前言
对于一个业务系统,如何高效、平稳地使用数据库是每一个开发人员都会遇到的问题,OpenStack 也不例外,以 OpenStack 的虚拟网络组件 Neutron 为例,其数据库涉及几百张表,需要维护数据库版本近百;一些表因为设计原因形成了很高的“热点”;因为 OpenStack 是分布式的,需要以***小一点的代价保证操作时的一致性……最重要的是,每个人的数据库水平都不一样,怎么保证整个开源社区数百名提交者有一样的数据库操作风格,如何维护这些代码?
OpenStack 做为一个完全使用 Python 开发的项目,利用已有的丰富模块是开发时重要的中心思想之一,同时为了便于整个社区几百名背景不同水平不同的开发者协作,最终选择了 SQLAlchemy 和 Alembic 作为数据库开发的基础。
Why SQLAlchemy
在回答为什么使用 SQLAlchemy 之前,我们先盘点一下目前 Python 能用的 ORM 库,因为挑一个库在很大程度上实在挑社区,所以我把***版的 release 时间也写出来:
Storm:***版 0.20,release 于 2013 年,开发已经比较沉寂……对外键的更新、删除要求比较奇怪。
SQLObject:***版 1.7.3,release 于 2014.12.18,开发历史久,目前活跃度不是很高。
Django’s ORM:来自于 Django,Django 内置,使用 Django 开发的话会很方便,但它不能脱离 Django 运行,也不能处理一些复杂的请求。
peewee:***版 2.4.4 发布于2014.12.3,轻量方便,内置 SQLite、MySQL和PostgreSQL的支持。
PonyORM:***版 0.6,release 于 2014.11.5。使用 AGPL 许可。有图形化的编辑器。非为大型应用设计。
SQLAlchemy:***版 0.9.8,release 于 2014.10.13,企业级 API,设计灵活。加入了一些自己的概念,学习曲线较高。
总结一下,Storm 曾经应用比较广泛,但现在社区不再活跃,很难保证将来遇到问题能否交给社区解决,而且 Storm 对数据库架构同步处理的比较奇怪,还有频繁产生 DDL 操作 造成库级锁这些问题无法让人放心;SQLObject 也是一个很出名的 ORM 库,但与 SQLAlchemy 相比,后者效率更高,对一些高级特性的支持不如后者。
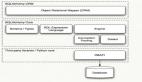
SQLAlchemy 的架构
- Summary
SQLAlchemy 很有特色的一点就是它刻意被分为另种用法,就是 CORE 和 ORM,这是由它的架构决定的。
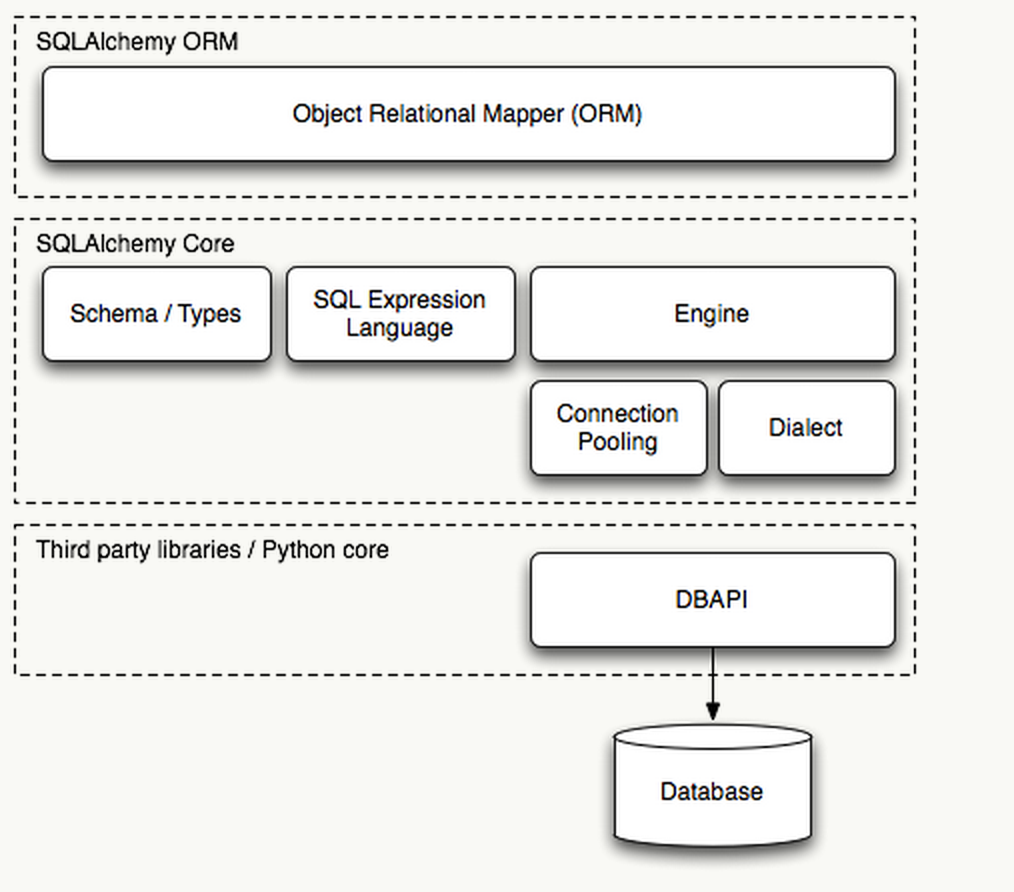
这样的架构的好处是带来了 Core 与 ORM 的解耦和,当我们需要高性能的 SQL 执行但又不想抛弃 SQLAlchemy 带来的session管理、连接池管理、数据库“中立”的语句编写等这些好处时我们可以直接用 CORE。直接用 CORE 是什么意思呢?我们看到架构里只有Rational Mapper在 CORE 之上,实际也确实如此,因为Schema、SQL Expression Language还在 CORE 内,所以使用 CORE 可以直接写纯 SQL 语句,我们称之为Raw SQL的写法,也可以用SQL Expression,后者因为是相当于写 Python 代码,所以可以带来更好地阅读性和可维护性,不过Raw SQL更灵活,所以在很复杂的语句面前Raw SQL就更占优势了。
再往下看这个图,我们可以看到 DBAPI 是由Third party libraries实现的,也就是说 SQLAlchemy 并没有提供直接连接数据库的功能,而是通过第三方实现:
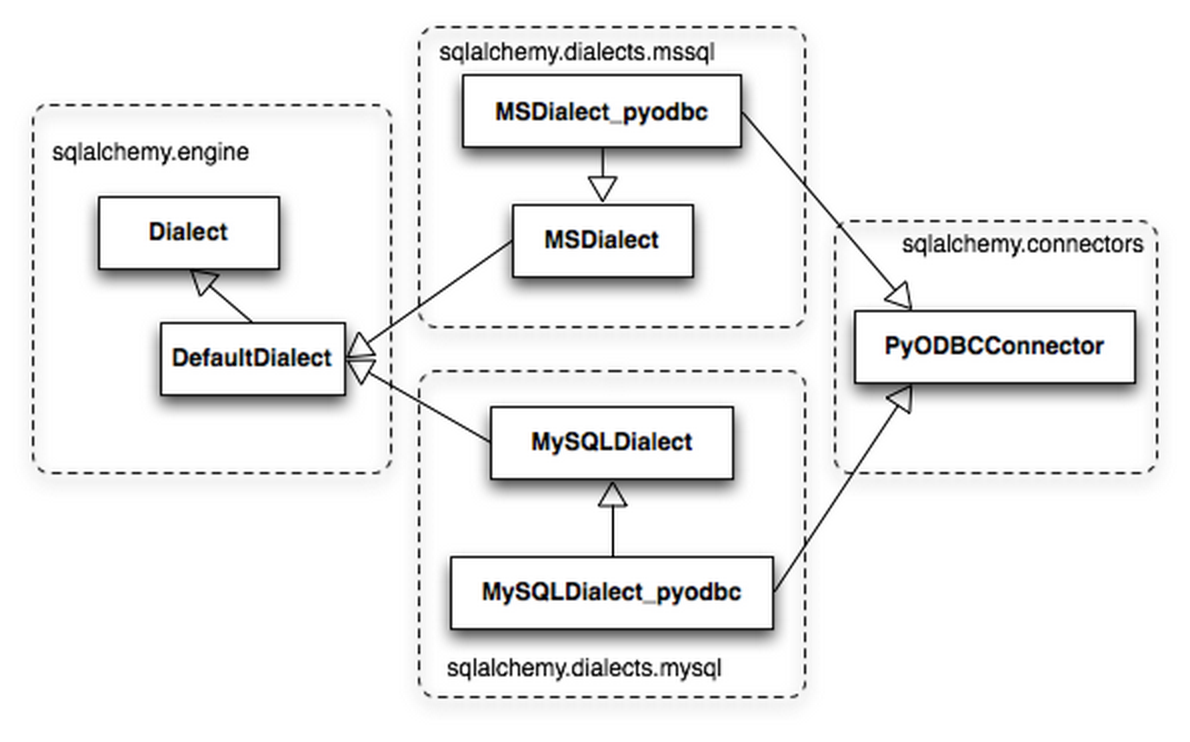
SQLalchemy 对dialect支持很全,就以常见的 MySQL 为例,可以支持:MySQL-Python、OurSQL、PyMySQL、MySQL Connector/Python、CyMySQL、Google Cloud SQL、PyODBC、zxjdbc for Jython,具体可以在 SQAlchemy 的dialects页面里查到。
这样有什么坏处呢,最明显的就是低效。因为传统 Python 解释器 CPython 的实现原因(主要是 C 的问题)长的函数调用栈会带来显着地性能问题。 由于路径过长,不可避免地导致运行时的缓慢。SQLAlchemy 花了很旧去缩短调用路径和通过 C 代码处理性能瓶颈,效果还不错,不过***还是希望 PyPy 能够广泛流行起来,通过JIT缓解这个问题。
- Engine
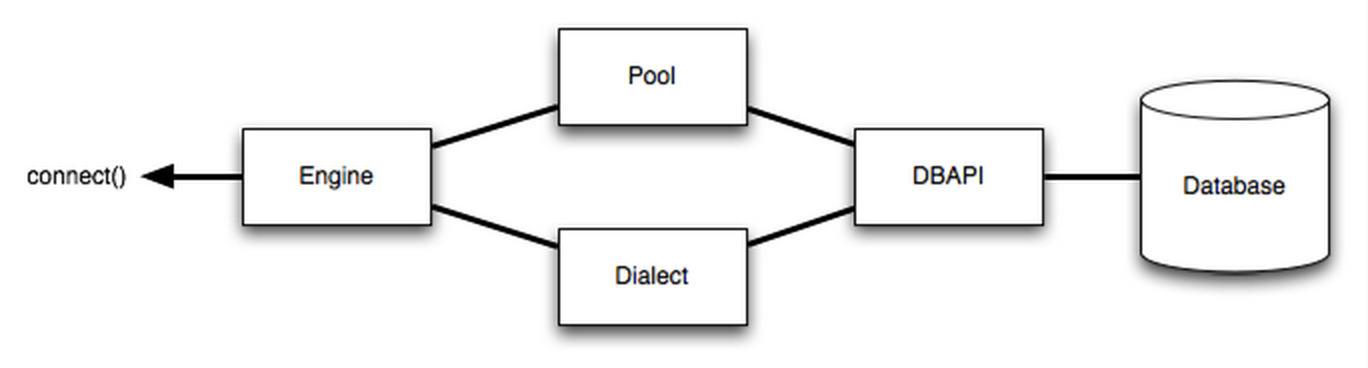
上面的图还是一张抽象程度比较高的,下面我细节点的介绍下 SQLAlchemy 的Engine。
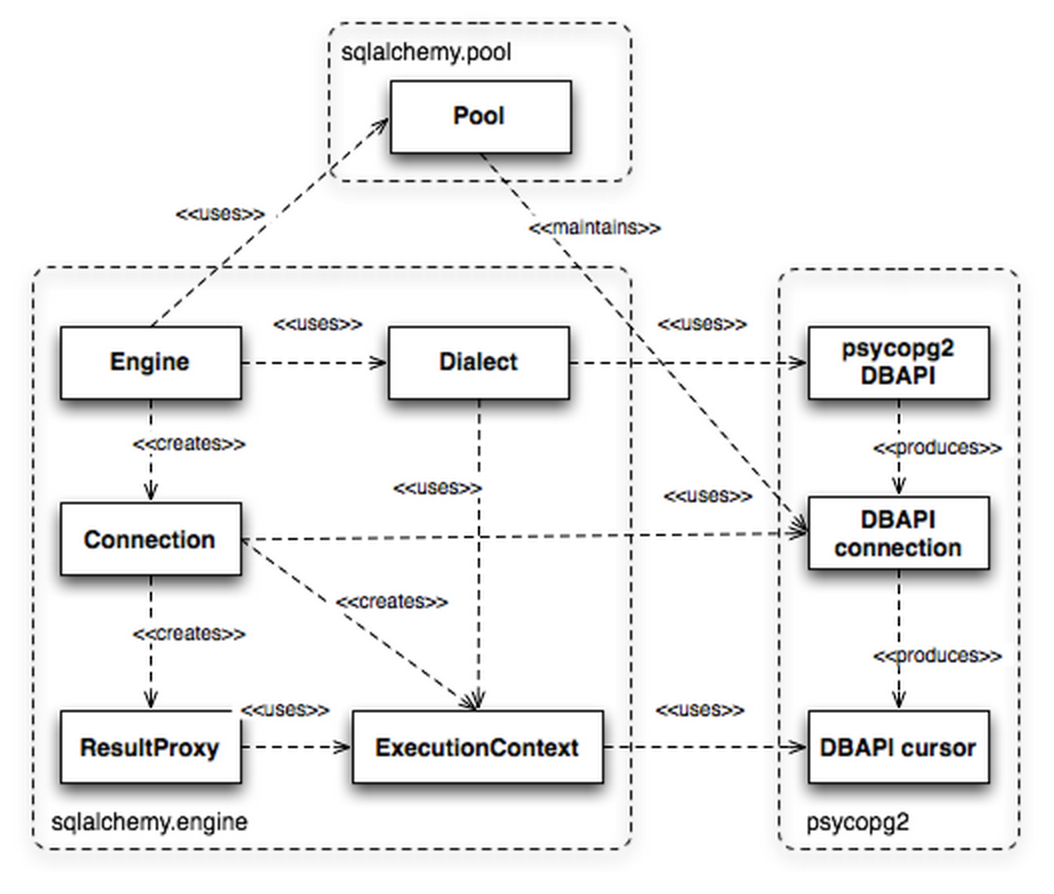
对于使用者来说,Engine是核心,因为Connection、 ResultProxy这些都是在Engine之后生成的,建立Engine则有两个重点,就是Pool和Dialect,前者是做连接池管理,后者则负 责与 DBAPI 的沟通,如同其名字所示,负责“方言”与“普通话”的翻译。上图是以psycopg2为例的,使用 MySQL(PyODBC)也是类似的。
通过Dialect和ExecutionContext向开发者提供了一致的接 口,前者处理了数据库的特性,比如使用 PostgreSQL 数据库其 Array 数据类型、schema、catalog等,后者处理psycopg2 DBAPI 的用法,比如 unicode 字符处理、服务端 cursor 的行为这些。
所以说,DBAPI中的cursor在 SQLAlchemy 中会被包装成ExecutionContext和ResultProxy来使用的。
- Schema
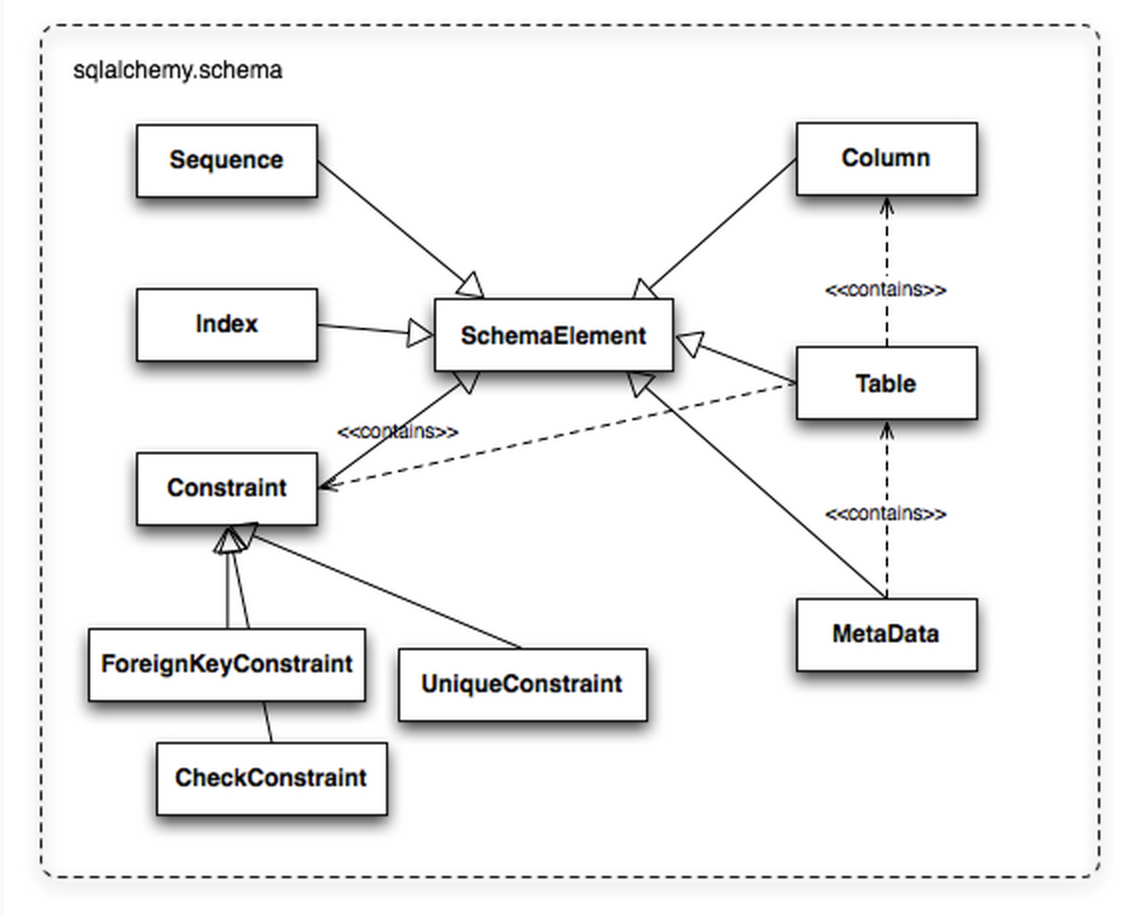
当数据库的连接和交互处理完了,下一步就是提供非特定的表、字段的建立和操作方法。我们需要首先定义在数据库中的表和字段的定义,及他们之间的关系, 也就是 Schema。对于数据库的使用来说,最基本的至少要有两个元素,那就是Table和Column,SQLAlchemy 使用了这两个名字来描述表和字段。多个Column组合成Table,然后一些 Table构成MetaData。Schema的结构设计主要来自于 Martin Fowler 撰写的 Patterns of Enterprise Application Architecture。
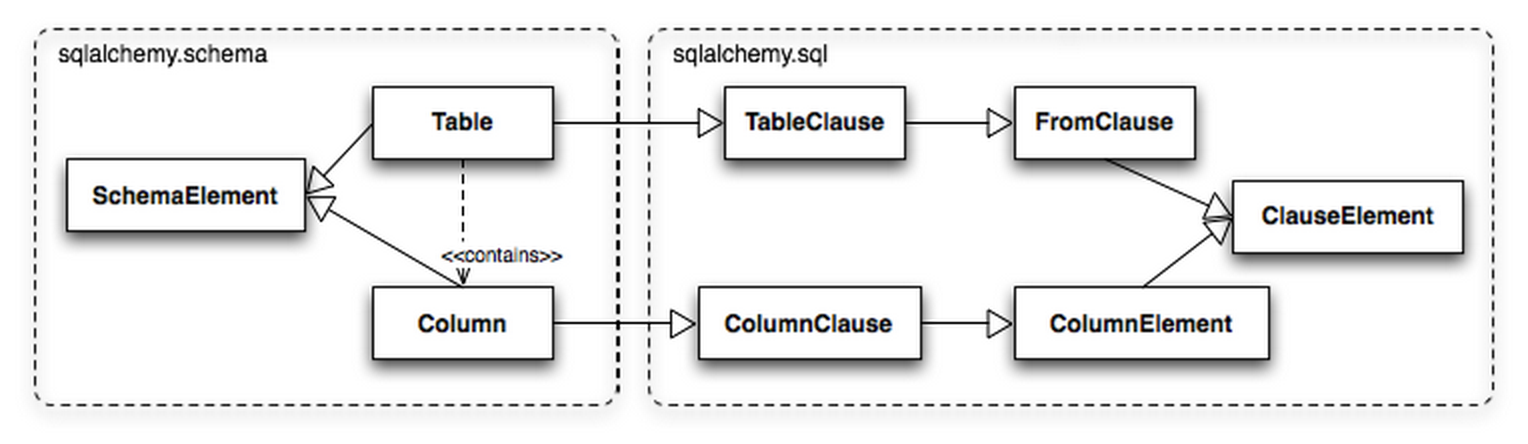
此外,Table和Column同时继承自sqlalchemy.schema 和sqlalchemy.sql,使用时既可以在 ORM 的方式中使用,也可以以 SQL Expression Language 使用。在下图中我们可以看到Table从sqlalchemy.sql中“可以select from”的类继承,Coloumn从“可以用在 SQL expression”的类继承。
- 表达式树
SQLAlchemy 可以生成结构丰富的各种语句,这是一个词法分析树,核心结构是ClauseElement。
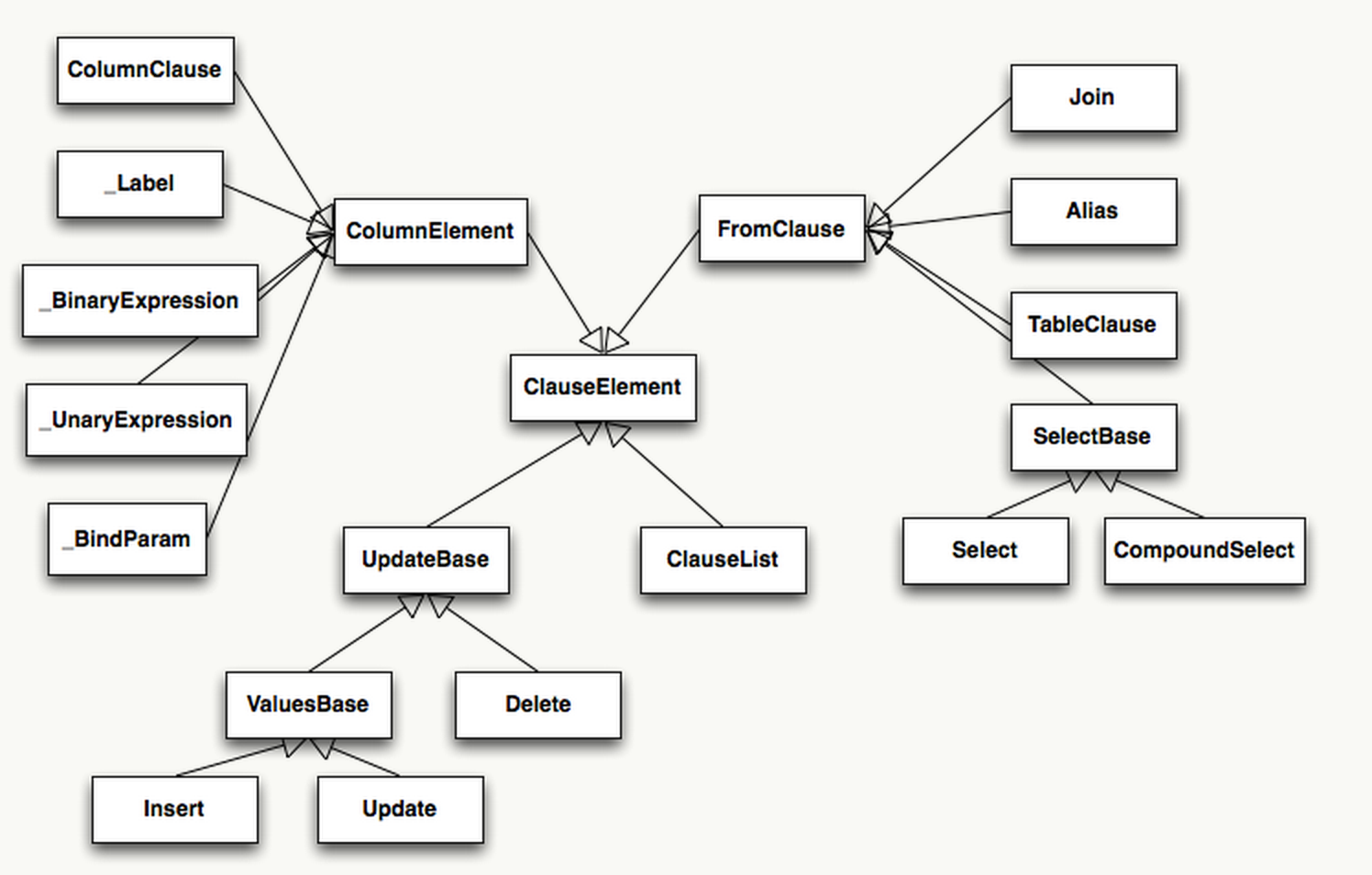
在 Python 中,得益于其 Magic Method,我们可以用__eq__、__ne__、__le__、__lt__、__add__、__mul__方便的重载运算符。以 Column 为对象的运算符由一个 mixin 类ColumnOperators实现重载。
编译
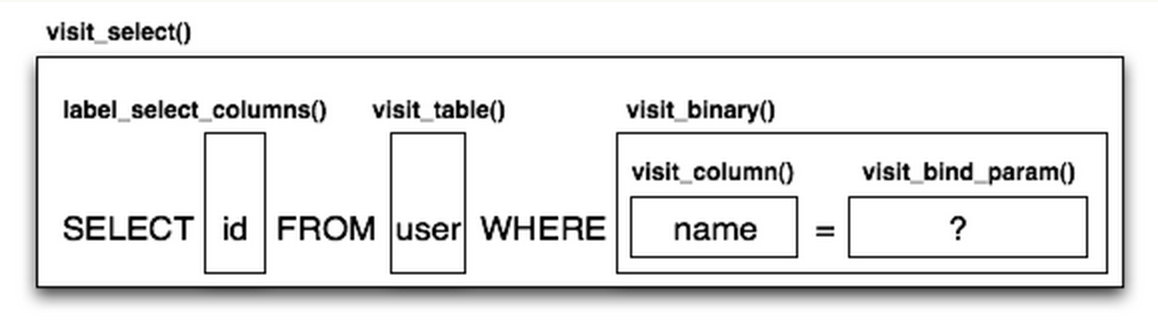
在这里,编译指生成 SQL 语句,主要由Compiled类完成,这个类有两个核心的子类,SQLComplier和DDLCompiler。SQLComplier负责像 SELECT、INSERT、UPDATE、DELETE这些统称为DQL (data query language) 和 DML (data manipulation language)的操作符的渲染,DDLCompiler负责CREATE和DROP,一般称为 DDL。此外,还有一个类TypeCompiler处理某些数据库的特殊语法。

Compiled的子类定以了一系列的 visit 开头的方法,每一个都源于一个ClauseElement的特定子类。然后Compiled对象维护名字、结合参数和子查询,最终是为了生成一个 SQL 查询语句。
Migration
我们希望能像管理代码一样管理数据库,可以像 git 一样给数据库定义版本、升/降级、打标签,可以么?答案就是 Alembic。
Alembic 的作者与 SQLAlchemy 是同一人,使用起来有点像简化版的 git,在 db 目录里执行 init,就可以自动生成基本结构和配置文件。配置妥当后使用 alembic 可以生成一个数据库模版,作为这个“版本”的数据升/降级文件,SQLAlchemy 会自动生成其“版本号”和历史关系我们所需要做的便只是用调用 SQLAlchemy 和 Alembic 提供的 sa 和 op 定义数据库表即可。
有同学可能问我在 SQLAlchemy 上做过一模一样的定义了,是不是能不要让我重复劳动啊?或者在我给 SQLAlchemy 做完修改后 Alembic 能不能自动“感知”到这些修改然后自己生成版本文件啊?答案是可以的,配置好元数据来源后,Alembic 可以用–autogenerate自动生成相应的版本文件。