显得太慢了。如果你是要先压缩数据再发送到网络上的话,最好选择LZ4,因为deflate75Mb/秒的压缩性能跟网络125Mb/秒的吞吐量相比真是小巫见大巫了(当然,我知道网络流量还有包头,不过即使算上了它这个差距也是相当可观的)。
总结
- 如果你认为数据压缩非常慢的话,可以考虑下LZ4(快速)实现,它进行文本压缩能达到大约320Mb/秒的速度——这样的压缩速度对大多数应用而言应该都感知不到。
- 如果你受限于无法使用第三方库或者只希望有一个稍微好一点的压缩方案的话,可以考虑下使用JDK deflate(lvl=1)进行编解码——同样的文件它的压缩速度能达到75Mb/秒。
源代码
原文转自:Java不同压缩算法的性能比较