经常有朋友问到,“感觉你们的系统最近没什么太大变化,你们几百号工程师在忙什么?”,下面的这个问题,可能是工程师花费了不少时间的场景之一,最坏的情况下里面所有方案或许都尝试过一遍。
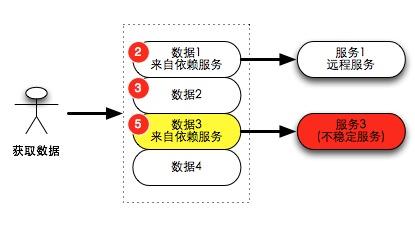
有如下一个场景,某个服务需要构建一个列表数据返回给调用方(调用方通常是客户端),服务本身是一个数据聚合器,它由内部多个远程服务的数据聚合而生成。在正常情况下,需要将所有内部服务的结果全获取成功后再返回。但是在一个大系统中,多个服务中某个服务出现不稳定的概率会比较大,当出现如图远程服务3不可用的时候,有三种不同的解决思路。
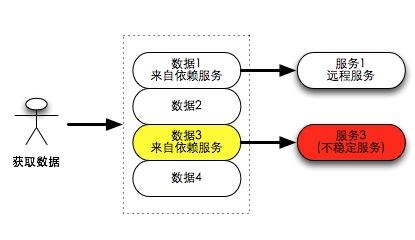
- 方案1:忽略出错的数据(图中数据3),直接返回数据1、2、4。
- 方案2:遇到任意失败,整个请求返回错误503 service unavailable。
- 方案3:忽略出错的数据(图中数据3),并告知调用方出错的范围,需要自定义的返回格式。如 {“load_data3_success”: false}
如果你作为一个架构师,会选择哪种方案?
方案一类似架构设计里面常说的优雅降级,在出现问题情况下,除了数据3不能返回之外,其它数据可以正常返回,原理上可以将损失降低到***。但这种方案会给用户体验带来一定伤害,用户在使用系统时候会存在不确定性的心理感受。
方案二比较依赖调用方的容错逻辑,如果调用方保存了上一次缓存,且容错逻辑处理得当,用户表面会感受不到这个异常。如果没有容错逻辑,最坏情况则将会返回白页。但是即使有容错逻辑,由于正常的数据也不能及时返回,从工程师到用户可能不太容易接受这个结果。
方案三是一个看起来相对合理的方案,但是需要添加自定义的字段,本来这是一个标准的LIST返回,但是需要额外添加一些错误字段如 {“load_data3_success”: false}来标识哪些数据返回失败了。一个简单的接口变得异常繁琐,同时调用方也需要实现缓存及容错逻辑。这个方案从服务方到调用方的熵都增加了很多。
因此,这个选择题已经不好做了。但雪上加霜的是,在大部分应用中,对于数据列表访问同时还存在未读数的功能,如下图中的小红点数字。如果这个未读数由另外一个API提供(本讨论假设未读数API功能正常),情况就更复杂。
补充讨论一下,如果不提供单独的未读数API,客户端需要每次需要加载新的全量数据才能本地算出未读数,会带来访问速度的下降及客户端更多流量的消耗。因此大多数情况提供一个未读数API整体开销会更低。通过未读数API判断当服务端有新数据时候才去访问列表接口。
这时候如果未读数都出来了,远程数据又取不到的情况下,你作为架构师,会选择何种方案?
原文链接:http://timyang.net/service/arch-interview-questions/