亚马逊发布了Aurora系统,并允诺其会有许多引人注目的特性。让我们深入了解一下Aurora系统,并探索一下其分支结构。
结构:
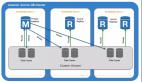
Aurora的整体设计是这样的,利用一个master节点提供写服务,Slave节点展开在master节点周围,用于读,,这听起来像MySQL-读操作是可扩展的。亚马逊还撰写了很多关于Aurora存储功能的说明,但是关于其结构细节的内容却少的可怜。也许他们将使用了SSDs的AWS DynamoDB作为对数据引擎透明的后端存储。因为扩展读操作需要用到AWS基础设施中的共享磁盘,所以Aurora只能工作在AWS上。
扩展:
通过允许15副本(Slave读操作节点),Aurora在多种工作负载情况都具有良好的可扩展性。然而,对于写操作的扩展细节是不明确的。最终系统性能会受到主节点写操作性能的制约。这里还没有提及内存中写入的处理,因此写入操作将限制于存储基础架构,其通常建议使用SSD,但横跨多个Availability Groups,又回到那个延迟的问题。
可用性:
亚马逊承诺同时提供多个“ 副本 ”(Slave读操作节点)和“基于恢复时间点的增量备份。” 但是,没有规定副本推送至写操作Master节点的延迟; 所以,如果丢失了写操作Master节点,将会产生一个(应用程序)的延迟,之后才能继续写操作。相应地,基于时间点的恢复也有显著延时:“......重建数据库到你保存的任意时刻直到***5分钟前。“因此,如果您的实例挂掉,所有***五分钟的事务都将丢失?Aurora试图通过将故障转移到其他副本,以缓解这种巨大的延时,即“Reserved Instance” “热插拔”硬件已经在云技术中出现了!
复制:
延迟是一个有趣的问题。亚马逊已经表示,他们的复制是异步的。这并不奇怪,因为如果不这么做,他们将在Master节点上看到巨大的写入延迟。他们声称复制是毫秒级的-但是具体是如何处理的并不为人所知。如果DynamoDB对他们来说是一个共享的磁盘存储,他们是如何处理Slave节点上缓存一致性的?这是另一个还未解决的有趣问题。
性能:
亚马逊承诺“Aurora性能是同等硬件条件下MySQL V5.6速度的五倍。”这听起来十分不错,但我们真的能看到实际的数字么?在特定平台运行测试的细节呢?大家都知道“可达到”是有一点回旋余地的。不幸的是,目前,Aurora是“有限预览,”所以我们都必须等待。
事务延迟:
如果需要多个“规定数量”的写操作和读操作(Slave节点)保持同步,Slave节点完全同步的延迟是多少?例如,如果应用程序是从Slave节点副本读取,然后Master节点被更新,这次事务是如何完成的?顾客添加一个电子商务网站上某个商品到购物车,一旦他们查询其购物车(例如,在Slave读操作节点上),他们可以选择更改所购商品数量或颜色。如果此时有customer2刚刚购买了某一个颜色的全部商品,customer1会话中是否会反映出***的可用数量?或者应用程序有个机制来处理此类问题。这些是电子商务网站部署要解决的关键问题。
总体而言,亚马逊的Aurora发布时给出了很多的承诺,比如“速度与高端数据库的可靠性,”但对于系统内部细节描述不多。具体来说,可能出现的各种延迟是否会影响到事务并发和应用程序的可用性?作为参考,NoSQL数据库可以提供惊人的速度和高可用性; 他们只需要'丢掉'事务支持,就能做到这一点。
Aurora是采用SQL语法的加强版NoSQL数据库引擎?或者它是一个具有完全ACID属性、兼容MPP事务和MVCC功能的NewSQL数据库引擎?
只有时间才能给我们答案,但至少可以肯定一点,那就是ClustrixDB是一个完全对ACID兼容,支持MVCC功能的数据库,在云计算的AWS,Rackspace和其他数百个全球实例上已经部署成功,每月处理万亿级的事务。